Analytics
Amazon Athena
Type: Serverless Interactive Query Service Description: Amazon Athena is a serverless query service that allows you to analyze data stored in Amazon S3 using standard SQL. With Athena, there is no need to manage infrastructure or perform complex ETL processes. It is ideal for running ad-hoc queries and gaining insights from large datasets quickly and cost-effectively.
Key Features
- Serverless Architecture:
- No infrastructure to manage; simply define the data and execute SQL queries.
- SQL Query Support:
- Use standard ANSI SQL for querying structured, semi-structured, and unstructured data.
- Supports Various Data Formats:
- Compatible with CSV, JSON, Parquet, ORC, Avro, and other popular data formats.
- Data Partitioning:
- Query specific partitions of data to improve query performance and reduce costs.
- Schema on Read:
- Define schemas when querying the data rather than during data ingestion, making it flexible for analyzing raw data.
- Integration with AWS Glue:
- Uses AWS Glue Data Catalog for metadata management and schema definitions.
- Scalable Query Processing:
- Automatically scales to handle complex and large queries.
- Pay-Per-Query Pricing:
- Billed based on the amount of data scanned by queries, encouraging optimization.
Subtypes and Components
- Query Execution Engine:
- Powered by Presto, an open-source distributed SQL query engine optimized for large-scale data analysis.
- Data Catalog Integration:
- Leverages AWS Glue Data Catalog to store metadata about tables and databases.
- Federated Query Support:
- Query data across various sources, including RDS, Redshift, or on-premises databases, without moving data.
- Partitioning and Compression:
- Supports partitioned and compressed datasets for enhanced performance.
Use Cases
- Ad-Hoc Data Analysis:
- Quickly analyze data in Amazon S3 without complex data pipelines.
- Log and Event Analysis:
- Query server logs, clickstream data, or application logs stored in S3.
- Data Exploration:
- Explore raw or semi-structured data for insights before loading into a data warehouse.
- Business Intelligence (BI):
- Integrate with tools like Amazon QuickSight for interactive reporting and dashboards.
- ETL Replacement:
- Simplify ETL workflows by directly querying data in its native format.
- Machine Learning Data Preparation:
- Prepare datasets for machine learning workflows by filtering and transforming data using SQL. Integration with AWS Services Integrated With:
- Amazon S3: Primary data storage for querying with Athena.
- AWS Glue: Provides the Data Catalog to manage metadata and table definitions.
- Amazon QuickSight: Enables visualization of Athena query results in interactive dashboards.
- Amazon CloudWatch Logs: Analyze logs stored in S3.
- AWS Lake Formation: Simplifies managing and securing data lakes queried by Athena. Not Directly Integrated With:
- RDS or Aurora: While Athena cannot natively query these databases, you can export their data to S3 for analysis.
- DynamoDB: Data must be exported to S3 or queried via federated queries using AWS Glue connectors.
Governance and Security
- Access Control:
- Manages access through IAM policies, ensuring users have the appropriate permissions for querying and managing resources.
- Encryption:
- Supports data encryption at rest (using S3 encryption) and in transit (using SSL/TLS).
- Query results can also be encrypted and stored in S3.
- Auditing and Logging:
- Integrated with AWS CloudTrail for logging query and access events.
- Data Privacy:
- Access control integrated with AWS Lake Formation to enforce granular security policies. Benefits
- No Infrastructure Management:
- Focus on querying data without worrying about provisioning or maintaining servers.
- Cost Efficiency:
- Pay only for the data scanned, and optimize costs by compressing, partitioning, and filtering data.
- Fast Query Execution:
- Presto-powered execution ensures low-latency querying for large datasets.
- Flexibility:
- Analyze various data formats, including structured and semi-structured, without transformation.
- Scalable:
- Automatically scales resources to match query demands, enabling high availability.
AWS Data Exchange
- Type: Data Sharing Service
- Description: Facilitates secure and efficient exchange of third-party data sets, enabling customers to subscribe to and use data products in the cloud.
- Use Cases:
- Accessing financial market data
- Integrating healthcare datasets
- Utilizing demographic and consumer data for analytics Additional Features:
- Subscriptions: Automated updates to subscribed datasets.
- Data API Access: Seamlessly retrieve data directly into analytics tools. Governance and Security:
- Control data access with IAM roles.
- Ensure compliance by subscribing only to verified providers. Examples:
- Leverage third-party weather data for logistics optimization.
AWS Data Pipeline
- Type: Data Workflow Orchestration
- Description: Automates the movement and transformation of data between different AWS services and on-premises data sources at specified intervals.
- Use Cases:
- Periodic ETL processes
- Data replication across services
- Data processing workflows
Amazon EMR (Elastic MapReduce)
- Type: Managed Big Data Framework
- Description: Provides a managed Hadoop framework to process vast amounts of data across resizable clusters of Amazon EC2 instances.
- Subtypes:
- Hadoop: Batch processing and distributed storage
- Spark: Real-time data analytics and machine learning
- Presto: Interactive SQL queries on large datasets
- Hive: Data warehousing and SQL-like querying
- HBase: NoSQL database for big data applications
- Use Cases:
- Large-scale data processing
- Log analysis
- Machine learning workloads Additional Features:
- Auto Scaling Clusters: Dynamically add or remove nodes based on workload.
- Custom AMIs: Use pre-configured images for specific analytics needs. Governance and Security:
- Encrypt data in transit with SSL and at rest using S3 encryption options.
- Monitor job execution via CloudWatch logs. Examples:
- Process petabytes of clickstream data for behavioral analysis.
AWS Glue
Type: Serverless ETL (Extract, Transform, Load) Service Description: AWS Glue is a fully managed ETL service that simplifies the process of extracting, transforming, and loading data for analytics. It automatically discovers and catalogs data, generates ETL code, and provides tools to clean and transform datasets for use in data lakes, warehouses, and machine learning workflows.
Key Features
- Serverless Architecture:
- No infrastructure management; AWS Glue scales automatically to meet workload demands.
- Data Catalog:
- Centralized metadata repository to store table definitions, schemas, and job runtime metrics.
- Compatible with AWS Lake Formation for enhanced governance and security.
- Built-In ETL Engine:
- Generates Python or Scala ETL scripts, which can be customized using an integrated development environment (IDE).
- Schema Discovery:
- Automatically detects and catalogs schema and format of data in various sources (e.g., S3, RDS, DynamoDB).
- Developer-Friendly:
- Supports PySpark for building ETL workflows and integrates with Jupyter Notebooks for interactive development.
- Job Scheduling:
- Allows scheduling and orchestrating ETL workflows, with dependency tracking and retries for failed jobs.
- Streaming ETL:
- Supports real-time data transformation for streaming data sources like Amazon Kinesis and Kafka.
- Integration with AWS Ecosystem:
- Works seamlessly with services like Amazon S3, Redshift, Athena, and more for end-to-end data processing.
- Data Preparation:
- AWS Glue DataBrew provides a visual interface for preparing and transforming data without writing code.
- Data Quality and Lineage:
- Track and audit the lineage of data transformations for compliance and debugging.
Subtypes and Components
- AWS Glue Data Catalog:
- Central repository for metadata that integrates with Amazon Athena, Redshift, and Lake Formation.
- ETL Jobs:
- Fully managed Spark-based jobs for transforming and moving data between sources and destinations.
- Glue Crawlers:
- Automatically crawl data sources to detect schema and store metadata in the Glue Data Catalog.
- AWS Glue DataBrew:
- Visual data preparation tool for cleaning and enriching data without code.
- AWS Glue Studio:
- Low-code interface to visually design and manage ETL workflows.
- Triggers and Workflows:
- Orchestrate complex ETL pipelines with event-based triggers and multi-step workflows.
- Glue Connectors:
- Pre-built connectors to integrate with on-premises and cloud-based data sources, including SaaS applications.
Use Cases
- Data Lakes:
- Create and manage data lakes by ingesting, cataloging, and transforming raw data for analysis.
- Data Warehousing:
- Load transformed data into Amazon Redshift for BI and reporting use cases.
- Real-Time Analytics:
- Stream and transform data from sources like Kinesis or Kafka for immediate insights.
- Machine Learning Preparation:
- Prepare and clean datasets for machine learning models in Amazon SageMaker or other platforms.
- Data Discovery:
- Automatically identify and catalog data from diverse sources for easy querying and exploration.
- Regulatory Compliance:
- Ensure data quality, lineage, and transformations for regulatory reporting and audits.
- Application Data Integration:
- Transform and integrate application data from databases, APIs, and other sources into a unified format.
Integration with AWS Services Integrated With:
- Amazon S3: Primary storage for raw and transformed data.
- Amazon Redshift: Load data into Redshift for data warehousing and analytics.
- Amazon Athena: Query cataloged data directly from the Glue Data Catalog.
- AWS Lake Formation: Enhanced security and governance for data lakes.
- Amazon DynamoDB: Transform and process DynamoDB tables.
- Amazon RDS and Aurora: Extract and transform data from relational databases.
- Amazon SageMaker: Prepare data for machine learning workflows.
- Amazon Kinesis and Kafka: Stream real-time data for transformation and storage. Not Integrated With:
- Standalone EC2 instances unless used with custom configurations to pull data into Glue-supported formats.
- On-premises systems without using Glue connectors or custom scripts.
Governance and Security
- IAM Policies:
- Use IAM roles to manage access to Glue resources and associated services like S3, DynamoDB, and Redshift.
- Encryption:
- Data can be encrypted at rest using AWS KMS and in transit using SSL/TLS.
- Auditing and Logging:
- Monitor Glue activities through AWS CloudTrail and detailed logs in CloudWatch.
- Data Governance:
- Integrated with AWS Lake Formation for managing fine-grained access control.
- Data Lineage:
- Trace the flow of data and transformations for compliance and debugging.
Benefits
- Ease of Use:
- Automates the tedious aspects of data preparation, freeing up developer time.
- Scalable:
- Handles large datasets with automatic scaling of resources.
- Cost-Effective:
- Pay-as-you-go pricing ensures costs scale with usage, making it affordable for varying workloads.
- Flexibility:
- Supports diverse data formats and integrates with a wide range of AWS services.
- Developer Productivity:
- Provides tools like Glue Studio and DataBrew to simplify ETL and data preparation.
- Real-Time Processing:
- Supports streaming data transformations for immediate use cases.
Amazon Kinesis
- Type: Real-Time Data Streaming
- Description: Enables real-time processing of streaming data at scale.
- Subtypes:
- Kinesis Data Streams: Real-time data ingestion
- Kinesis Data Firehose: Data delivery to destinations like S3, Redshift, and Elasticsearch
- Kinesis Data Analytics: Real-time data processing using SQL
- Use Cases:
- Real-time analytics
- Log and event data collection
- Streaming data pipelines
Additional Features:
- Data Retention: Keep data for up to 7 days for replay.
- Integration: Works seamlessly with Lambda, S3, and Redshift. Governance and Security:
- Control access to streams using IAM roles and resource policies.
- Encrypt data streams with KMS-managed keys. Examples:
- Real-time monitoring of social media trends.
AWS Lake Formation
- Type: Data Lake Management
- Description: Simplifies the process of building, securing, and managing data lakes, allowing for centralized storage and analysis of diverse data.
- Use Cases:
- Centralized data repository
- Data governance and security
- Simplified data ingestion and cataloging
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
- Type: Managed Kafka Service
- Description: Fully managed service that makes it easy to build and run applications that use Apache Kafka for streaming data.
- Use Cases:
- Real-time data streaming
- Event sourcing
- Log aggregation
Amazon OpenSearch Service (formerly Elasticsearch Service)
- Type: Managed Search and Analytics
- Description: Provides a managed service for deploying, operating, and scaling OpenSearch (and legacy Elasticsearch) clusters in the AWS Cloud.
- Use Cases:
- Log and event data analysis
- Full-text search
- Real-time application monitoring
Amazon QuickSight
- Type: Business Intelligence Tool
- Description: Cloud-powered business analytics service that makes it easy to deliver insights to everyone in your organization.
- Use Cases:
- Interactive dashboards
- Ad-hoc analysis
- Embedded analytics
Amazon Redshift
- Type: Data Warehousing
- Description: Fully managed, petabyte-scale data warehouse service in the cloud.
- Use Cases:
- Complex query processing
- Business intelligence
- Data warehousing Additional Features:
- Materialized Views: Speed up queries by precomputing results.
- Spectrum: Query S3 data without loading it into Redshift. Governance and Security:
- Use role-based access controls (RBAC) for granular permissions.
- Audit access with CloudTrail integration. Examples:
- Perform complex OLAP queries for e-commerce reporting.
Application Integration
Amazon AppFlow
- Type: SaaS Integration
- Description: Enables secure data transfer between AWS services and SaaS applications like Salesforce, ServiceNow, and others without writing custom code.
- Use Cases:
- Data synchronization between SaaS and AWS
- Automated data workflows
- Integrating third-party applications with AWS services
Additional Features:
- Data Filtering: Transfer only necessary records using filters.
- Custom Mappings: Map source fields to destination fields. Governance and Security:
- Encrypt data in transit and at rest.
- Use private links to transfer data securely without internet exposure. Examples:
- Sync Salesforce contacts to S3 for advanced analytics.
AWS AppSync
- Type: Managed GraphQL Service
- Description: Simplifies application development by providing a flexible API to securely access, manipulate, and combine data from multiple sources.
- Use Cases:
- Real-time applications
- Offline data access
- Mobile and web application backends Additional Features:
- Express Workflows: Ideal for high-frequency, short-duration processes.
- Visual Workflow Designer: Drag-and-drop UI to simplify workflow creation. Governance and Security:
- Secure workflows with IAM role-based access.
- Monitor executions with CloudWatch Logs. Examples:
- Automate multi-step approval processes.
Amazon EventBridge
- Type: Serverless Event Bus
- Description: Amazon EventBridge is a serverless event bus service that allows you to connect your applications with event data from various AWS services, third-party SaaS applications, or custom sources. EventBridge enables event-driven architectures by facilitating real-time data transfer and triggering actions across systems without the need for manual integration or polling mechanisms. Key Features
- Event Bus:
- Centralized event routing system for handling events from AWS services, third-party SaaS applications, and custom event sources.
- Event Filtering:
- Apply rules to filter and process events based on defined patterns, enabling targeted actions.
- Event Archiving and Replay:
- Automatically archives events for later reprocessing or troubleshooting.
- Schema Registry:
- Central repository for managing and discovering event schemas, supporting schema versioning and validation.
- Cross-Account Event Sharing:
- Share events across multiple AWS accounts securely using resource policies.
- Third-Party Integration:
- Native integration with SaaS applications like Zendesk, Shopify, and Datadog.
- Custom Event Sources:
- Publish custom application events directly to EventBridge for further processing.
- Scalability:
- Automatically scales to handle millions of events per second.
- Low Latency:
- Processes and delivers events in near real-time, ensuring timely execution of workflows.
Components
-
Event Bus:
-
Default Bus: Captures events from AWS services by default.
-
Custom Bus: Allows for segregating event sources for different applications or services.
-
Partner Bus: Integrates with supported SaaS applications.
-
Rules:
-
Define how events are processed and routed to one or more targets.
-
Targets:
-
Services or resources that receive the events, such as Lambda, SQS, SNS, Step Functions, or Kinesis.
-
Schema Registry:
-
Stores event schemas and enables event schema discovery for producers and consumers.
-
Event Archive:
-
Retains events for replay or debugging with configurable retention policies.
-
Use Cases:
-
Application integration
-
Real-time data processing
-
Event-driven workflows Integration with AWS Services Integrated With:
-
AWS Lambda: Trigger serverless functions for event-driven processing.
-
Amazon SQS: Queue events for asynchronous processing.
-
Amazon SNS: Distribute notifications or trigger downstream actions.
-
AWS Step Functions: Orchestrate workflows triggered by events.
-
Amazon Kinesis: Process real-time data streams for analytics.
-
Amazon ECS/EKS: Launch tasks or pods in response to events.
-
AWS CloudWatch Logs: Generate events based on log patterns for monitoring and automation.
-
Amazon API Gateway: Route external events to EventBridge for processing.
-
AWS Glue: Trigger ETL workflows upon data updates. Not Directly Integrated With:
-
Standalone databases like RDS or DynamoDB unless events are routed through another trigger like Lambda or DynamoDB Streams.
Amazon MQ
- Type: Managed Message Broker Service
- Description: Provides a managed message broker service for Apache ActiveMQ and RabbitMQ, facilitating the migration of messaging workloads to AWS.
- Use Cases:
- Messaging between distributed systems
- Application decoupling
- Legacy application integration
Amazon Simple Notification Service (SNS)
- Type: Pub/Sub Messaging Service
- Description: Fully managed messaging service for both application-to-application (A2A) and application-to-person (A2P) communication.
- Use Cases:
- Sending notifications
- Fan-out message delivery
- Event-driven computing
Amazon Simple Queue Service (SQS)
Type: Managed Message Queue Service Description: Amazon SQS is a fully managed message queuing service that enables decoupling and scaling of distributed systems, microservices, and serverless applications. It allows asynchronous communication between application components by securely transmitting messages via queues, ensuring reliable and scalable operations.
Key Features
- Message Queues:
- Store messages in a queue for processing by consumers, enabling asynchronous communication.
- Two Queue Types:
- Standard Queue: Provides at-least-once message delivery and best-effort ordering.
- FIFO Queue (First-In-First-Out): Ensures exactly-once processing and message order consistency.
- Scalability:
- Scales automatically to handle high-throughput workloads.
- Serverless Architecture:
- Fully managed with no infrastructure to provision or manage.
- Message Retention:
- Messages can be retained for up to 14 days.
- Dead-Letter Queues (DLQs):
- Store undeliverable messages for troubleshooting.
- Message Visibility Timeout:
- Prevents messages from being processed multiple times by hiding them from other consumers during processing.
- Delay Queues:
- Delay delivery of messages by a specified duration.
- Long Polling:
- Reduce empty responses by waiting for messages to be available in the queue.
- Encryption:
- Supports encryption at rest using AWS Key Management Service (AWS KMS).
Components
- Producers:
- Applications or services that send messages to SQS queues.
- Queue:
- Stores messages temporarily until consumed.
- Consumers:
- Applications or services that retrieve and process messages from the queue.
- Dead-Letter Queue (DLQ):
- Configurable queue for storing failed messages.
- Attributes:
- Metadata associated with each queue or message, such as retention period, visibility timeout, or delay duration.
Queue Types
- Standard Queue:
- High throughput and low latency.
- At-least-once delivery with potential duplication of messages.
- Best-effort ordering (not guaranteed).
- FIFO Queue:
- Exactly-once delivery.
- Preserves the order of message processing.
- Limited throughput compared to standard queues (300 transactions per second with batching, or 3000 with high-throughput mode).
Use Cases
- Decoupling Microservices:
- Ensure independent scalability and failure isolation between application components.
- Load Leveling:
- Buffer requests during high traffic to ensure backend systems process them at a steady pace.
- Serverless Applications:
- Trigger AWS Lambda functions to process messages in SQS.
- Job Queues:
- Manage long-running tasks or background jobs asynchronously.
- Message Offloading:
- Offload temporary or bulk messages for later processing.
- Batch Processing:
- Combine multiple messages for efficient consumption and processing.
- Event-Driven Architectures:
- Trigger downstream workflows based on event-driven messages.
- Dead-Letter Handling:
- Troubleshoot and manage failed message deliveries using DLQs.
Integration with AWS Services Integrated With:
- AWS Lambda: Trigger Lambda functions for event-driven processing.
- Amazon SNS: Fan-out messages to multiple SQS queues for parallel processing.
- Amazon EC2: Process messages in distributed systems running on EC2 instances.
- AWS Step Functions: Orchestrate workflows that include SQS as a task.
- AWS KMS: Encrypt messages at rest for enhanced security.
- Amazon CloudWatch: Monitor queue metrics and set alarms for visibility and debugging.
- AWS IAM: Control access and permissions for producers and consumers. Not Directly Integrated With:
- Direct database triggers without intermediary services like Lambda or custom scripts.
Governance and Security
- IAM Policies:
- Manage fine-grained access to queues for producers and consumers.
- Encryption:
- Use AWS KMS for encryption at rest.
- Messages in transit are encrypted using SSL/TLS.
- Auditing:
- Log message activity and access through AWS CloudTrail.
- Visibility Timeout:
- Prevent multiple consumers from processing the same message.
- Dead-Letter Queues (DLQs):
- Isolate and debug failed messages for improved reliability.
Benefits
- Fully Managed:
- Offload operational overhead of managing message queues.
- Scalability:
- Automatically scales to accommodate any workload size.
- Reliability:
- High availability and durability with at-least-once message delivery.
- Cost-Effective:
- Pay-per-use pricing ensures costs scale with usage.
- Flexibility:
- Supports both standard and FIFO queues for diverse use cases.
- Ease of Integration:
- Seamless integration with AWS services and APIs for custom workflows.
- Operational Resilience:
- Buffering mechanisms help absorb traffic spikes without service disruption.
AWS Step Functions
- Type: Serverless Orchestration Service
- Description: Enables the coordination of multiple AWS services into serverless workflows, simplifying the development and execution of multi-step applications.
- Use Cases:
- Building data processing pipelines
- Orchestrating microservices
- Automating IT and business processes
AWS Cost Management
AWS Cost and Usage Report
- Type: Billing and Usage Analytics
- Description: Provides the most detailed information about AWS usage and costs, delivered to an S3 bucket.
- Use Cases:
- Deep cost analysis
- Custom billing reports
- Integration with analytics tools like Amazon Athena or Amazon Redshift
AWS Cost Explorer
- Type: Cost Visualization Tool
- Description: Allows users to visualize, understand, and manage AWS costs and usage over time.
- Use Cases:
- Cost trend analysis
- Budget forecasting
- Cost optimization insights Additional Features:
- Savings Plans Recommendations: Optimize compute costs with custom recommendations.
- Tag-Based Filtering: Analyze costs by department or project. Governance and Security:
- Restrict access to billing data with IAM policies. Examples:
- Forecast costs for the next billing cycle to ensure budget adherence.
Savings Plans
- Type: Flexible Pricing Model
- Description: Offers significant savings over On-Demand pricing in exchange for a commitment to use a specific amount of compute power over one or three years.
- Use Cases:
- Cost savings for predictable workloads
- Optimizing compute costs
- Running EC2, Fargate, and Lambda workloads
Compute
AWS Batch
- Type: Batch Processing Service
- Description: Efficiently runs hundreds to thousands of batch computing jobs by dynamically provisioning the optimal quantity and type of compute resources.
- Use Cases:
- High-throughput data processing
- Scientific simulations
- Media transcoding
Amazon EC2 (Elastic Compute Cloud)
- Type: Scalable Virtual Servers
- Subtypes:
- On-Demand Instances: Pay-as-you-go pricing for short-term needs.
- Spot Instances: Cost-effective for non-critical workloads.
- Reserved Instances: Lower pricing for committed usage.
- Savings Plan Instances: Flexible commitment-based pricing.
- Use Cases:
- Hosting applications and websites
- Running large-scale distributed systems
- Machine learning model training
Amazon EC2 Auto Scaling
- Type: Dynamic Scaling
- Description: Automatically adjusts the number of EC2 instances based on demand.
- Use Cases:
- Maintaining application availability
- Cost optimization by scaling down during low usage
AWS Elastic Beanstalk
- Type: PaaS (Platform as a Service)
- Description: Simplifies deployment and management of applications by automatically handling capacity provisioning, load balancing, and scaling.
- Use Cases:
- Deploying web applications
- Auto-scaling applications
- Rapid environment setup for developers
AWS Outposts
- Type: Hybrid Cloud Service
- Description: Extends AWS services to on-premises data centers.
- Use Cases:
- Low-latency applications
- Hybrid cloud architectures
- On-premises data processing
AWS Serverless Application Repository
- Type: Repository for Serverless Applications
- Description: Enables users to discover, deploy, and share serverless applications.
- Use Cases:
- Quickly deploying prebuilt serverless applications
- Sharing serverless solutions across teams
- Accelerating development
VMware Cloud on AWS
- Type: Hybrid Cloud Integration
- Description: Enables migration and extension of on-premises VMware environments to AWS.
- Use Cases:
- Seamless migration to the cloud
- Hybrid cloud deployments
- Disaster recovery for VMware workloads
AWS Wavelength
- Type: Edge Computing Service
- Description: Enables developers to build applications that deliver ultra-low latency to 5G devices and edge computing workloads.
- Use Cases:
- Real-time gaming
- IoT applications
- AR/VR experiences
Containers
Amazon Elastic Container Service (ECS)
- Type: Managed Container Orchestration
- Subtypes:
- ECS Anywhere: Extends ECS to on-premises environments.
- Use Cases:
- Running containerized microservices
- Deploying applications across hybrid environments
- Managing containers without Kubernetes
Amazon Elastic Kubernetes Service (EKS)
- Type: Managed Kubernetes Service
- Subtypes:
- EKS Anywhere: Kubernetes on-premises with AWS management.
- EKS Distro: Open-source distribution of Kubernetes.
- Use Cases:
- Deploying and managing Kubernetes clusters
- Running highly scalable containerized workloads
- Hybrid Kubernetes deployments
Amazon Elastic Container Registry (ECR)
- Type: Container Registry
- Description: Provides a secure, scalable, and reliable registry for storing Docker images.
- Use Cases:
- Storing and managing container images
- Integrating with ECS and EKS
- Simplified deployment of containerized applications
Database Services Cheat Sheet
Amazon Aurora
- Type: Managed Relational Database
- Description: High-performance, fully managed relational database compatible with MySQL and PostgreSQL.
- Features:
- Distributed, fault-tolerant storage.
- Automatic backups and failover.
- Global Database for low-latency reads across regions.
- Use Cases:
- High-throughput online transaction processing (OLTP).
- Enterprise applications requiring high availability.
- E-commerce platforms and SaaS applications.
Amazon Aurora Serverless
- Type: Auto-Scaling Relational Database
- Description: Serverless version of Aurora that scales automatically based on demand.
- Features:
- Pay-per-use pricing.
- Automatic scaling to handle workload spikes.
- Compatible with MySQL and PostgreSQL.
- Use Cases:
- Applications with unpredictable traffic patterns.
- Development and testing environments.
- Cost-optimized, low-maintenance workloads.
Amazon DocumentDB (with MongoDB compatibility)
- Type: NoSQL Document Database
- Description: Managed database service designed to run MongoDB workloads.
- Features:
- Scalability with replicas and sharding.
- Fully managed backups and patching.
- High availability with multi-AZ deployments.
- Use Cases:
- Content management systems.
- Cataloging and inventory applications.
- Storing hierarchical or semi-structured data.
Amazon DynamoDB
- Type: NoSQL Key-Value and Document Database
- Description: Fully managed, serverless NoSQL database for low-latency applications.
- Features:
- Single-digit millisecond response times.
- On-demand or provisioned capacity modes.
- Global Tables for multi-region replication.
- Use Cases:
- Real-time applications (e.g., gaming leaderboards).
- IoT data storage.
- Shopping cart and session management.
Additional Features:
- Streams: Capture item-level changes for event-driven applications.
- Global Tables: Multi-region replication for low-latency global access. Governance and Security:
- Define fine-grained access controls with IAM policies.
- Monitor table activity using CloudWatch Metrics. Examples:
- Power real-time leaderboards for online games.
Amazon ElastiCache
- Type: In-Memory Data Store
- Description: Fully managed in-memory data store compatible with Redis and Memcached.
- Subtypes:
- Redis: Advanced in-memory data structure store with support for replication and persistence.
- Memcached: Simple key-value store for caching.
- Use Cases:
- Real-time caching for high-throughput applications.
- Session storage for web applications.
- Gaming leaderboards and real-time analytics.
Amazon Keyspaces (for Apache Cassandra)
- Type: Managed NoSQL Database
- Description: Fully managed database service compatible with Apache Cassandra.
- Features:
- Scalable and highly available.
- Serverless and zero-maintenance.
- Compatible with Cassandra Query Language (CQL).
- Use Cases:
- IoT applications requiring high throughput.
- Time-series data storage.
- Decentralized data models.
Amazon Neptune
- Type: Graph Database
- Description: Fully managed graph database for storing and navigating relationships.
- Features:
- Supports both property graph and RDF graph models.
- Optimized for high-performance graph queries.
- High availability with automated failover.
- Use Cases:
- Social networking applications.
- Fraud detection through relationship analysis.
- Knowledge graphs and recommendation engines.
Amazon Quantum Ledger Database (QLDB)
- Type: Immutable Ledger Database
- Description: Fully managed ledger database providing a transparent, immutable, and cryptographically verifiable transaction log.
- Features:
- Append-only, cryptographically chained data structure.
- Managed service with no server provisioning required.
- ACID-compliant transactions.
- Use Cases:
- Financial transaction tracking.
- Supply chain management.
- Identity verification and compliance systems.
Amazon RDS (Relational Database Service)
- Type: Managed Relational Database
- Description: Simplifies the setup, operation, and scaling of relational databases.
- Supported Engines:
- MySQL
- PostgreSQL
- MariaDB
- Oracle
- SQL Server
- Features:
- Automated backups and software patching.
- Multi-AZ deployments for high availability.
- Read replicas for improved performance.
- Use Cases:
- Hosting transactional databases.
- Enterprise applications requiring relational data storage.
- E-commerce platforms and CMS applications.
Amazon Redshift
- Type: Data Warehousing Service
- Description: Fully managed, petabyte-scale data warehouse for analyzing structured and semi-structured data.
- Features:
- Columnar storage for high-performance analytics.
- Integration with BI tools like QuickSight.
- Redshift Spectrum for querying S3 data without ETL.
- Use Cases:
- Business intelligence and reporting.
- Analyzing large datasets from IoT or transactional systems.
- Preparing data for machine learning.
Comparison of Database Services Service Best For Amazon Aurora High-performance relational workloads. Aurora Serverless Unpredictable or intermittent traffic patterns. Amazon DocumentDB MongoDB-compatible document database. Amazon DynamoDB Low-latency key-value and document storage. Amazon ElastiCache Real-time caching and in-memory data stores. Amazon Keyspaces Cassandra-compatible workloads for time-series or IoT data. Amazon Neptune Graph-based applications for relationship analysis. Amazon QLDB Immutable ledger use cases like transaction tracking. Amazon RDS Relational databases with multiple engine options. Amazon Redshift Analytical queries on large datasets for business intelligence.
Developer Tools
AWS X-Ray
- Type: Distributed Tracing Service
- Description: Helps developers analyze and debug distributed applications, providing insights into performance and identifying bottlenecks.
- Use Cases:
- Debugging serverless and microservices applications.
- Identifying latency issues in distributed systems.
- Monitoring end-to-end application performance.
Front-End Web and Mobile
AWS Amplify
- Type: Front-End Development Framework
- Description: Provides tools and services to build scalable, secure mobile and web applications.
- Use Cases:
- Hosting single-page applications.
- Simplifying backend integrations.
- Rapid prototyping and deployment.
Amazon API Gateway
- Type: Managed API Gateway
- Description: Enables developers to create, publish, maintain, and secure APIs.
- Use Cases:
- Creating RESTful APIs.
- Managing WebSocket APIs.
- Enabling serverless architectures with AWS Lambda. Additional Features:
- Usage Plans: Control API access with rate limiting and quotas.
- WebSocket Support: Enable real-time, two-way communication. Governance and Security:
- Implement authorization with IAM, Lambda authorizers, or Cognito.
- Use WAF for additional protection against threats. Examples:
- Build serverless APIs for mobile applications.
AWS Device Farm
- Type: Mobile App Testing Service
- Description: Tests mobile and web apps on real devices hosted in the AWS cloud.
- Use Cases:
- Cross-platform application testing.
- Identifying bugs in different OS environments.
- Automated testing for mobile applications.
Amazon Pinpoint
- Type: Customer Engagement Service
- Description: Helps businesses engage with customers via targeted messaging campaigns.
- Use Cases:
- Marketing automation.
- User retention campaigns.
- Analyzing customer behavior.
Machine Learning
Amazon Comprehend
- Type: Natural Language Processing (NLP)
- Description: Extracts insights from text, such as sentiment, key phrases, entities, and more.
- Use Cases:
- Analyzing customer feedback.
- Text classification for document processing.
- Social media sentiment analysis.
Amazon Forecast
- Type: Time-Series Forecasting Service
- Description: Uses machine learning to generate accurate forecasts for business metrics.
- Use Cases:
- Inventory planning.
- Financial forecasting.
- Resource demand predictions.
Amazon Fraud Detector
- Type: Fraud Detection Service
- Description: Identifies potentially fraudulent online activities using machine learning.
- Use Cases:
- Preventing payment fraud.
- Reducing fake account registrations.
- Monitoring transaction anomalies.
Amazon Kendra
- Type: Enterprise Search Service
- Description: Provides intelligent search capabilities for internal documents and datasets.
- Use Cases:
- Knowledge management.
- Internal document search.
- Enhancing customer support tools.
Amazon Lex
- Type: Conversational AI Service
- Description: Builds conversational interfaces using automatic speech recognition (ASR) and natural language understanding (NLU).
- Use Cases:
- Building chatbots.
- IVR systems for customer support.
- Real-time conversational applications.
Amazon Polly
- Type: Text-to-Speech Service
- Description: Converts text into lifelike speech using deep learning.
- Use Cases:
- Content accessibility for visually impaired users.
- Automating audio for news and articles.
- Building voice-enabled applications.
Amazon Rekognition
- Type: Image and Video Analysis
- Description: Provides image and video recognition capabilities, including facial recognition and object detection.
- Use Cases:
- Content moderation for images/videos.
- Real-time facial recognition in security systems.
- Image metadata extraction.
Amazon SageMaker
- Type: Machine Learning Development Platform
- Description: Helps build, train, and deploy machine learning models at scale.
- Use Cases:
- Custom machine learning model development.
- Real-time model inference.
- Automated ML pipeline creation. Additional Features:
- Autopilot: Automatically build, train, and tune ML models.
- Studio: Fully integrated development environment for ML workflows. Governance and Security:
- Encrypt ML models and datasets.
- Secure endpoints with VPC configurations. Examples:
- Predict customer churn using structured customer data.
Amazon Textract
- Type: Document Text Extraction
- Description: Automatically extracts text, forms, and tables from scanned documents.
- Use Cases:
- Invoice and receipt processing.
- Document digitization.
- Automating data entry workflows.
Amazon Transcribe
- Type: Speech-to-Text Service
- Description: Converts speech into text using machine learning.
- Use Cases:
- Transcribing customer calls.
- Real-time speech analytics.
- Captioning for videos.
Amazon Translate
- Type: Language Translation Service
- Description: Provides neural machine translation for 75+ languages.
- Use Cases:
- Localizing content for global audiences.
- Real-time translation in communication apps.
- Automating multilingual customer support.
Management and Governance Cheat Sheet
AWS Auto Scaling
- Type: Resource Scaling Service
- Description: Automatically adjusts resource capacity to maintain performance and minimize costs.
- Use Cases:
- Scaling EC2 instances based on demand.
- Scaling DynamoDB read/write capacity.
- Scaling ECS tasks for containerized applications.
AWS CloudFormation
- Type: Infrastructure as Code
- Description: Automates resource provisioning and management using JSON or YAML templates.
- Use Cases:
- Deploying consistent environments across accounts and regions.
- Version-controlling infrastructure changes.
- Managing complex multi-service deployments.
AWS CloudTrail
- Type: Logging Service
- Description: Records API calls and activity made on AWS services.
- Use Cases:
- Security auditing.
- Compliance monitoring.
- Troubleshooting operational issues.
Amazon CloudWatch
- Type: Monitoring and Observability
- Description: Collects and monitors logs, metrics, and events for AWS resources and applications.
- Features:
- Metrics: Monitor resource usage (e.g., CPU, memory).
- Alarms: Trigger actions based on thresholds.
- Logs: Aggregate and analyze application and system logs.
- CloudWatch Events: Automate responses to system changes.
- Use Cases:
- Monitoring EC2 instance performance.
- Setting alerts for resource thresholds.
- Visualizing operational metrics.
AWS Command Line Interface (AWS CLI)
- Type: Command-Line Tool
- Description: Unified tool to manage AWS services from the terminal.
- Use Cases:
- Automating repetitive tasks.
- Scripting deployments and operations.
- Querying AWS resources programmatically.
AWS Compute Optimizer
- Type: Cost and Performance Optimization
- Description: Provides recommendations to optimize AWS resources for cost and performance.
- Use Cases:
- Right-sizing EC2 instances.
- Optimizing Lambda function configurations.
- Balancing cost and performance for resource usage.
AWS Config
- Type: Configuration Management
- Description: Tracks and evaluates AWS resource configurations for compliance.
- Features:
- Configuration History: Records changes in resource configurations.
- Rules: Define compliance policies.
- Remediation: Automatically fixes non-compliant resources.
- Use Cases:
- Ensuring compliance with organizational policies.
- Auditing resource configurations.
- Detecting and fixing misconfigurations.
AWS Control Tower
- Type: Multi-Account Governance
- Description: AWS Control Tower simplifies the setup, governance, and management of multi-account AWS environments by implementing AWS best practices. It provides a pre-configured landing zone with governance controls (guardrails) to ensure security and compliance across accounts.
- Use Cases:
- Setting up multi-account environments.
- Enforcing security and compliance policies.
- Centralized account governance. Key Features:
- Landing Zone:
- Pre-configured multi-account environment based on AWS best practices.
- Includes logging, security accounts, and predefined network setups.
- Guardrails:
- Preventive Guardrails: Actively block non-compliant actions, such as creating resources in unauthorized regions.
- Detective Guardrails: Continuously monitor and flag non-compliance, such as unencrypted storage.
- Service Control Policies (SCPs):
- Apply policies across organizational units (OUs) to restrict specific actions.
- Examples: Prevent IAM policy changes, deny access to certain AWS regions.
- Account Factory:
- Automates account creation with predefined templates for networking, security, and compliance.
- Supports customization of VPC, IAM roles, and other baseline settings.
- Audit and Logging:
- Centralized logging through AWS CloudTrail and AWS Config for compliance tracking.
- Includes an audit account for governance and analysis.
- Dashboard:
- Provides a unified view of all accounts, compliance status, and resources.
- Simplifies operational insights and alerts. Governance and Security:
- Integrated Services:
- AWS Organizations: Manages multi-account structure and applies SCPs.
- AWS IAM Identity Center (SSO): Manages secure and centralized user access.
- AWS Config: Tracks resource configurations and ensures compliance with guardrails.
- CloudTrail: Provides detailed logging of account activities.
- Centralized Policy Enforcement:
- Use SCPs to restrict unauthorized actions across accounts.
- Monitor compliance through detective guardrails and Config rules.
- Custom Guardrails:
- Define additional preventive or detective controls using Config or custom Lambda functions.
- Example: Ensure EC2 instances do not use public IP addresses.
- Encryption and Access Control:
- Enforce encryption standards across accounts using SCPs and guardrails.
- Use fine-grained access controls to restrict sensitive actions.
Integrations:
- Security Tools:
- Integrates with GuardDuty, AWS Security Hub, and Amazon Macie for enhanced security monitoring.
- Flags anomalies and potential threats across accounts.
- Cost Management Tools:
- AWS Cost Explorer and AWS Budgets integration for tracking and managing account expenditures.
- Networking:
- Integrates with AWS Transit Gateway to streamline inter-account connectivity.
AWS Health Dashboard
- Type: Service Health Monitoring
- Description: Provides personalized information about AWS service disruptions and planned maintenance.
- Use Cases:
- Monitoring AWS service health.
- Proactive incident management.
- Receiving notifications for service events impacting your resources.
AWS License Manager
- Type: License Management Service
- Description: Simplifies the management of software licenses across AWS and on-premises environments.
- Use Cases:
- Tracking license usage for compliance.
- Managing bring-your-own-license (BYOL) workloads.
- Centralized license administration.
Amazon Managed Grafana
- Type: Visualization and Monitoring
- Description: Fully managed service for Grafana dashboards.
- Use Cases:
- Monitoring infrastructure metrics.
- Visualizing operational data.
- Integrating with CloudWatch, Prometheus, and more.
Amazon Managed Service for Prometheus
- Type: Managed Monitoring Service
- Description: Fully managed service for monitoring and alerting using Prometheus.
- Use Cases:
- Kubernetes metrics monitoring.
- Application performance monitoring.
- Centralizing metrics for large-scale systems.
AWS Management Console
- Type: Web-Based User Interface
- Description: A GUI for accessing and managing AWS services.
- Use Cases:
- Resource creation and management.
- Monitoring and troubleshooting.
- User-friendly interface for non-technical users.
AWS Organizations
- Type: Multi-Account Management
- Description: AWS Organizations simplifies the management of multiple AWS accounts by providing centralized control over policies, billing, and resource sharing. It enables organizations to enforce governance, streamline account creation, and optimize costs. Key Features:
- Service Control Policies (SCPs):
- Enforce fine-grained permissions across accounts or organizational units (OUs).
- Examples: Restrict access to specific regions or services.
- Organizational Units (OUs):
- Group accounts by function, project, or environment for better management.
- Apply SCPs at the OU level for consistent governance.
- Consolidated Billing:
- Combine all accounts under a single payment method for simplified billing and cost tracking.
- Enable cost allocation tags for detailed expense analysis.
- Resource Sharing:
- Share resources like VPCs, Transit Gateways, and license configurations across accounts securely.
- Account Management:
- Simplify the creation and management of AWS accounts with predefined configurations. Governance and Security:
- Enforce least privilege access across accounts with SCPs.
- Monitor account activity and compliance through CloudTrail and AWS Config.
- Secure inter-account communication with AWS PrivateLink and Resource Access Manager (RAM).
Use Cases:
- Centralized Policy Management:
- Enforce compliance by applying SCPs to OUs for consistent governance across accounts.
- Cost Optimization:
- Use consolidated billing to track and reduce costs across the organization.
- Resource Sharing:
- Share VPCs and other resources efficiently across accounts for centralized management.
- Scaling Operations:
- Create and manage new accounts easily while inheriting organizational policies.
Benefits:
- Centralized Governance: Manage accounts and policies from a single location.
- Cost Efficiency: Consolidate billing and streamline cost tracking.
- Simplified Resource Sharing: Securely share resources without duplicating efforts.
- Scalability: Scale cloud operations while maintaining consistent control.
AWS Proton
- Type: Application Delivery Automation
- Description: Automates the deployment and management of container and serverless applications.
- Use Cases:
- Standardizing infrastructure and deployment.
- Managing microservices at scale.
- Simplifying developer workflows.
AWS Service Catalog
- Type: Service Deployment Management
- Description: AWS Service Catalog enables organizations to centrally manage and distribute approved IT services and applications. It simplifies governance by creating a catalog of pre-approved resources, ensuring consistency and compliance across deployments.
Key Features:
- Portfolio Management:
- Organize and manage a collection of approved resources, including EC2 instances, RDS databases, and S3 buckets.
- Define permissions for users and groups to access specific portfolios.
- Product Management:
- Create products using AWS CloudFormation templates to standardize resource provisioning.
- Version control allows easy updates and rollbacks.
- Tagging and Tracking:
- Enforce tagging policies for cost allocation and resource management.
- Track usage of provisioned products across accounts.
- Access Control:
- Granular permissions to restrict who can view, deploy, and manage resources.
- Self-Service Portal:
- Empower users to deploy resources themselves from the catalog while adhering to governance policies.
Governance and Security:
- Compliance: Enforce organizational policies by distributing pre-approved configurations only.
- Audit and Tracking: Monitor deployments with CloudTrail and AWS Config.
- IAM Integration: Manage permissions to portfolios and products securely.
- Cost Control: Prevent over-provisioning by restricting resource specifications in templates.
Use Cases:
- Standardized Resource Deployment:
- Ensure consistent configurations for commonly used resources like VMs or databases.
- Cost Management:
- Restrict access to resource types or sizes that exceed budget constraints.
- Governed Self-Service:
- Allow teams to provision resources independently while adhering to security and compliance standards.
- Multi-Account Resource Sharing:
- Distribute resources across accounts in AWS Organizations. Benefits:
- Streamlined Management: Simplify resource deployment and updates through centralized catalogs.
- Enhanced Compliance: Ensure only approved configurations are deployed.
- Operational Efficiency: Empower teams with self-service capabilities while maintaining governance.
- Cost Optimization: Reduce waste through controlled provisioning.
AWS Systems Manager
- Type: Operations Management
- Description: AWS Systems Manager provides a unified interface for managing AWS resources and on-premises infrastructure. It simplifies operational tasks such as automation, patch management, and monitoring, while enhancing security and compliance across environments.
Key Features:
- Session Manager:
- Provides secure shell access to EC2 instances without needing bastion hosts or SSH keys.
- Integrated logging for audit and compliance.
- Automation:
- Automates repetitive tasks like instance provisioning and configuration management using pre-built or custom runbooks.
- Patch Manager:
- Automates patching for operating systems and applications across instances.
- State Manager:
- Ensures desired configurations are applied and maintained on instances.
- Parameter Store:
- Securely store, manage, and retrieve configuration data and secrets for your applications.
- Run Command:
- Execute commands on multiple instances without needing to log in.
- Inventory:
- Collect and view metadata about instances and software installed across environments.
- OpsCenter:
- Centralized dashboard for tracking and managing operational issues.
Governance and Security:
- Access Control: Manage permissions with AWS Identity and Access Management (IAM).
- Audit Trails: Use AWS CloudTrail to log all actions taken via Systems Manager.
- Encryption: Securely store sensitive data in Parameter Store using AWS Key Management Service (KMS).
- Compliance Tracking: Integrates with AWS Config to ensure resources meet compliance requirements.
Use Cases:
- Unified Operations Management:
- Centralize operational tasks across AWS and on-premises infrastructure.
- Patch Automation:
- Ensure all instances remain up-to-date with minimal manual intervention.
- Configuration Management:
- Automatically apply and enforce desired instance configurations.
- Secure Access Management:
- Provide auditable access to instances without requiring open ports or bastion hosts.
- Incident Response:
- Use Automation and OpsCenter for faster diagnosis and resolution of operational issues. Benefits:
- Enhanced Efficiency: Streamline routine operational tasks through automation.
- Improved Security: Secure access to instances and sensitive configurations.
- Cost Savings: Reduce operational overhead with centralized tools and automation.
- Compliance Simplification: Easily monitor and enforce compliance across environments.
AWS Trusted Advisor
- Type: Resource Optimization Tool
- Description: Provides recommendations for cost optimization, security, fault tolerance, performance, and service limits.
- Use Cases:
- Identifying cost-saving opportunities.
- Enhancing security configurations.
- Optimizing AWS resource usage.
AWS Well-Architected Tool
- Type: Architecture Assessment Tool
- Description: Helps assess workloads and implement best practices using the AWS Well-Architected Framework.
- Use Cases:
- Reviewing workloads for compliance with best practices.
- Identifying potential architectural risks.
- Improving operational efficiency.
Comparison of Management and Governance Services Service Best For AWS Auto Scaling Scaling resources dynamically. AWS CloudFormation Automating resource provisioning. AWS CloudTrail Tracking API activity and compliance. Amazon CloudWatch Monitoring resources and setting alerts. AWS Config Ensuring compliance and tracking changes. AWS Control Tower Managing multi-account environments. AWS Organizations Centralizing account management. AWS Systems Manager Unified operational insights and tasks. AWS Trusted Advisor Resource optimization and best practices.
Media Services
Amazon Elastic Transcoder
- Type: Media Transcoding Service
- Description: Converts media files into formats optimized for playback on devices.
- Use Cases:
- Video format conversion.
- Streaming optimization.
- Content delivery for mobile users.
Amazon Kinesis Video Streams
- Type: Video Streaming
- Description: Processes and analyzes streaming video data in real time.
- Use Cases:
- Real-time video analytics.
- Video archiving and playback.
- Machine learning for video analysis.
Migration and Transfer
AWS DataSync
Type: Data Transfer Automation Service Description: AWS DataSync simplifies, automates, and accelerates the process of transferring and replicating large volumes of data between on-premises storage systems, edge locations, and AWS storage services over the internet or AWS Direct Connect. It supports file data and associated file system metadata such as ownership, timestamps, and access permissions, ensuring seamless data migration and synchronization.
Key Features:
- High-Performance Data Transfer:
- Transfers large datasets at speeds significantly faster than open-source tools.
- Metadata Preservation:
- Maintains file system metadata such as ownership, timestamps, and permissions during transfers.
- Supported Locations:
- Amazon S3: Transfer data to/from S3 buckets, supporting all storage classes.
- Amazon EFS (Elastic File System): Seamless integration with EFS for NFS-based file systems.
- Amazon FSx (File Systems): Supports FSx for Windows File Server, FSx for Lustre, and FSx for NetApp ONTAP.
- On-Premises Storage: Includes Network File System (NFS) and Server Message Block (SMB) storage systems.
- Protocol Support:
- Uses NFS or SMB protocols for accessing and transferring data from on-premises systems.
- Task Automation:
- Automates data synchronization tasks, including scheduling recurring transfers.
- Data Validation:
- Automatically verifies data integrity during transfers, ensuring accuracy.
- AWS Management Console and API Integration:
- Configure, monitor, and manage transfers easily via the AWS Management Console or programmatically with APIs.
Subtypes and Concepts:
- Locations:
- Define the source and destination endpoints for data transfers, such as S3 buckets, EFS file systems, or FSx systems.
- Example: A location for Amazon FSx for Windows File Server serves as an endpoint for transferring data using the Server Message Block (SMB) protocol.
- Agents:
- Software agents deployed on-premises to facilitate secure communication between local storage systems and AWS.
- Tasks:
- A task specifies the source, destination, filters, and configurations for a data transfer job.
- Filters:
- Allow users to include or exclude specific files or directories during a transfer.
Use Cases:
- Cloud Migration:
- Efficiently move on-premises data to AWS storage services such as S3, EFS, or FSx.
- Hybrid Workloads:
- Synchronize data between on-premises storage and AWS for hybrid application scenarios.
- Backup and Disaster Recovery:
- Automate the replication of critical data to AWS for backup and recovery purposes.
- Data Lake Creation:
- Ingest large datasets into Amazon S3 for analytics and machine learning applications.
- Metadata Preservation:
- Retain access permissions, ownership, and timestamps for compliance and operational needs.
Governance and Security:
- Encryption:
- Encrypts data in transit using Transport Layer Security (TLS).
- Supports encryption at rest using AWS KMS for S3 and FSx destinations.
- Access Control:
- Uses IAM roles and policies to control access to DataSync resources and target AWS services.
- Monitoring and Logging:
- Integrates with CloudWatch to provide visibility into data transfer metrics and task statuses.
Benefits:
- Simplified Management:
- Automates and schedules repetitive data transfer tasks.
- Faster Transfers:
- Moves data at high speeds, significantly reducing transfer times compared to traditional methods.
- Seamless Integration:
- Works natively with AWS storage services for smooth data migration and synchronization.
- Reliable and Secure:
- Ensures data integrity and security during transfers, with automatic verification and encryption.
- Cost Efficiency:
- Pay only for the data transferred, avoiding additional licensing or hardware costs.
AWS Migration Hub
Type: Migration Tracking and Management Service Description: AWS Migration Hub provides a centralized platform to plan, track, and manage the migration of applications and resources to AWS. It integrates with various AWS and partner migration tools, offering a unified view of migration progress and outcomes across multiple projects and services.
Key Features:
- Centralized Migration Tracking:
- Offers a single dashboard to monitor migration progress for applications and servers across multiple AWS services and partner tools.
- Application Grouping:
- Organize servers and resources into logical application groups for better tracking and dependency management.
- Integration with Migration Tools:
- Supports AWS-native tools like AWS Application Migration Service, AWS Database Migration Service (DMS), and third-party tools such as CloudEndure.
- Customizable Metrics:
- Tracks migration status using metrics like server discovery, data replication, and cutover completion.
- Dependency Visualization:
- Automatically identifies application dependencies to ensure complete and efficient migration planning.
- Flexible Reporting:
- Provides detailed migration reports for individual applications or the entire portfolio.
- Multi-Region Support:
- Manage and track migrations across multiple AWS Regions for global projects.
Subtypes and Components:
- Discovery Tools:
- Integrates with tools like AWS Application Discovery Service to collect data about on-premises infrastructure and application dependencies.
- Migration Tools:
- Works seamlessly with AWS services like Application Migration Service, DMS, and partner tools to perform the actual migration.
- Application Portfolio:
- Helps group and manage applications, enabling a structured approach to migration.
- Progress Status:
- Tracks and categorizes migration phases (e.g., data replication, cutover, testing) for each application or server.
Use Cases:
- End-to-End Migration Management:
- Plan, execute, and monitor migrations of applications, servers, and databases from on-premises or other clouds to AWS.
- Application Dependency Mapping:
- Discover and visualize interdependencies between applications to reduce migration risks and ensure smooth transitions.
- Migration Tool Consolidation:
- Use a unified dashboard to manage migrations from multiple tools, reducing complexity and improving visibility.
- Progress Monitoring:
- Track real-time migration progress and completion status for individual applications or portfolios.
- Compliance and Reporting:
- Generate detailed reports for auditing and compliance purposes.
Governance and Security:
- Role-Based Access:
- Use IAM policies to control access to Migration Hub resources and data.
- Integration with CloudTrail:
- Logs all user activities and API calls for monitoring and compliance.
- Encryption:
- Ensures secure data handling by integrating with AWS KMS for encryption.
Benefits:
- Centralized Visibility:
- Consolidates migration progress and metrics into a single view, reducing management overhead.
- Simplified Planning:
- Facilitates detailed planning and execution by identifying dependencies and tracking tools.
- Enhanced Collaboration:
- Teams can work collaboratively with shared insights and consistent progress updates.
- Tool Agnostic:
- Supports a variety of migration tools, making it versatile for different workloads and environments.
- Scalable Management:
- Handles small-scale to enterprise-level migrations seamlessly.
AWS Snow Family
Type: Offline Data Transfer and Edge Computing Services Description: The AWS Snow Family consists of physical devices designed for offline data transfer and edge computing. It enables the movement of large volumes of data between on-premises locations and AWS or facilitates compute capabilities in disconnected or edge environments. The family includes Snowcone, Snowball, and Snowmobile, each tailored for specific data transfer and edge computing needs.
Key Services in AWS Snow Family
-
AWS Snowcone
- Description:
- The smallest member of the Snow Family, ideal for portable edge computing and data transfer.
- Lightweight and rugged, with onboard compute for running applications in remote environments.
- Capacity:
- Storage: 8 TB of usable storage.
- Use Cases:
- Portable data collection in remote or mobile environments.
- Edge computing for IoT devices.
- Data transfer from constrained locations.
-
AWS Snowball
- Description:
- Available in two variants: Snowball Edge Storage Optimized and Snowball Edge Compute Optimized.
- Supports large-scale data transfer and edge computing.
- Capacity:
- Storage Optimized: Up to 80 TB of usable storage.
- Compute Optimized: Supports 42 TB of usable storage with additional compute capabilities.
- Features:
- Edge Computing: Run applications on Snowball devices using AWS IoT Greengrass and EC2 instances.
- Encryption: Data is encrypted with AWS KMS during transfer.
- Use Cases:
- Large-scale data migrations to AWS.
- Processing and analyzing data in disconnected environments.
- Disaster recovery and backup.
-
AWS Snowmobile
- Description:
- A 45-foot shipping container designed for petabyte- and exabyte-scale data migrations.
- Moves massive datasets securely and efficiently.
- Capacity:
- Up to 100 PB per Snowmobile.
- Use Cases:
- Migrating entire data centers to AWS.
- High-volume archival and regulatory data transfers.
- Large-scale digital media migration.
Common Features Across the Snow Family
- Secure Data Handling:
- End-to-end encryption using AWS KMS.
- Tamper-evident devices ensure data security during transit.
- Integration with AWS Services:
- Data is seamlessly ingested into Amazon S3, EBS, or Glacier.
- Data Validation:
- Automatically validates data upon transfer to ensure integrity.
- Durability:
- Designed to withstand harsh environments for remote or edge use cases.
- Edge Computing Capabilities:
- Run applications locally on Snow devices for preprocessing, analytics, or AI/ML inference.
Use Cases
- Data Transfer and Migration:
- Efficiently move large volumes of data from on-premises to AWS without relying on the internet.
- Edge Computing:
- Process and analyze data in disconnected or latency-sensitive environments, such as oil rigs, ships, or military operations.
- Disaster Recovery:
- Rapidly back up or restore large datasets for disaster recovery planning.
- Media and Entertainment:
- Transfer massive video libraries or high-resolution content for processing and archiving.
- IoT and Analytics:
- Collect and preprocess IoT data at the edge before transferring to AWS for further analysis.
Benefits
- Scalability:
- Suitable for small data volumes (Snowcone) to massive datasets (Snowmobile).
- Cost Efficiency:
- Avoids high network transfer costs by utilizing offline transfer methods.
- Portability:
- Compact and rugged devices like Snowcone and Snowball can operate in remote and challenging environments.
- Enhanced Security:
- Hardware encryption and tamper-resistant designs safeguard sensitive data.
- Reliability:
- Provides consistent data transfer and edge compute capabilities even in disconnected environments.
AWS Transfer Family
Type: Managed File Transfer Service Description: The AWS Transfer Family enables secure and reliable file transfers directly into and out of AWS storage services using industry-standard file transfer protocols such as SFTP (Secure File Transfer Protocol), FTPS (File Transfer Protocol Secure), and FTP (File Transfer Protocol). It integrates seamlessly with Amazon S3 and Amazon EFS, making it easy to modernize and migrate legacy file transfer workflows to the cloud without changing client-side configurations.
Key Features
- Protocol Support:
- SFTP (SSH File Transfer Protocol): Securely transfers files using encryption and authentication.
- FTPS (File Transfer Protocol Secure): Transfers files over an encrypted SSL/TLS connection.
- FTP (File Transfer Protocol): For legacy workflows requiring unencrypted file transfers.
- Native AWS Integration:
- Transfers files directly to Amazon S3 or Amazon EFS, enabling further processing or storage in the AWS ecosystem.
- User Management:
- Supports Amazon Cognito, AWS Directory Service, or custom identity providers for user authentication.
- High Availability and Scalability:
- Fully managed service with automatic scaling to handle fluctuating workloads without manual intervention.
- Customizable Workflows:
- Supports custom workflows for post-transfer processing, such as Lambda triggers for file processing or moving files to different S3 buckets.
- Monitoring and Logging:
- Integrated with AWS CloudWatch and AWS CloudTrail for detailed monitoring, auditing, and troubleshooting.
- Security and Compliance:
- Provides fine-grained access control using IAM policies.
- Offers encryption for data at rest (S3, EFS) and in transit.
Subtypes and Components
- Endpoint Types:
- Public endpoints for internet-facing transfers.
- VPC-hosted endpoints for private, secure transfers within a Virtual Private Cloud (VPC).
- Authentication Methods:
- Service-Managed Users: Store user credentials securely in AWS Transfer Family.
- Custom Identity Providers: Use AWS Lambda to authenticate users via external systems.
- AWS Directory Service: Integrate with Microsoft Active Directory for enterprise authentication.
- Custom Processing Workflows:
- Automate actions like virus scanning, data parsing, or moving files across buckets using AWS Lambda. Use Cases
- Legacy File Transfer Modernization:
- Migrate on-premises SFTP/FTPS/FTP workflows to AWS without client-side changes.
- Secure Data Exchange:
- Enable secure data sharing with business partners, vendors, or clients.
- Integration with Analytics Pipelines:
- Automate ingestion of files into data lakes or analytics pipelines using Amazon S3.
- Multi-Region Data Access:
- Transfer data across regions for global applications or disaster recovery.
- IoT and Edge Data Collection:
- Securely transfer files from edge devices to AWS for processing and analysis. Governance and Security
- Encryption:
- Data is encrypted in transit using SFTP or FTPS and at rest in S3 or EFS.
- Access Control:
- Use IAM roles and policies to define granular access permissions for users.
- Auditing and Monitoring:
- Logs all file transfer activities via CloudTrail and provides performance metrics in CloudWatch.
- Compliance:
- Meets industry standards like GDPR, HIPAA, PCI DSS, and FedRAMP, ensuring regulatory compliance for sensitive workloads. Benefits
- Ease of Use: Fully managed service eliminates the need to set up or maintain file transfer servers.
- Scalability: Automatically scales to handle large volumes of file transfers.
- Cost-Effectiveness: Pay only for the resources used, without additional licensing costs.
- Compatibility: Supports legacy protocols for seamless migration without disrupting existing workflows.
- Enhanced Security: Built-in encryption, IAM-based access control, and compliance certifications.
AWS Application Migration Service (AWS MGN)
Type: Lift-and-Shift Migration Service Description: AWS Application Migration Service (AWS MGN) simplifies the migration of applications from physical, virtual, or cloud-based environments to AWS with minimal downtime. It continuously replicates source servers into AWS and converts them into native AWS resources. This approach allows for efficient and reliable migrations without requiring application re-architecture.
Key Features
- Continuous Replication:
- Uses block-level replication to copy data from source servers to AWS, ensuring minimal downtime during migration.
- Automated Conversion:
- Converts replicated servers into Amazon EC2 instances, retaining the original application stack.
- Testing and Validation:
- Launch test instances in AWS to validate the migration before final cutover.
- Support for Multiple Platforms:
- Migrates workloads from physical servers, VMware, Hyper-V, KVM, and other cloud providers.
- Customizable Launch Settings:
- Define EC2 instance types, networking configurations, and security groups for target resources.
- Post-Migration Modernization:
- Integrate migrated applications with AWS services, such as RDS, Lambda, or S3, for optimization.
- Integrated Dashboard:
- Provides a centralized view of replication status, server health, and migration progress.
Subtypes and Components
- Replication Agent:
- A lightweight agent installed on source servers to facilitate data replication to AWS.
- Launch Templates:
- Define instance types, storage configurations, and networking settings for converted resources.
- Testing and Cutover:
- Test migrated workloads in isolation before switching production traffic.
- Orchestration:
- Automated workflows to manage replication, testing, and launch processes.
Use Cases
- Lift-and-Shift Migrations:
- Quickly move existing workloads to AWS without requiring changes to the application stack.
- Disaster Recovery:
- Set up AWS as a disaster recovery site with near real-time replication and rapid failover capabilities.
- Data Center Consolidation:
- Migrate workloads from multiple on-premises data centers to AWS.
- Cloud-to-Cloud Migration:
- Transition applications from other cloud providers to AWS for consistent operations.
- Application Modernization:
- Migrate legacy applications to AWS, followed by modernization using AWS services.
Governance and Security
- Encryption:
- Data is encrypted in transit using TLS and optionally encrypted at rest using AWS KMS.
- Access Control:
- Utilize IAM roles to control access to migration resources and operations.
- Monitoring and Logging:
- Integrated with AWS CloudWatch for real-time monitoring and CloudTrail for auditing migration activities.
Benefits
- Simplified Migrations:
- Eliminates the complexity of manual migration steps, reducing migration effort and risk.
- Minimal Downtime:
- Continuous replication ensures that workloads remain operational until the final cutover.
- Cost-Effective:
- Pay only for the resources consumed during replication and testing, with no licensing costs.
- Scalability:
- Supports large-scale migrations of hundreds or thousands of servers.
- Flexibility:
- Customize launch configurations to match the performance and security requirements of target environments.
AWS Application Discovery Service
Type: Migration Planning Service Description: AWS Application Discovery Service helps enterprises plan migrations by collecting detailed information about on-premises workloads, including server configurations, utilization, and application dependencies. This data enables organizations to make informed decisions and prioritize migration efforts while reducing risk and downtime during migration.
Key Features
- Discovery Agents:
- Lightweight software agents installed on on-premises servers to collect detailed system and application metadata, including CPU, memory, storage, and network configurations.
- Agentless Discovery:
- Uses VMware vCenter to collect information about virtual machines without installing agents.
- Application Dependency Mapping:
- Automatically identifies dependencies between applications and servers, providing a comprehensive view of workloads.
- Performance Metrics:
- Gathers resource utilization data (CPU, memory, disk, and network) for workload sizing and optimization in AWS.
- Data Integration:
- Exports collected data to AWS Migration Hub or other tools for further analysis and migration tracking.
- Customizable Filters:
- Focus discovery efforts on specific applications, workloads, or servers for granular migration planning.
- Centralized Dashboard:
- Provides a single view of discovered resources and dependencies, streamlining the assessment process.
Subtypes and Components
- Discovery Agents:
- Installed on individual servers to capture system-level details, including installed software, running processes, and resource utilization.
- Agentless Discovery Connector:
- Deployed in VMware environments to gather data without requiring agent installation.
- Data Export:
- Integrates with AWS Migration Hub for centralized migration tracking and with other analysis tools like Amazon Athena or Amazon QuickSight.
- Dependency Visualization:
- Graphically displays server and application interdependencies, enabling better migration strategies.
Use Cases
- Migration Planning:
- Analyze on-premises workloads to determine migration feasibility and resource requirements.
- Application Dependency Mapping:
- Identify interdependent applications to ensure seamless migrations with minimal downtime.
- Cloud Readiness Assessment:
- Understand existing workload configurations to determine compatibility and cost optimization in AWS.
- Cost Estimation:
- Use collected utilization data to right-size AWS resources, reducing migration costs.
- Risk Mitigation:
- Identify potential bottlenecks or challenges before initiating migrations.
Governance and Security
- Data Encryption:
- Data collected by agents is encrypted in transit and at rest to ensure security.
- Access Control:
- Role-based access through IAM policies to restrict who can view and export discovery data.
- Auditing:
- Integration with AWS CloudTrail to log API activity and provide audit trails.
Benefits
- Comprehensive Visibility:
- Provides detailed insights into on-premises workloads, reducing blind spots during migration.
- Simplified Planning:
- Automates the discovery process, saving time and effort in collecting system details.
- Improved Accuracy:
- Helps avoid over-provisioning or under-provisioning AWS resources by providing accurate utilization data.
- Seamless Integration:
- Works with AWS Migration Hub and other AWS services for end-to-end migration tracking.
- Reduced Risk:
- Dependency mapping ensures that all related applications are migrated together, minimizing disruptions.
Networking and Content Delivery Cheat Sheet
AWS Client VPN
- Type: Secure VPN Access
- Description: Provides a secure VPN solution to access AWS and on-premises resources.
- Features:
- Supports OpenVPN-based connections.
- Fully managed and scalable.
- Integrates with Active Directory for authentication.
- Use Cases:
- Remote workforce access to AWS resources.
- Secure access to on-premises and cloud environments.
- Enabling multi-factor authentication (MFA) for remote connections.
Amazon CloudFront
- Type: Content Delivery Network (CDN)
- Description: Distributes content globally with low latency and high transfer speeds using edge locations.
- Features:
- Edge Locations: Points of presence (POPs) for caching content.
- Origin Shield: Extra caching layer for higher cache hit ratios.
- Custom SSL Certificates: Secure HTTPS connections.
- Use Cases:
- Accelerating website and API delivery.
- Streaming media content.
- Secure content distribution with geo-restrictions.
AWS Direct Connect
- Type: Dedicated Network Connection
- Description: AWS Direct Connect establishes a private, high-speed, and low-latency network connection between your on-premises infrastructure and AWS. It provides a reliable alternative to internet-based connectivity, enabling hybrid cloud architectures with consistent performance and enhanced security. Key Features:
- Dedicated Connectivity:
- Offers a dedicated physical connection to AWS, bypassing the public internet for improved performance and reliability.
- High Bandwidth:
- Supports bandwidth options from 50 Mbps to 100 Gbps, accommodating diverse workload needs.
- Reduced Latency:
- Provides consistent and predictable network performance, ideal for latency-sensitive applications.
- Resilience and Redundancy:
- Supports redundant connections and integration with AWS Transit Gateway for high availability.
- Private VIF and Public VIF:
- Private Virtual Interface (VIF): Connects directly to VPCs for private communication.
- Public Virtual Interface (VIF): Provides access to public AWS services, such as S3 and DynamoDB.
- Direct Connect Gateway:
- Allows you to connect to multiple VPCs across regions using a single Direct Connect connection.
Governance and Security:
- Dedicated Links: Isolate traffic from the public internet to improve security and minimize risks.
- Encryption: Use VPN over Direct Connect for additional encryption if required.
- Compliance: Meet strict regulatory and compliance requirements with private connections.
- Access Control: Manage access to resources via IAM and VPC security groups.
Use Cases:
- Hybrid Cloud Architectures:
- Extend on-premises infrastructure to the cloud with consistent performance.
- Data-Intensive Workloads:
- Transfer large datasets to AWS efficiently, such as for backups, analytics, or media processing.
- Latency-Sensitive Applications:
- Host applications requiring low latency, such as gaming, financial trading, or IoT.
- Regulatory Compliance:
- Ensure secure and compliant connectivity for industries like healthcare and finance.
- Multi-Region Access:
- Connect to multiple VPCs and regions using Direct Connect Gateway for global workloads. Benefits:
- Improved Performance: Consistent bandwidth and reduced network jitter.
- Cost Savings: Reduce data transfer costs compared to internet-based connections.
- Enhanced Security: Private, dedicated connections enhance data security.
- Scalability: Flexible bandwidth options support growing workloads.
Elastic Load Balancing (ELB)
- Type: Load Balancing Service
- Description: Elastic Load Balancing (ELB) automatically distributes incoming application traffic across multiple targets, such as Amazon EC2 instances, containers, IP addresses, and Lambda functions, to ensure high availability and fault tolerance. ELB supports multiple protocols, including HTTP, HTTPS, TCP, and UDP, and integrates seamlessly with other AWS services. Key Features:
- Types of Load Balancers:
- Application Load Balancer (ALB): Operates at Layer 7 (HTTP/HTTPS) and supports advanced routing, such as path- or host-based routing and WebSocket connections. ALB cannot have static IP addresses.
- Network Load Balancer (NLB): Operates at Layer 4 (TCP/UDP) for ultra-low latency and high throughput, ideal for real-time applications. NLB can have static ip addresses.
- Gateway Load Balancer (GWLB): Simplifies deployment and scaling of virtual appliances like firewalls and monitoring systems.
- Classic Load Balancer (CLB): Legacy option supporting Layer 4 and Layer 7, primarily for existing applications.
- Auto Scaling Integration:
- Automatically scales resources behind the load balancer to handle traffic spikes.
- Health Checks:
- Monitors the health of targets and routes traffic only to healthy instances.
- SSL/TLS Termination:
- Offloads SSL/TLS encryption to improve application performance.
- Cross-Zone Load Balancing:
- Distributes traffic evenly across instances in multiple Availability Zones for enhanced reliability.
- Sticky Sessions:
- Maintains user sessions by directing traffic from the same client to the same target.
- Logging and Monitoring:
- Integration with CloudWatch for monitoring metrics, and access logging to S3 for auditing and troubleshooting.
Governance and Security:
- Access Control:
- Use security groups and IAM policies to restrict access.
- TLS Encryption:
- Ensure secure communication with SSL/TLS certificates via AWS Certificate Manager (ACM).
- Compliance:
- Meet regulatory requirements with integrated encryption and logging.
- Web Application Firewall (WAF):
- Protect web applications from common threats like SQL injection and cross-site scripting (XSS).
Use Cases:
- Web Applications:
- Use ALB to manage HTTP/HTTPS traffic with advanced routing for microservices and containerized applications.
- Low-Latency Applications:
- Use NLB for latency-sensitive workloads, such as gaming or financial transactions.
- Virtual Appliances:
- Deploy and scale third-party appliances with GWLB for simplified management.
- Hybrid Architectures:
- Route traffic between on-premises data centers and AWS cloud resources.
- Session Persistence:
- Maintain sticky sessions for stateful applications like e-commerce websites.
Benefits:
- High Availability: Distributes traffic across multiple targets and Availability Zones.
- Scalability: Automatically adjusts capacity to meet demand.
- Improved Security: Leverages encryption, access controls, and AWS WAF integration.
- Flexibility: Supports multiple protocols and workloads with different load balancer types.
AWS Global Accelerator
- Type: Network Performance Enhancer
- Description: AWS Global Accelerator improves application performance by routing user traffic through the AWS global network to the optimal endpoint based on health, geography, and latency. It provides static IP addresses that remain constant regardless of endpoint changes, simplifying DNS management and enhancing failover capabilities. Key Features:
- Static Anycast IPs:
- Assigns two static IP addresses for your application, simplifying DNS management.
- Remains unchanged even if backend resources or regions are updated.
- Global Traffic Management:
- Routes traffic to the optimal endpoint across AWS Regions for low latency and high availability.
- Health Checks:
- Monitors endpoint health and automatically redirects traffic away from unhealthy targets.
- Traffic Dials:
- Control the proportion of traffic directed to specific AWS Regions, enabling blue/green deployments or gradual migrations.
- Integrated Security:
- Leverages AWS Shield and WAF for DDoS protection and web application security.
- Seamless Integration:
- Works with Elastic Load Balancers, EC2 instances, and AWS Application Load Balancers.
Governance and Security:
- Enhanced Security:
- Traffic is routed over the AWS global network, reducing exposure to public internet risks.
- DDoS Protection:
- Built-in integration with AWS Shield provides robust protection against distributed denial-of-service (DDoS) attacks.
- Access Control:
- Use security groups, IAM roles, and AWS WAF to secure traffic and endpoints.
- Compliance:
- Suitable for applications requiring compliance with strict regulatory standards by providing secure and predictable traffic routing.
Use Cases:
- Global Application Acceleration:
- Improve the performance of latency-sensitive applications such as gaming, media streaming, or IoT by routing traffic through the AWS backbone.
- Disaster Recovery and High Availability:
- Automatically failover traffic to healthy endpoints in case of regional outages or endpoint failures.
- Multi-Region Deployment Optimization:
- Manage traffic across multiple AWS Regions with granular control and reduced latency.
- Hybrid Workloads:
- Accelerate traffic between on-premises data centers and AWS.
- Blue/Green Deployments:
- Use traffic dials to route portions of traffic to new environments for testing or staged rollouts.
Benefits:
- Improved Performance: Leverages the AWS global network to reduce latency and jitter.
- High Availability: Ensures seamless failover and reliability across endpoints.
- Ease of Management: Static IPs simplify DNS configurations and reduce operational overhead.
- Enhanced Security: Routes traffic securely, leveraging AWS’s infrastructure and built-in protections.
AWS PrivateLink
- Type: Private Connectivity
- Description: Establishes private connectivity between VPCs and AWS services or third-party applications without exposing traffic to the internet.
- Features:
- Uses interface VPC endpoints.
- Supports multiple VPCs within the same account or across accounts.
- Use Cases:
- Secure access to AWS services from VPCs.
- Connecting SaaS providers to customer VPCs.
- Ensuring compliance with security standards.
Amazon Route 53
- Type: Domain Name System (DNS) Service
- Description: Provides scalable, highly available DNS and domain registration. Key Features:
- DNS Management:
- Host and manage DNS records for custom domain names.
- Supports all common DNS record types (e.g., A, AAAA, CNAME, MX, TXT).
- Routing Policies:
- Simple: Directs traffic to a single resource.
- Weighted: Splits traffic across multiple resources based on assigned weights.
- Latency-Based: Routes traffic to the region with the lowest latency.
- Failover: Redirects traffic to healthy resources during failures.
- Geolocation: Routes traffic based on the user’s geographic location.
- Multi-Value Answer: Returns multiple healthy endpoints for high availability.
- Domain Registration:
- Allows you to register and manage domain names directly through Route 53.
- Health Checks and Monitoring:
- Performs health checks to ensure resources are available.
- Automatically removes unhealthy resources from DNS routing.
- DNS Failover:
- Provides seamless failover between primary and secondary resources during downtime.
- Integration with AWS Services:
- Works seamlessly with services like CloudFront, Elastic Load Balancing (ELB), and S3 for routing traffic.
Governance and Security:
- IAM Permissions: Control access to Route 53 resources.
- Private Hosted Zones: Create private DNS zones for resources in Amazon VPCs.
- DNSSEC Support: Protects against DNS spoofing and ensures data integrity.
- Logging and Auditing: Integrates with CloudTrail to track changes and DNS queries.
Use Cases:
- Website and Application Hosting:
- Route traffic to web servers, APIs, or other endpoints across AWS or on-premises environments.
- High Availability and Failover:
- Use health checks and failover policies to ensure application availability during outages.
- Latency Optimization:
- Direct users to the nearest regional endpoints for reduced latency.
- Global Traffic Distribution:
- Implement geolocation or weighted routing for tailored user experiences or load distribution.
- Multi-Region Disaster Recovery:
- Automatically route traffic to backup resources during regional outages.
Benefits:
- Reliability: Ensures consistent and uninterrupted DNS resolution.
- Scalability: Handles billions of queries per day with low latency.
- Flexibility: Offers multiple routing policies to meet diverse requirements.
- Security: Provides advanced features like DNSSEC and private hosted zones for secure DNS management.
- Seamless Integration: Works effortlessly with other AWS services for complete traffic management.
AWS Site-to-Site VPN
- Type: Managed VPN Service
- Description: Establishes a secure connection between AWS VPCs and on-premises data centers.
- Features:
- Supports IPsec tunnels.
- Redundant connections for high availability.
- Compatible with most on-premises VPN devices.
- Use Cases:
- Hybrid cloud connectivity.
- Secure data transfer between on-premises and AWS.
- Disaster recovery setups.
AWS Transit Gateway
- Type: Network Transit Hub
- Description: Simplifies connectivity between multiple VPCs, AWS accounts, and on-premises networks.
- Features:
- Centralized connectivity for large networks.
- Integration with Direct Connect and Site-to-Site VPN.
- Scalable for thousands of VPCs and connections.
- Use Cases:
- Centralized VPC management in large organizations.
- Multi-region application deployment.
- Simplified network architecture.
Amazon VPC (Virtual Private Cloud)
- Type: Virtual Networking
- Description: Provides a logically isolated network environment in the AWS Cloud. Key Features:
- Subnets:
- Separate resources by Availability Zones (AZs) and designate as public or private for controlled access.
- Security Groups:
- Act as stateful firewalls for resources, controlling inbound and outbound traffic at the instance level.
- Network ACLs (Access Control Lists):
- Provide stateless filtering of traffic at the subnet level to enforce network-level access policies.
- VPC Peering:
- Connect two VPCs across accounts or Regions to enable resource sharing while maintaining isolation.
- Internet Gateway (IGW):
- Enables internet access for public-facing resources like web servers.
- NAT Gateway:
- Allows private instances to access the internet without exposing them directly, supporting security and operational needs.
- Elastic IPs:
- Assign static public IP addresses to resources for consistent access.
- Route Tables:
- Direct traffic between subnets, VPCs, and external resources using customizable routes.
- PrivateLink:
- Connect VPCs to AWS services and third-party applications privately, bypassing the internet.
- Transit Gateway:
- Simplify connectivity between multiple VPCs, AWS accounts, and on-premises networks. Note: Enhanced networking provides higher bandwidth, higher packet per second (PPS) performance, and consistently lower inter-instance latencies. Governance and Security:
- Access Control:
- Use IAM policies, Security Groups, and Network ACLs to restrict access.
- Monitoring:
- Integrates with CloudWatch and VPC Flow Logs for network monitoring and troubleshooting.
- Encryption:
- Use VPN or Direct Connect for encrypted connections between on-premises and AWS.
- Isolation:
- Maintain logical separation between resources in different VPCs using subnets and route tables.
Use Cases:
- Web Hosting:
- Host web applications in public subnets with secure backend databases in private subnets.
- Hybrid Networking:
- Connect on-premises data centers with VPCs using VPN or AWS Direct Connect.
- Microservices Architectures:
- Use separate subnets and security groups to isolate services.
- Disaster Recovery:
- Set up failover environments with VPC Peering and NAT Gateways.
- High Availability:
- Distribute resources across multiple subnets in different Availability Zones for fault tolerance.
- Big Data and Analytics:
- Process sensitive data in private subnets while securely transferring results to public endpoints.
Benefits:
- Customizable Networking: Tailor VPCs to meet specific application and compliance requirements.
- Enhanced Security: Secure resources with fine-grained access controls.
- Scalability: Expand your network with additional subnets, route tables, or VPC peering.
- Cost-Effective: Leverage NAT Gateways and Internet Gateways for optimal resource access and security.
- Integrated Services: Seamlessly connect with other AWS services like S3, EC2, and Lambda.
Comparison of Networking and Content Delivery Services Service Best For AWS Client VPN Secure remote access for workforce. Amazon CloudFront Accelerated content delivery with global caching. AWS Direct Connect High-speed, low-latency hybrid connectivity. Elastic Load Balancing Traffic distribution and fault tolerance. AWS Global Accelerator Improving global application performance. AWS PrivateLink Private access to AWS services and third-party apps. Amazon Route 53 DNS management and traffic routing. AWS Site-to-Site VPN Secure connections between AWS and on-premises. AWS Transit Gateway Centralized multi-VPC and on-premises connectivity. Amazon VPC Isolated, customizable cloud networks.
Security, Identity, and Compliance Cheat Sheet
AWS Artifact
- Type: Compliance Documentation
- Description: Provides access to AWS compliance reports and agreements.
- Features:
- Downloadable audit artifacts like SOC reports, PCI documentation, and ISO certifications.
- On-demand self-service access.
- Use Cases:
- Simplifying compliance audits.
- Demonstrating regulatory compliance to stakeholders.
- Accessing contractual agreements for specific AWS services.
AWS Audit Manager
- Type: Compliance Automation Tool
- Description: Helps continuously audit AWS usage to ensure compliance with industry standards.
- Features:
- Pre-built frameworks for standards like GDPR, HIPAA, and ISO.
- Automated evidence collection.
- Use Cases:
- Preparing for compliance audits.
- Reducing manual effort in audit preparation.
- Monitoring ongoing compliance.
AWS Certificate Manager (ACM)
- Type: SSL/TLS Certificate Management
- Description: Simplifies the provisioning, management, and deployment of SSL/TLS certificates for securing websites and applications.
- Features:
- Automatic certificate renewal.
- Integration with services like CloudFront and ELB.
- Use Cases:
- Enabling HTTPS for web applications.
- Securing API endpoints.
- Managing SSL/TLS certificates without manual intervention.
AWS CloudHSM
- Type: Hardware Security Module (HSM)
- Description: Offers dedicated hardware for secure key storage and cryptographic operations.
- Features:
- FIPS 140-2 Level 3 compliance.
- Full control over cryptographic keys.
- Use Cases:
- Storing and managing encryption keys securely.
- Compliance with stringent cryptographic standards.
- Offloading cryptographic operations.
Amazon Cognito
Type: Identity and Access Management Service Description: Amazon Cognito provides authentication, authorization, and user management for web and mobile applications. It simplifies the process of adding user sign-up, sign-in, and access control to applications while supporting federated identities from social identity providers (Google, Facebook, Apple, etc.) and enterprise identity providers (SAML, OpenID Connect).
Key Features
- User Pools:
- Manage user directories for app authentication with built-in support for user registration, login, and recovery flows.
- Supports multi-factor authentication (MFA) and advanced security features like adaptive authentication.
- Identity Pools (Federated Identities):
- Grant temporary access to AWS services based on user identities.
- Combine federated identities from social providers and user pools.
- Social and Enterprise Identity Providers:
- Integrates with social providers (Google, Facebook, Apple, Amazon).
- Supports enterprise providers via SAML 2.0 and OpenID Connect.
- Hosted UI:
- Prebuilt, customizable web UI for user sign-up, sign-in, and password management.
- Security Features:
- Multi-Factor Authentication (MFA): Adds an extra layer of security using SMS or TOTP-based authentication.
- Adaptive Authentication: Detects unusual sign-in activities and enforces additional security challenges.
- Advanced Security Features: Mitigates compromised credential use and identifies risky users.
- Token-Based Authentication:
- Issues JSON Web Tokens (JWTs) for secure communication and resource access.
- Custom Authentication Flows:
- Build custom workflows using AWS Lambda triggers for tailored user experiences.
- User Management:
- Supports user registration, password reset, account recovery, and account deactivation.
- Global User Access:
- Provides globally accessible endpoints for consistent user experiences across regions.
- Scalable and Serverless:
- Automatically scales to handle millions of users without infrastructure management.
Components
- User Pool:
- Central directory for managing user authentication and attributes.
- Identity Pool:
- Enables temporary access to AWS resources by mapping user identities to IAM roles.
- Tokens:
- ID Token: Contains user profile information (e.g., name, email).
- Access Token: Used to authorize access to resources.
- Refresh Token: Allows refreshing of ID and Access tokens.
- Hosted UI:
- Fully managed user interface for authentication flows, which can be customized to match branding.
- Lambda Triggers:
- Customize workflows like pre-signup validation, post-authentication actions, and token generation.
Use Cases
- User Authentication:
- Manage sign-up, sign-in, and user verification for web and mobile applications.
- Access Control for AWS Resources:
- Provide temporary access to S3, DynamoDB, and other AWS services using identity pools.
- Federated Authentication:
- Enable users to log in using social identity providers like Google or Facebook.
- Secure Applications:
- Use multi-factor authentication (MFA) and adaptive authentication to enhance app security.
- Enterprise Authentication:
- Integrate with SAML or OpenID Connect for single sign-on (SSO) and enterprise identity federation.
- Custom Authentication Workflows:
- Build tailored experiences for applications using Lambda triggers.
- Cross-Platform Access:
- Provide consistent user experiences and authentication across devices and platforms.
Integration with AWS Services Integrated With:
- Amazon API Gateway: Protect APIs with Cognito user pools as an authentication mechanism.
- AWS Lambda: Extend Cognito workflows with custom triggers.
- Amazon S3: Grant temporary, scoped access to files based on user permissions.
- Amazon DynamoDB: Enable secure access for user-specific data storage.
- AWS AppSync: Authenticate GraphQL APIs using Cognito.
- AWS Amplify: Simplify integration of authentication for front-end applications.
- AWS IAM: Map Cognito users to IAM roles for secure access to AWS resources.
- Amazon CloudWatch: Monitor user authentication activities and metrics. Not Integrated With:
- Direct integration with databases (e.g., RDS, MongoDB) without using a custom API layer.
Governance and Security
- IAM Policies:
- Control access to Cognito resources and associated AWS services.
- Encryption:
- Encrypts user data at rest and in transit.
- Uses AWS KMS for encryption of sensitive attributes.
- Multi-Factor Authentication (MFA):
- Adds an extra layer of protection via SMS or authenticator apps.
- Advanced Security:
- Detects compromised credentials and unusual sign-in behaviors.
- Auditing and Logging:
- Track user activity and authentication logs using AWS CloudTrail.
Benefits
- Ease of Use:
- Simplifies integration of authentication and user management for applications.
- Scalable:
- Handles millions of users with no operational overhead.
- Secure:
- Provides industry-standard security practices like token-based authentication and MFA.
- Cost-Effective:
- Pay only for active users and operations, with a free tier for small-scale applications.
- Flexible:
- Supports a wide range of authentication providers, workflows, and integration options.
- Developer-Friendly:
- Offers SDKs, APIs, and CLI for easy integration and management.
Amazon Detective
- Type: Security Investigation Tool
- Description: Analyzes and visualizes security data to identify and investigate potential threats.
- Features:
- Automated threat correlation.
- Integration with GuardDuty, CloudTrail, and VPC Flow Logs.
- Use Cases:
- Investigating unauthorized access attempts.
- Identifying root causes of security incidents.
- Strengthening security posture based on analytics.
AWS Directory Service
Type: Managed Directory Service Description: AWS Directory Service provides fully managed Microsoft Active Directory (AD) and other directory solutions in the AWS Cloud. It helps manage user authentication, access control, and directory-based policies for cloud and on-premises resources. AWS Directory Service enables seamless integration with Windows workloads, AWS services, and applications that require directory-based authentication. Key Features
- Directory Types:
- AWS Managed Microsoft AD: Fully managed Microsoft Active Directory running on Windows Server.
- AD Connector: Proxy service for redirecting directory requests to on-premises Active Directory.
- Simple AD: Lightweight, standalone directory based on Samba for basic directory needs.
- Seamless Integration:
- Works natively with Microsoft Windows workloads, including AWS services like WorkSpaces, Amazon RDS, and Amazon EC2.
- Multi-Region Deployment:
- Supports automatic replication of directories across multiple AWS Regions for global availability.
- Scalability and High Availability:
- Provides automatic scaling and replication for resilience and fault tolerance.
- Managed Service:
- Eliminates the need for manual management, including patching, backups, and monitoring.
- Hybrid Integration:
- Extend on-premises Active Directory to the cloud using AD Connector for hybrid workloads.
- Compliance:
- Meets industry standards, including HIPAA, GDPR, and SOC compliance.
- Secure Access:
- Supports multi-factor authentication (MFA) for added security.
- Integration with AWS Services:
- Compatible with AWS applications like Amazon WorkSpaces, AWS Single Sign-On (SSO), and Amazon RDS.
Directory Types
- AWS Managed Microsoft AD:
- Full Microsoft AD with built-in replication, high availability, and schema compatibility.
- Enables group policies and trust relationships with on-premises directories.
- AD Connector:
- Serves as a proxy to on-premises Active Directory without storing directory information in AWS.
- Ideal for hybrid cloud environments.
- Simple AD:
- Standalone directory based on Samba 4 for lightweight use cases.
- Suitable for small-scale applications without needing full Microsoft AD capabilities.
Use Cases
- Windows Workloads on AWS:
- Centralized authentication for Windows applications and EC2 instances.
- Hybrid Environments:
- Extend on-premises AD to AWS for hybrid workloads using AD Connector.
- Single Sign-On (SSO):
- Enable SSO for AWS and third-party applications with Active Directory authentication.
- Access Management:
- Manage user and group access to AWS resources and applications.
- Amazon WorkSpaces and RDS Authentication:
- Use AWS Directory Service for seamless user authentication in Amazon WorkSpaces and RDS databases.
- Policy Enforcement:
- Apply group policies to manage permissions and compliance across cloud environments.
Integration with AWS Services Integrated With:
- Amazon WorkSpaces: Directory authentication for desktop-as-a-service solutions.
- Amazon RDS: Integrates with RDS for SQL Server, PostgreSQL, and MySQL to manage database user authentication.
- AWS Single Sign-On (SSO): Centralized SSO for AWS accounts and third-party applications.
- Amazon EC2: Provides domain join capabilities for Windows EC2 instances.
- AWS IAM: Extend IAM roles and permissions with directory-based access control.
- Amazon FSx for Windows File Server: Seamless integration for file storage with directory-based access control. Not Integrated With:
- Standalone AWS services that do not rely on directory-based authentication, such as S3 or DynamoDB.
Governance and Security
- IAM Policies:
- Control access to AWS Directory Service resources and associated AWS services.
- Encryption:
- Directory data is encrypted at rest using AWS KMS.
- Communication is secured via SSL/TLS encryption.
- Compliance:
- AWS Directory Service complies with HIPAA, GDPR, SOC, and other regulatory standards.
- Audit Logs:
- Monitor directory activities using AWS CloudTrail and Amazon CloudWatch.
- Secure Connectivity:
- Use AWS Direct Connect or VPN for secure communication with on-premises directories.
Benefits
- Fully Managed Service:
- Eliminates the overhead of managing and maintaining directory infrastructure.
- Scalability:
- Supports dynamic scaling to accommodate growth in user and resource demands.
- Hybrid Flexibility:
- Seamlessly integrates with on-premises Active Directory for hybrid cloud environments.
- Cost-Effective:
- Pay-as-you-go pricing without the need for expensive hardware or licensing.
- Reliability:
- High availability and fault tolerance with automated backups and failover.
- Easy Integration:
- Works natively with AWS services and Windows-based workloads.
- Security and Compliance:
- Industry-standard security practices and regulatory compliance ensure data protection.
AWS Firewall Manager
- Type: Centralized Firewall Management
- Description: Simplifies the management of AWS WAF, Shield, and VPC security groups across multiple accounts.
- Features:
- Centralized policy enforcement.
- Integration with AWS Organizations.
- Use Cases:
- Ensuring consistent firewall rules across accounts.
- Managing DDoS protection policies.
- Compliance with security policies.
Amazon GuardDuty
- Type: Threat Detection Service
- Description: Uses machine learning to detect anomalies, unauthorized access, and potential threats.
- Features:
- Monitors VPC Flow Logs, DNS logs, and CloudTrail events.
- Automatic threat scoring.
- Use Cases:
- Identifying compromised resources.
- Detecting anomalous activity in AWS accounts.
- Enhancing cloud security monitoring.
AWS IAM Identity Center (Single Sign-On)
- Type: Centralized User Access
- Description: Provides single sign-on (SSO) to AWS accounts and business applications.
- Features:
- Integrates with existing identity providers.
- Role-based access control.
- Use Cases:
- Simplifying user access to AWS resources.
- Managing multi-account access centrally.
- Enhancing security with MFA.
AWS Identity and Access Management (IAM)
- Type: Access Control Service
- Description: Enables fine-grained access control for AWS services and resources.
- Features:
- Role-based and policy-based permissions.
- Temporary security credentials.
- Use Cases:
- Defining least-privilege access for users.
- Managing access for applications and services.
- Auditing user actions for compliance.
Amazon Inspector
- Type: Vulnerability Management
- Description: Scans EC2 instances and container images for vulnerabilities and compliance issues.
- Features:
- Automatically scans resources.
- Provides detailed remediation recommendations.
- Use Cases:
- Identifying software vulnerabilities.
- Automating security compliance checks.
- Monitoring container security.
AWS Key Management Service (KMS)
- Type: Managed Encryption Key Service
- Description: Provides encryption and key management for AWS resources and applications.
- Features:
- Integrated with most AWS services.
- Custom key management policies.
- Use Cases:
- Encrypting data at rest and in transit.
- Managing keys for compliance.
- Enabling secure data sharing between services.
Amazon Macie
- Type: Data Security and Privacy Service
- Description: Amazon Macie is a fully managed service that uses machine learning to automatically discover, classify, and protect sensitive data in Amazon S3. It helps organizations comply with privacy regulations and reduce the risk of data exposure by providing insights into where sensitive data resides and how it is being accessed. Key Features:
- Data Discovery and Classification:
- Automatically scans S3 buckets to identify sensitive data such as Personally Identifiable Information (PII), financial data, or intellectual property.
- Uses machine learning and pattern matching for accurate detection.
- Automated Alerts:
- Generates alerts when it detects risks such as overly permissive S3 bucket policies or unencrypted sensitive data.
- Customizable Classification Rules:
- Define custom criteria and keywords to tailor sensitive data discovery for specific organizational needs.
- Data Visibility:
- Provides a comprehensive inventory of S3 buckets, including details on bucket security, encryption, and shared access.
- Integration with Security Tools:
- Integrates with AWS Security Hub, CloudWatch, and other tools for centralized monitoring and response.
- Dashboard and Reporting:
- Intuitive dashboards provide insights into sensitive data findings and security posture, with exportable reports for auditing and compliance.
Governance and Security:
- Data Encryption: Identifies unencrypted sensitive data and recommends remediation.
- Access Control: Highlights buckets with excessive permissions or public access risks.
- Auditing and Compliance: Simplifies auditing processes for regulations like GDPR, CCPA, and HIPAA by providing visibility into sensitive data.
- Monitoring: Continuous monitoring ensures real-time awareness of changes to data security.
Use Cases:
- Regulatory Compliance:
- Meet privacy regulations by identifying and securing sensitive customer and financial data.
- Data Governance:
- Maintain control over sensitive data by identifying access risks and ensuring proper security measures.
- Security Incident Response:
- Detect and respond to potential data breaches involving sensitive information.
- Data Visibility:
- Gain insights into data security and usage across S3 buckets.
- Risk Mitigation:
- Prevent accidental exposure of sensitive data by identifying and remediating risky configurations.
Benefits:
- Enhanced Data Security: Automates the detection and classification of sensitive data to prevent exposure.
- Simplified Compliance: Provides actionable insights to comply with regulations and avoid penalties.
- Cost Efficiency: Focuses scanning and monitoring on relevant data, reducing unnecessary costs.
- Scalability: Automatically adjusts to handle data growth without requiring manual intervention.
AWS Network Firewall
- Type: Managed Network Firewall
- Description: Provides stateful inspection, intrusion prevention, and deep packet inspection for VPCs.
- Features:
- Centralized control for traffic filtering.
- Integration with AWS Firewall Manager.
- Use Cases:
- Protecting VPCs from unauthorized traffic.
- Enforcing compliance with organizational rules.
- Securing hybrid cloud networks.
AWS Resource Access Manager (AWS RAM)
Type: Resource Sharing Service Description: AWS Resource Access Manager (AWS RAM) simplifies the process of securely sharing AWS resources across accounts within your organization or with external accounts. This eliminates the need to duplicate resources and helps centralize management while maintaining security and access controls. Key Features
- Cross-Account Resource Sharing:
- Share resources across multiple AWS accounts within an organization or with external accounts.
- Wide Range of Supported Resources:
- Share various AWS resources, such as VPCs, Transit Gateways, Subnets, Resource Groups, and more.
- Integration with AWS Organizations:
- Allows seamless sharing across accounts in an AWS Organization without requiring additional permissions.
- Fine-Grained Access Control:
- Leverages IAM policies to define who can share, accept, and manage shared resources.
- Automated Invitations:
- Automatically send resource-sharing invitations to external AWS accounts.
- Centralized Management:
- Provides a unified dashboard to monitor and manage shared resources.
- Transparency and Auditing:
- Integration with AWS CloudTrail logs all resource-sharing activities for compliance and troubleshooting. Subtypes and Components
- Resource Shares:
- Logical entities that define which resources are shared and with whom.
- Principals:
- The accounts, organizations, or organizational units (OUs) with which resources are shared.
- Resource Types:
- Supported resources include:
- Amazon VPC subnets
- AWS Transit Gateways
- Amazon Aurora Clusters
- License Manager configurations
- Resource Groups
- Accepting and Managing Shares:
- Recipients must explicitly accept shared resources unless they are part of an AWS Organization. Use Cases
- Centralized Networking:
- Share VPCs, subnets, and Transit Gateways across accounts for consistent network architecture.
- Cost Optimization:
- Avoid duplicating resources by sharing them across accounts, reducing operational costs.
- Streamlined Licensing:
- Share License Manager configurations across multiple accounts to maintain compliance.
- Resource Centralization:
- Centralize resource management in a primary account while granting access to others.
- Multi-Tenant Applications:
- Enable shared access for applications or services that span multiple AWS accounts. Governance and Security
- Access Control:
- Define sharing permissions using IAM roles and policies.
- Activity Logging:
- AWS CloudTrail logs all sharing actions for monitoring and compliance.
- Security Boundaries:
- Shared resources remain secure as the owning account retains control over permissions. Benefits
- Simplified Resource Management:
- Centralize resource sharing to reduce administrative overhead.
- Enhanced Security:
- Use fine-grained IAM policies to control access to shared resources.
- Cost Efficiency:
- Share resources without the need to replicate them across accounts.
- Scalability:
- Support for sharing resources with multiple accounts, organizations, or OUs.
- Seamless Integration:
- Works natively with AWS Organizations, simplifying multi-account setups.
AWS Secrets Manager
- Type: Secrets Management Service
- Description: Securely stores and retrieves secrets like API keys, passwords, and database credentials.
- Features:
- Automatic secret rotation.
- Fine-grained access control with IAM.
- Use Cases:
- Securing application secrets.
- Automating secret rotation.
- Enabling centralized secret management.
AWS Security Hub
- Type: Centralized Security Management
- Description: AWS Secrets Manager securely stores, retrieves, and rotates secrets such as database credentials, API keys, and other sensitive information. It helps organizations simplify secret management, enhance security, and maintain compliance by automating secret rotation and access control. Key Features:
- Secure Storage:
- Stores sensitive information such as credentials, keys, and tokens securely, with encryption using AWS Key Management Service (KMS).
- Automatic Rotation:
- Automatically rotates secrets for supported services (e.g., Amazon RDS, Redshift) without disrupting applications.
- Fine-Grained Access Control:
- Uses AWS Identity and Access Management (IAM) policies to control who can access secrets.
- Integration with AWS Services:
- Seamlessly integrates with AWS services such as Lambda, EC2, and RDS for secure access to secrets.
- Secret Versioning:
- Maintains multiple versions of secrets to enable smooth rollback during updates.
- Audit and Monitoring:
- Logs all secret access and changes via AWS CloudTrail, enabling audit and compliance.
- Custom Rotation Logic:
- Supports custom Lambda functions for secret rotation for custom or third-party applications.
- Cross-Region Replication:
- Allows secrets to be replicated across AWS Regions for disaster recovery and multi-region access.
Governance and Security:
- Encryption: Secrets are encrypted at rest and in transit using customer-managed KMS keys.
- Access Management: Define precise permissions using IAM policies and resource-based policies.
- Auditing: Monitor and log all secret-related activities with AWS CloudTrail.
- Compliance Support: Simplifies adherence to regulatory requirements by ensuring secure and traceable secret management.
Use Cases:
- Database Credentials Management:
- Store and rotate database credentials automatically for RDS, Redshift, and custom databases.
- API Key Storage:
- Securely store and retrieve API keys for third-party services or internal APIs.
- Application Secrets Management:
- Manage secrets required by serverless or containerized applications using Lambda, ECS, or Kubernetes.
- Custom Key Rotation:
- Implement custom rotation logic for proprietary systems or third-party tools.
- Multi-Region Applications:
- Replicate secrets across Regions for high availability and disaster recovery.
Benefits:
- Enhanced Security: Prevents hardcoding of sensitive data in application code or configuration files.
- Operational Efficiency: Automates rotation and retrieval of secrets, reducing manual effort.
- Simplified Compliance: Centralized secret management and logging simplify audits and regulatory adherence.
- Scalability: Seamlessly handles growing numbers of secrets and integrations.
- Cost-Effective: Pay only for secrets managed, without additional overhead for secret storage or rotation tools.
AWS Shield
Type: Distributed Denial of Service (DDoS) Protection Service Description: AWS Shield is a managed DDoS protection service designed to safeguard applications running on AWS from distributed denial-of-service (DDoS) attacks. AWS Shield provides two levels of protection: AWS Shield Standard, which is automatically available at no additional cost, and AWS Shield Advanced, which offers enhanced protection, detailed metrics, and 24/7 support.
Key Features
- Two-Tier Protection:
- AWS Shield Standard:
- Automatic protection against common network and transport-layer DDoS attacks.
- Included at no additional cost with all AWS services.
- AWS Shield Advanced:
- Includes advanced protections, detailed metrics, and global threat environment insights.
- Requires subscription and includes access to the AWS DDoS Response Team (DRT).
- Real-Time Attack Mitigation:
- Detects and mitigates DDoS attacks in real time without affecting application performance.
- Comprehensive Coverage:
- Protects web applications, APIs, and other internet-facing workloads on AWS.
- Integration with AWS Services:
- Native integration with Amazon CloudFront, Elastic Load Balancing (ELB), AWS Global Accelerator, and Amazon Route 53 for seamless protection.
- Health-Based Detection:
- Monitors application health to differentiate legitimate traffic from DDoS traffic.
- Advanced Metrics and Reporting:
- Shield Advanced provides detailed attack diagnostics, traffic trends, and customizable notifications through CloudWatch.
- Cost Protection (Shield Advanced):
- Covers costs for scaling resources due to a DDoS attack and waives data transfer charges for attacks.
- Global Threat Environment Dashboard (Shield Advanced):
- Offers insights into current global DDoS threat trends.
Subtypes and Components
- AWS Shield Standard:
- Automatically enabled across all AWS accounts.
- Protects against common volumetric and state-exhaustion attacks at no cost.
- AWS Shield Advanced:
- Subscription-based service with enhanced features, including 24/7 access to the AWS DDoS Response Team (DRT), advanced metrics, and cost protection.
- AWS DDoS Response Team (DRT):
- Experts available 24/7 to assist with attack mitigation strategies and response.
- Integration with AWS Firewall Services:
- Works in tandem with AWS WAF and AWS Firewall Manager for comprehensive application-layer protection.
Integration with AWS Services Integrated With:
- Amazon CloudFront: Protects applications globally with edge-based DDoS mitigation.
- Elastic Load Balancing (ALB and NLB): Defends backend workloads against DDoS attacks.
- AWS Global Accelerator: Ensures low-latency routing while mitigating attacks.
- Amazon Route 53: Shields DNS services against DDoS attacks.
- AWS WAF: Enhances application-layer protection by filtering malicious traffic. Not Integrated With:
- Direct protection for standalone Amazon EC2 instances not behind ELB, CloudFront, or Global Accelerator.
- Services like Amazon RDS, S3, or Lambda, which rely on upstream integrations for Shield benefits.
Use Cases
- Protecting Web Applications:
- Safeguard websites and APIs from volumetric attacks, such as UDP floods or SYN floods.
- Securing DNS Services:
- Shield Route 53 DNS services from DNS-based DDoS attacks.
- Mitigating API Threats:
- Prevent disruption to API endpoints exposed through CloudFront or ALB.
- Compliance and Availability:
- Ensure continuous availability and compliance with SLAs during DDoS events.
- Reducing Cost Impact of Attacks (Shield Advanced):
- Avoid financial impact due to scaling costs during attacks.
Governance and Security
- Monitoring:
- Integrated with Amazon CloudWatch for real-time attack diagnostics and alerts.
- Access Control:
- Uses IAM policies to manage access to Shield configurations and reports.
- Auditing and Logging:
- Integrated with AWS CloudTrail for logging all Shield-related activities.
- Proactive Response:
- AWS DDoS Response Team (DRT) provides tailored guidance and support during attacks.
Benefits
- Always-On Protection:
- Automatic coverage against common DDoS attacks with Shield Standard.
- Enhanced Security Posture:
- Advanced protection and detailed insights with Shield Advanced.
- Seamless Integration:
- Natively integrates with key AWS services for comprehensive defense.
- Cost Optimization:
- Shield Advanced offers financial protection against attack-related scaling and data transfer costs.
- Global Coverage:
- Shield leverages AWS’s global infrastructure to mitigate threats at the edge.
- Expert Support:
- Access to AWS DDoS Response Team for expert guidance during critical events.
AWS WAF (Web Application Firewall)
Type: Application Layer Protection Description: AWS WAF is a managed web application firewall that helps protect your web applications and APIs against common web exploits and vulnerabilities, including SQL injection, cross-site scripting (XSS), and bot attacks. By defining custom rules or using AWS Managed Rules, you can filter and block malicious traffic before it reaches your application.
Key Features
- Customizable Rules:
- Define rules to allow, block, or monitor (count) web requests based on IP addresses, HTTP headers, HTTP body, URI strings, and more.
- AWS Managed Rules:
- Pre-configured rule sets to protect against common threats like OWASP Top 10 vulnerabilities, bots, and more.
- Bot Control:
- Detects and mitigates bot traffic, distinguishing between legitimate bots (e.g., search engines) and malicious ones.
- Real-Time Visibility:
- Provides logs and metrics for all web traffic, enabling detailed monitoring and analysis.
- Rule Prioritization:
- Rules are evaluated in order of priority to determine how web requests are handled.
- Rate-Based Rules:
- Protect against denial-of-service (DoS) attacks by limiting the rate of requests from specific IP addresses.
- Integration with AWS Services:
- Works seamlessly with services like Amazon CloudFront, Application Load Balancer (ALB), and Amazon API Gateway.
- Web Traffic Filtering:
- Filters traffic based on geographic location (geo-matching) or request characteristics.
- Fine-Grained Controls:
- Provides full control over which requests are allowed or blocked, reducing the risk of overblocking.
Subtypes and Components
- Web ACLs (Access Control Lists):
- Configurations that define how to monitor and filter traffic for a specific resource.
- Rules and Rule Groups:
- Individual rules or grouped rulesets applied to Web ACLs for filtering requests.
- Managed Rule Groups:
- AWS-provided or third-party rules for common security threats.
- Rate-Based Rules:
- Automatically blocks traffic exceeding a specified request rate.
- Logging and Metrics:
- Integrated with Amazon CloudWatch for monitoring and detailed request logs.
Integration with AWS Services Integrated With:
- Amazon CloudFront:
- Distributes web content globally while integrating with WAF to filter malicious traffic at the edge.
- Application Load Balancer (ALB):
- Applies WAF rules to incoming traffic routed to backend services.
- Amazon API Gateway:
- Protects REST and WebSocket APIs against malicious requests.
- AWS App Runner:
- Enables WAF protection for containerized web applications. Not Integrated With:
- Amazon Route 53:
- WAF does not natively integrate with Route 53 for DNS-level protection.
- AWS Elastic Beanstalk:
- While ALB within Elastic Beanstalk supports WAF indirectly, WAF is not directly integrated into Beanstalk environments.
- AWS EC2 Instances:
- Does not directly protect traffic to EC2 instances unless routed through an ALB, API Gateway, or CloudFront.
Use Cases
- Application Layer Security:
- Protect web applications from SQL injection, XSS, and other common threats.
- Bot Management:
- Detect and block bad bot traffic while allowing legitimate bots.
- Geo-Blocking:
- Restrict traffic from specific geographic regions.
- DDoS Mitigation:
- Use rate-based rules to throttle high-volume malicious requests.
- API Protection:
- Secure APIs by filtering malicious requests or blocking unauthorized access.
- Regulatory Compliance:
- Use WAF to meet compliance requirements for web application security.
Governance and Security
- Encryption:
- Encrypted communication between WAF and AWS services.
- Monitoring and Auditing:
- Logs all traffic data and rule matches through CloudWatch or S3 for auditing and compliance.
- IAM Access Control:
- Uses IAM policies to control who can manage WAF configurations.
Benefits
- Customizable Protection:
- Fully customizable rules tailored to specific application needs.
- Scalable:
- Automatically scales to handle high volumes of web traffic.
- Seamless Integration:
- Native integration with AWS services for simplified setup and management.
- Cost-Effective:
- Pay-as-you-go pricing ensures cost efficiency.
- Real-Time Visibility:
- Gain actionable insights into web traffic and rule performance.
- Global Protection:
- Combined with CloudFront, provides protection at edge locations for minimal latency.
Comparison of Security Services Service Best For AWS Artifact Accessing compliance reports. AWS Audit Manager Automating compliance audits. AWS Certificate Manager Managing SSL/TLS certificates. AWS CloudHSM Dedicated cryptographic hardware. Amazon Cognito Managing user authentication. Amazon Detective Investigating security incidents. AWS Directory Service Centralized Active Directory management. AWS Firewall Manager Centralized firewall policy enforcement. Amazon GuardDuty Threat detection using machine learning. AWS IAM Fine-grained access control for AWS resources. Amazon Inspector Identifying vulnerabilities in EC2 and containers. AWS KMS Managing encryption keys for compliance. Amazon Macie Discovering and securing sensitive data. AWS Network Firewall Stateful network traffic filtering. AWS RAM Sharing resources across AWS accounts. AWS Secrets Manager Securely storing application secrets. AWS Security Hub Centralized security findings. AWS Shield Protecting against DDoS attacks. AWS WAF Protecting web applications from common threats.
Serverless
AWS Fargate
- Type: Serverless Containers
- Description: AWS Fargate is a serverless compute engine for containers that allows users to run and manage containerized applications without provisioning or managing servers. It integrates with Amazon Elastic Container Service (ECS) and Elastic Kubernetes Service (EKS) to provide a seamless and scalable container orchestration experience.
Key Features:
- Serverless Container Management:
- Removes the need to provision and manage EC2 instances.
- Automatically scales resources to match the application's demand.
- Resource Isolation:
- Provides task-level isolation for enhanced security by running each task or pod in its own runtime environment.
- Simplified Networking:
- Supports AWS VPC networking to give containers dedicated ENIs, security groups, and private IPs.
- Seamless Integration:
- Works with ECS and EKS to manage container deployments.
- Supports integration with AWS services like CloudWatch, Secrets Manager, and IAM.
- Flexible Resource Configuration:
- Allows specifying CPU and memory requirements for each container, enabling fine-grained resource allocation.
- Cost Efficiency:
- Pay only for the resources used by running tasks or pods, with billing based on vCPU and memory usage.
Governance and Security:
- IAM Integration:
- Assign IAM roles to tasks for secure access to AWS resources.
- Data Encryption:
- Support for encrypted EFS volumes and secure data transmission.
- Compliance:
- Fargate complies with various industry standards, including GDPR, HIPAA, and PCI DSS.
- Monitoring and Logging:
- Integrates with CloudWatch for detailed performance metrics and logs.
Use Cases:
- Microservices Architectures:
- Deploy containerized microservices without managing infrastructure.
- Event-Driven Applications:
- Run serverless workloads triggered by events using Fargate and AWS Lambda.
- Batch Processing:
- Scale up containers for parallel processing of data-heavy workloads.
- CI/CD Pipelines:
- Use Fargate in pipelines to build, test, and deploy containerized applications.
- Hybrid Cloud Applications:
- Combine Fargate with ECS Anywhere for seamless hybrid container orchestration.
- Machine Learning Workflows:
- Run pre-processing tasks or lightweight machine learning inference tasks in containers.
Benefits:
- Ease of Use: Eliminates the need to manage infrastructure, enabling focus on application development.
- Scalability: Automatically adjusts compute capacity to meet workload demands.
- Cost Efficiency: Pay-as-you-go pricing model ensures no cost for idle resources.
- Enhanced Security: Task-level isolation improves application security.
- Flexibility: Works seamlessly with multiple container orchestration platforms (ECS and EKS).
AWS Lambda
- Type: Event-Driven Compute
- Description: AWS Lambda is a serverless compute service that allows you to run code in response to events without provisioning or managing servers. Lambda automatically scales to handle incoming requests and executes code only when triggered, ensuring cost-effectiveness. You are billed based on the compute time consumed, with no charge when your code is not running.
- Use Cases:
- Event-driven processing.
- Serverless APIs.
- Background jobs. Integration with AWS Services Integrated With:
- Amazon S3: Trigger functions on object uploads, deletions, or modifications.
- Amazon DynamoDB: Invoke Lambda functions on table updates or new records.
- Amazon API Gateway: Build serverless APIs by invoking Lambda functions for HTTP requests.
- Amazon Kinesis: Process streaming data in real-time.
- Amazon SNS and SQS: Use Lambda for asynchronous messaging and event processing.
- AWS Step Functions: Orchestrate workflows using Lambda functions.
- Amazon EventBridge: Schedule or route events to Lambda for handling. Not Directly Integrated With:
- Standalone EC2 instances or RDS, though these can send events to Lambda indirectly via triggers like CloudWatch Events or SNS.
Storage Services Cheat Sheet
Amazon S3 (Simple Storage Service)
- Type: Object Storage
- Description: Scalable, secure, and durable storage for any data type.
- Storage Classes:
- S3 Standard: General-purpose storage for frequently accessed data.
- Use Cases: Content delivery, mobile and gaming apps, data lakes.
- S3 Intelligent-Tiering: Automatically moves data between tiers based on access patterns.
- Use Cases: Cost-optimized storage for unknown or changing access patterns.
- S3 Standard-IA (Infrequent Access): Lower cost for less frequently accessed data.
- Use Cases: Backups, disaster recovery.
- S3 One Zone-IA: Like Standard-IA but stored in a single Availability Zone.
- Use Cases: Secondary backups, easily recreatable data.
- S3 Glacier Instant Retrieval: Archival storage with millisecond access.
- Use Cases: Frequently accessed archive data.
- S3 Glacier Flexible Retrieval: Archive storage with access times of minutes to hours.
- Use Cases: Data requiring occasional access.
- S3 Glacier Deep Archive: Lowest-cost storage with access times of 12+ hours.
- Use Cases: Long-term compliance archives, regulatory requirements.
- Use Cases:
- Storing application data and backups.
- Hosting static websites.
- Creating data lakes for analytics.
Amazon EBS (Elastic Block Store)
- Type: Block Storage
- Description: Persistent block-level storage for EC2 instances.
- Volume Types:
- General Purpose SSD (gp3, gp2):
- Use Cases: Boot volumes, general-purpose workloads.
- Provisioned IOPS SSD (io2, io1):
- Use Cases: Mission-critical applications like databases.
- Throughput Optimized HDD (st1):
- Use Cases: Big data, data warehouses.
- Cold HDD (sc1):
- Use Cases: Infrequent access, lowest-cost storage.
- Features:
- Snapshots for data backup and recovery.
- Encryption at rest and in transit.
- Use Cases:
- Persistent storage for EC2.
- High-performance transactional databases.
Amazon EFS (Elastic File System)
- Type: Managed File Storage
- Description: Fully managed NFS file system for shared access across multiple EC2 instances.
- Performance Modes:
- General Purpose:
- Use Cases: Low-latency requirements like web servers.
- Max I/O:
- Use Cases: High-throughput workloads like media processing.
- Throughput Modes:
- Bursting Throughput: Automatically scales based on demand.
- Provisioned Throughput: For consistent high throughput.
- Use Cases:
- Shared file systems for containerized applications.
- Data analysis, machine learning, and media processing.
Amazon FSx
- Type: Specialized File Storage
- Variants:
- FSx for Windows File Server:
- Description: Fully managed Windows file system.
- Use Cases: Windows applications, Active Directory integrations.
- FSx for Lustre:
- Description: High-performance file storage optimized for HPC workloads.
- Use Cases: Machine learning, big data analytics, HPC.
- FSx for NetApp ONTAP:
- Description: Enterprise-grade file storage with ONTAP features.
- Use Cases: File sharing, hybrid cloud deployments.
- FSx for OpenZFS:
- Description: Open-source file system for high-speed performance.
- Use Cases: DevOps environments, CI/CD pipelines.
- Use Cases:
- High-performance workloads.
- Application-specific file systems.
Amazon S3 Glacier
- Type: Archival Storage
- Variants:
- Glacier Instant Retrieval:
- Description: Archive data with millisecond access.
- Use Cases: Frequently accessed archival workloads.
- Glacier Flexible Retrieval:
- Description: Cost-effective storage with access in minutes to hours.
- Use Cases: Regulatory data, backups.
- Glacier Deep Archive:
- Description: Lowest-cost archival storage.
- Use Cases: Long-term storage for infrequently accessed data.
- Use Cases:
- Regulatory compliance.
- Long-term data retention.
- Disaster recovery archives.
AWS Storage Gateway
- Type: Hybrid Cloud Storage
- Description: Connects on-premises environments to AWS, enabling seamless integration of cloud storage with on-premises workloads.
- Gateway Types:
- File Gateway:
- Use Cases: Storing file-based workloads in S3.
- Volume Gateway:
- Use Cases: Backing up on-premises applications with snapshots in S3.
- Tape Gateway:
- Use Cases: Replacing physical tape backups with virtual tapes in AWS.
- Use Cases:
- Hybrid cloud storage.
- Archiving and disaster recovery.
- Extending on-premises storage to AWS.
AWS Backup
- Type: Centralized Backup Service
- Description: Simplifies the process of backing up data across AWS services and on-premises systems.
- Features:
- Centralized backup policies.
- Automated backup scheduling.
- Cross-region and cross-account backups.
- Use Cases:
- Disaster recovery planning.
- Compliance with data retention policies.
- Protecting databases, EFS, and storage volumes.
Storage Use Cases Comparison
Service Best For Amazon S3 Storing unstructured data, static websites, backups. Amazon EBS Persistent, low-latency storage for EC2. Amazon EFS Shared file systems for multiple instances. Amazon FSx Specialized file systems like Windows, Lustre. Amazon Glacier Archiving infrequently accessed data. Storage Gateway Bridging on-premises workloads to the cloud. AWS Backup Centralized backup for AWS services.
Full Notes in Details with Photos Below
🧔 Accounts - Identity and Access Management (IAM) Basics
Account and IAM Basics
💡 AWS Account: Container for identities (users) and resources.
Account root user has full control over all of the AWS account and any resources created within in. The root user can’t be restricted.
IAM User Groups and Roles can also be created and given full or limited permissions. All identities start with no permissions.
May be good practice to create multiple AWS Accounts for different uses (prod, dev, test).
- Every AWS account comes with its own running copy of IAM, which is a database.
- IAM is a globally resilient service, so any data is always secure across all AWS regions. (Exam Q)
- The IAM in each of your accounts is your own dedicated instance of IAM, separate from other accounts.
- IAM
- User
- IDs which represent humans or apps that need access to your account
- Group
- Collection of related users, e.g. dev team, finance or HR
- Role
- Can be used by AWS Services, or for granting external access to your account
- Used when the number of things is uncertain.
- User
- IAM Policy
- Allow or deny access to AWS services when and only when they’re attached to IAM users, groups or roles.
- IAM three main jobs
- Manage identities - An ID Provider (IDP)
- Create, modify and delete IDs such as users and roles
- Authenticate identities
- Prove you are who you claim to be - generally username and passwords
- Authorize
- Allow or deny access to resources
- Manage identities - An ID Provider (IDP)
- IAM is provided for free
- No cost for users, groups and roles. Limits for number of each.
- IAM is global service.
- Allow or deny its ids on its AWS account
- No direct control on external accounts or users - only control local ids in your account
- Identity federation and MFA
- Use Facebook, Twitter, Google etc. to access AWS resources
IAM Access Keys
- Long-term credentials
- Don’t update manually
- IAM User don’t need username and password - for CLI access key is enough
- IAM User can have up to two access keys
- Can be created, deleted, made inactive or made active
Access Keys consist of two parts
- Both are provided when created an access key
- These are only provided once - no ability to get access to the keys again. Need to be stored safely.
- Both parts are used when accessing AWS via CLI
- Access keys need to be deleted and recreated if they are leaked
- Possible to have two sets of keys such that you can create a new one, update all applications using the keys and then delete the old set
Access Key ID: ABABABABABABABA
Secret Access Key: oierWRhoefWORIOF/DFLWAnljef
☁️ Cloud Computing Fundamentals
Essential Characteristics of Cloud Computing
💡 On demand self-service: A consumer can unilaterally provision computing capabilities, such as server time and network storage, as needed automatically without requiring human interaction with each service provider. Can provision capabilities as needed without requiring human interaction.
Provision and terminate using a UI/CLI without human interaction.
Broad network access: Capabilities are available over the network and accessed through standard mechanisms that promote use by heterogeneous thin or thick client platforms (e.g., mobile phones, tablets, laptops, and workstations). Capabilities are available over the network and accessed through standard mechanisms.
Access services over any networks, on any devices, using standard protocols and methods.
Resource pooling: The provider’s computing resources are pooled to serve multiple consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand. There is a sense of location independence in that the customer generally has no control or knowledge over the exact location of the provided resources but may be able to specify location at a higher level of abstraction (e.g., country, state, or datacenter). Examples of resources include storage, processing, memory, and network bandwidth. There is a sense of location independence… no control or knowledge over the exact location of the resources. Resources are pooled to serve multiple consumers using a multi-tenant model.
Economies of scale, cheaper service.
Rapid elasticity: Capabilities can be elastically provisioned and released, in some cases automatically, to scale rapidly outward and inward commensurate with demand. To the consumer, the capabilities available for provisioning often appear to be unlimited and can be appropriated in any quantity at any time. Capabilities can be elastically provisioned and released to scale rapidly outward and inward with demand. To the consumers, the capabilities available for provisioning ofter appear to be unlimited.
Scale UP (OUT) and DOWN (IN) automatically in response to system load.
Measured service: Cloud systems automatically control and optimize resource use by leveraging a metering capability at some level of abstraction appropriate to the type of service (e.g., storage, processing, bandwidth, and active user accounts). Resource usage can be monitored, controlled, and reported, providing transparency for both the provider and consumer of the utilized service. Resource usage can be monitored, controlled, reported and BILLED.
Usage is measured. Pay for what you consume.
Public vs Private vs Hybrid vs Multi Cloud
💡 Public cloud: AWS, Azure, Google. Meet the essential characteristics of cloud computing.
Multi-cloud: Using more than one of the public cloud platforms.
Private cloud: Run on business premises. AWS Outpost, Azure Stack, Anthos.
Hybrid cloud: Using private cloud and public cloud in cooperation as a single environment.
Cloud Service Models
X as a Service
Infrastructure Stack
- Application
- Data
- Runtime
- Container
- OS
- Virtualization
- Servers
- Facilities
Parts you manage, parts managed by the vendor.
Unit of consumption is what makes each service model different - application vs OS
XaaS Services
On-Premises
- Application
- Data
- Runtime
- Container
- OS
- Virtualization
- Servers
- Infrastructure
- Facilities
DC Hosted
- Application
- Data
- Runtime
- Container
- OS
- Virtualization
- Servers
- Infrastructure
Facilities
Data centre
IaaS
- Application
- Data
- Runtime
- Container
- OS
VirtualizationServersInfrastructureFacilities
EC2 uses the IaaS service model
PaaS
- Application
- Data
- Runtime
ContainerOSVirtualizationServersInfrastructureFacilities
Heroku is a PaaS
SaaS
- Application
DataRuntimeContainerOSVirtualizationServersInfrastructureFacilities
Netflix, Dropbox, Office 365 etc.
++ Faas, CaaS, DBaaS
🗣YAML - YAML Ain't Markup Language
Human readable data serialization language. A YAML document is an unordered collection of key:value pairs, each key has a value. YAML support strings, integers, floats, booleans, lists, dictionary.
cats: ["ben", "bin", "ban"]
# Same list can also be represented as below. Indentation matters.
cats:
- "ben"
- "bin"
- ban # values can be enclosed in "", '' or not - all valid but enclosing can be more precise
cats:
- name: ben
color: [black, white]
- name: bin
color: "mixed"
- name: ban
color: "white"
numofeyes: 1
Resources:
s3bucket:
Type: "AWS::S3::Bucket"
Properties:
BucketName: "1337"
🐣 AWS Fundamentals
Public vs Private Services
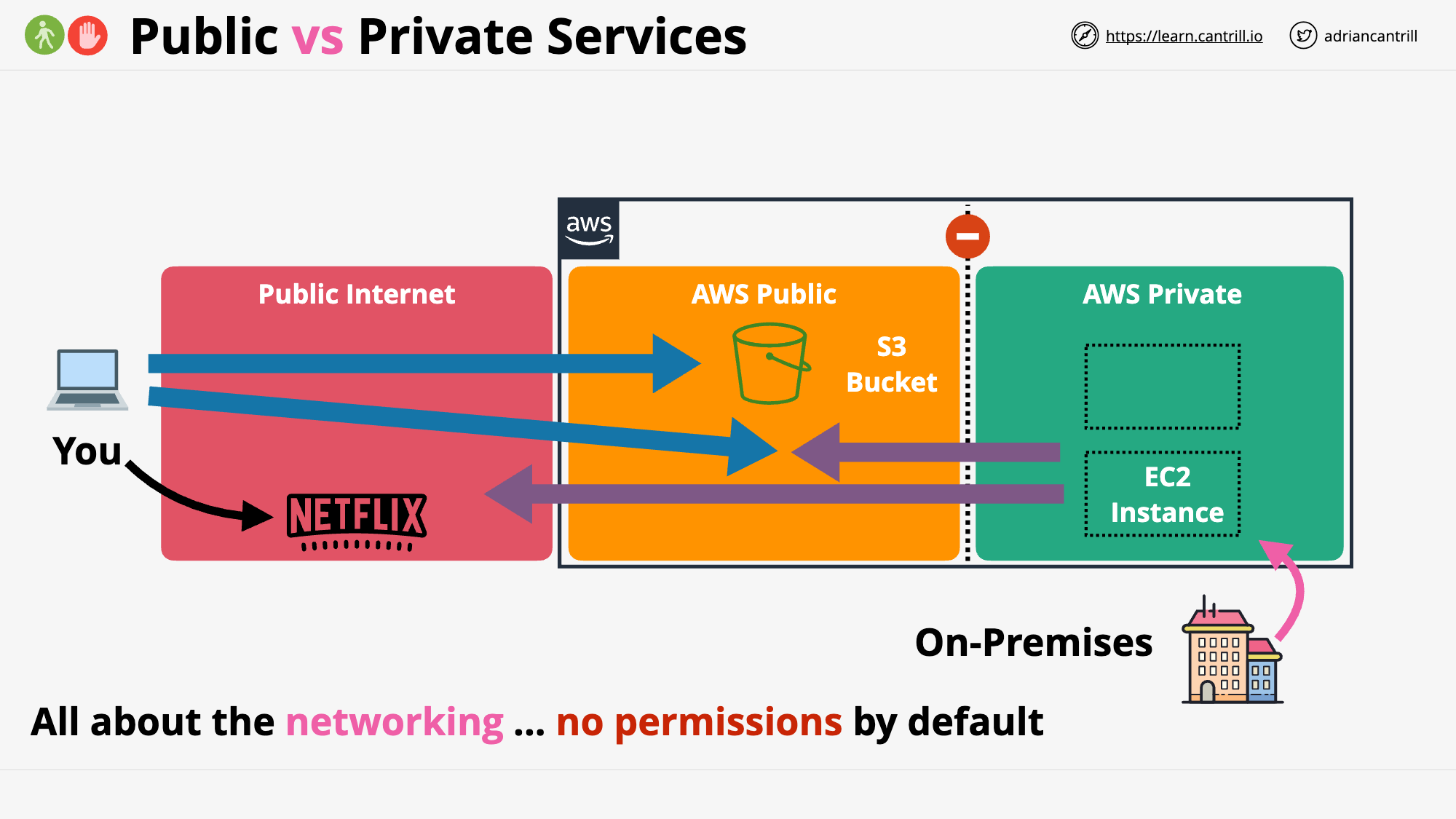
AWS Global Infrastructure
AWS Regions + AWS Edge Locations
Geographic Separation: Isolated Fault Domain
Geopolitical Separation: Different governance
Location Control: Performance
Region Code: us-east-1
Region Name: N. Virginia
Availability Zone (AZ): Level of granularity below regions. Isolated infrastructure within a region.
us-east-1a, us-east-1b, …, us-east-1f
Service Resilience:
- Globally resilient: IAM and Route 53. Can tolerate failure of multiple regions without affecting service.
- Region resilient: If an AZ in a region fails, the service can continue operating. If all AZ fails, the service fails.
- AZ resilient
Virtual Private Cloud (VPC) Basics
💡 A virtual network inside AWS
A VPC is within 1 account & 1 region ❗
Private and isolated unless you decide otherwise
Two types: Default VPC and Custom VPCs
Custom VPCs used in almost all AWS deployments. More later.
VPCs are created within a region. VPCs cannot communicate outside their network unless you specifically allow it. **By default a VPC is entirely private.**❗
VPC CIDER (Classless Inter-Domain Routing): Every VPC is allocated a range of IP addresses. If you allow anything to communicate to a VPC, it needs to communicate to that VPC CIDR. Any outgoing connection is going to originate from that VPC CIDR. Custom VPCs can have multiple CIDR ranges, but the default VPC only gets one, which is always the same. ❗Default VPC IP range: 172.31.0.0/16 ❗
****Each subnet within a VPC is located within a AZ, and can never be changed. Default VPC is configured to have a subnet in every AZ. Each use a part of the IP range and cannot overlap. This is how a VPC is resilient.
Default VPC Basic
- One per region - can be removed and recreated
- Default VPC CIDR is always 172.31.0.0/16 ❗
- /20 subnet in each AZ in the region
- The higher the /number is the smaller the range. /17 is half the size of /16.
- IGW: Internet Gateway
- VPC
- SG: Security Group
- (EC2) Instances
- Stateful
- Incoming rule change = allow outgoing response traffic
- Open port 80 for incoming will allow port 80 for outgoing response
- Incoming rule change = allow outgoing response traffic
- Allow rules only
- Instances can have multiple SGs
- Allow CIDR, IP, SG as destination
- NACL: Network Access Control List
- Subnet
- Stateless
- Open rule 80 for incoming does not allow port 80 for outgoing
- Allow and deny rules
- Subnets can have only one NACL
- Only allow CIDR as destination
- Subnets assign public IPv4 addresses
- Best practice not to use default VPC
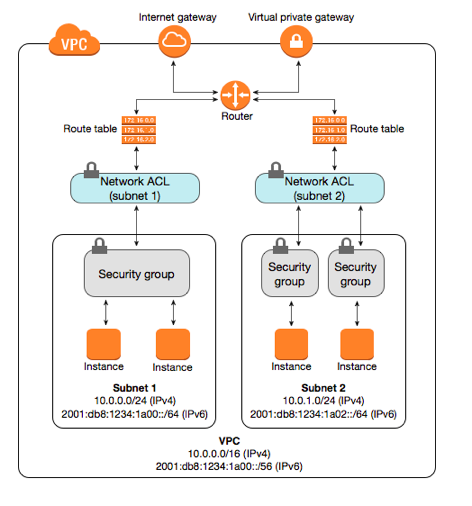
Elastic Compute Cloud (EC2) Basics
EC2 is AWS’s implement of IaaS - Infrastructure as a Service Default compute service within AWS. Provide access to VMs known as instances
EC2 Key Facts & Features
- IaaS - Provides Virtual Machines (Instances)
- Private service by default - uses VPC networking
- AZ resilient - Instance fails if AZ fails
- Different instance sizes and capabilities
- On-Demand Billing - Per second
- Local on-host storage or Elastic Block Store (EBS)
- Instance composition: CPU, memory, disk and networking. All four are billed when running. ❗
- Only disk storage is billed when stopped (EBS).
Instance Lifecycle
- Running
- Stopped
- Terminated
Amazon Machine Image (AMI)
- An EC2 instance can be created from an AMI, or an EC2 can be used to create an AMI
- Contains
- Permissions - who can and can’t use the AMI
- Public - Everyone can launch instances from that AMI (Linux and Windows)
- Owner - Implicit allow
- Explicit - specific AWS accounts allowed
- Boot Volume
- The drive that boots the OS
- Block Device Mapping
- Links the volumes the AMI have
- Mapping between volumes
- Permissions - who can and can’t use the AMI
Connecting to EC2
- EC2 instances can run different OS’s
- Windows: RDP - Remote Desktop Protocol
- Protocol Port 3389
- Linux: SSH protocol
- Port 22
Simple Storage Service (S3) Basics
- Global Storage Platform - regional based/resilient
- Data is replicated across AZs in that region
- Public service, unlimited data & multi-user
- Movies, audio, photos, text, large data sets
- Economical & accessed via UI/CLI/API/HTTP
- Should be your default storing point
- Objects & Buckets
- Objects is the data you store
- Buckets are container for objects
S3 Objects
- A file made up of two parts: key and value
- E.g koala.jpg : koala-image
- Value is the content being stored
- 0 - 5 TB data
- Version ID
- Metadata
- Access Control
- Subresources
S3 Buckets
- Never leaves a region unless you configure it to do so
- A bucket is identified by its bucket name, which must be globally unique
- Often AWS stuff is only unique within an account or region - bucket is exception to this
- Unlimited Objects
- Flat Structure - all objects are stored at root level in the bucket
- Folders are prefixed names - but objects are still stored at the same level
Summary
- Bucket names are globally unique
- 3-63 characters, all lower case, no underscores
- Start with a lowercase letter or a number
- Can’t be IP formatted e.g. 1.1.1.1
- Buckets - 100 soft limit, 1000 hard per account
- Unlimited objects in bucket, 0 bytes to 5TB
- Key = Name, Value = Data
- ARN: Amazon Resource Name
S3 Patterns and Anti-Patterns
- S3 is an object store - not file or block
- S3 has no file system - it is flat
- You can’t mount an S3 bucket as (K:\ or /images)
- Great for large scale data storage, distribution or upload
- Great for “offload”
- INPUT and/or OUTPUT to MANY AWS products
CloudFormation Basics
CloudFormation is a Infrastructure as Code (IaC) product in AWS which allows automation infrastructure creation, update and deletion Templates created in YAML or JSON Templates used to create stacks, which are used to interact with resources in an AWS account
YAML
AWSTemplateFormatVersion: "version date"
Description: # Must directly follow AWSTemplateFormatVersion if defined
String
Metadata: # Control the UI
template metadata
Parameters: # Add fields that prompt the user for more information
set of parameters
Mappings: # Key/Value pairs which can be used for lookups
set of mappings
Conditions: # Allow decision making. Create Condition / Use Condition.
set of conditions
Transform:
set of transforms
Resources:
set of resources
Outputs: # Outputs from the template being applied
set of outputs
Template
-
All those other things
-
Resources
YAMLResources: Instance: Type: 'AWS::EC2::Instance' # Logical Resource Properties: ImageId: !Ref LatestAmiId InstanceType: !Ref InstanceType KeyName: !Ref KeyName
Stack
- A living representation of a template
- Class/Instance ~ Template/Stack
- Physical Resource is the actual EC2 instance
- Create, Update or Delete Stack
CloudWatch Basics
Core supporting service within AWS which provides metric, log and event management services. Used through other AWS services for health and performance monitoring, log management and nerveless architectures
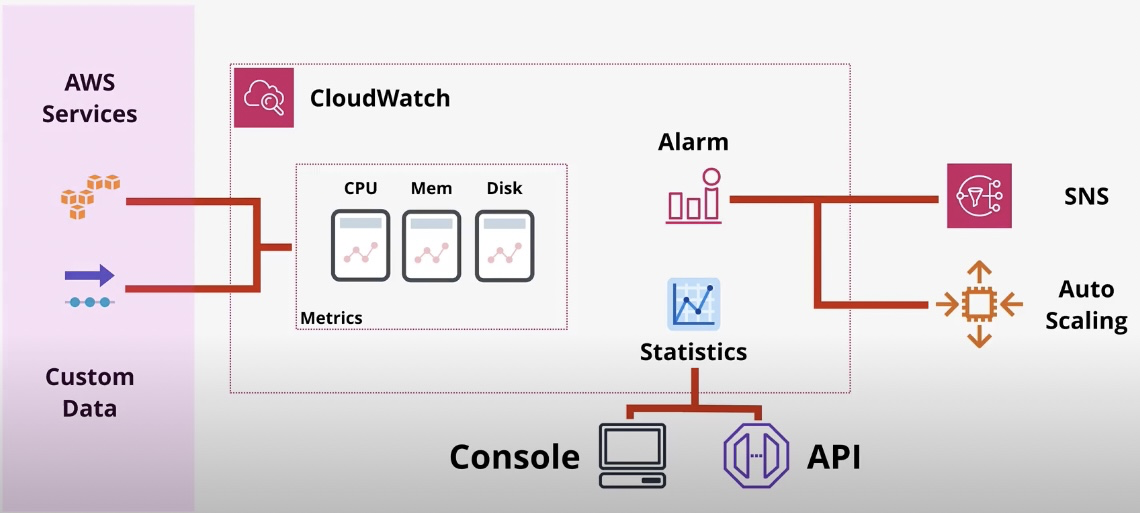
- Collects and manages operational data
- Metrics - AWS Products, Apps, on-premises
- CloudWatch Agent to monitor outside AWS
- Also to monitor certain things within certain products requires the CW Agent
- UI, API, CLI
- CloudWatch Logs - AWS Products, Apps, on-premises
- Same as above for CW Agent
- CloudWatch Events - AWS Services & Schedules
Namespace
- Can think of as a container - separate things into different areas
- Reserved: AWS/service → AWS/EC2
Metric
- Collection of Time Ordered Set of Data points
- CPU Usage, Network I/O, Disk I/O
Datapoint
- CPU Utilization Metric
- Consist of two things in its simplest form:
- Timestamp: 2019-12-03T08:45:45Z
- Value: 98.3 (% CPU utilization)
Dimension
- Dimensions separate datapoints for different things or perspectives within the same metric
- Use dimensions to look at the metric for a specific InstanceId
Alarm
- Linked to a specific metric
- Can set criteria for an alarm to move into an alarm state and further define an SNS or action
- Billing alarm is an example of this
- Three states: OK, ALARM, INSUFFICIENT DATA
Shared Responsibility Model
The Shared Responsibility Model - is how AWS provide clarity around which areas of systems security are theirs, and which are owned by the customer.
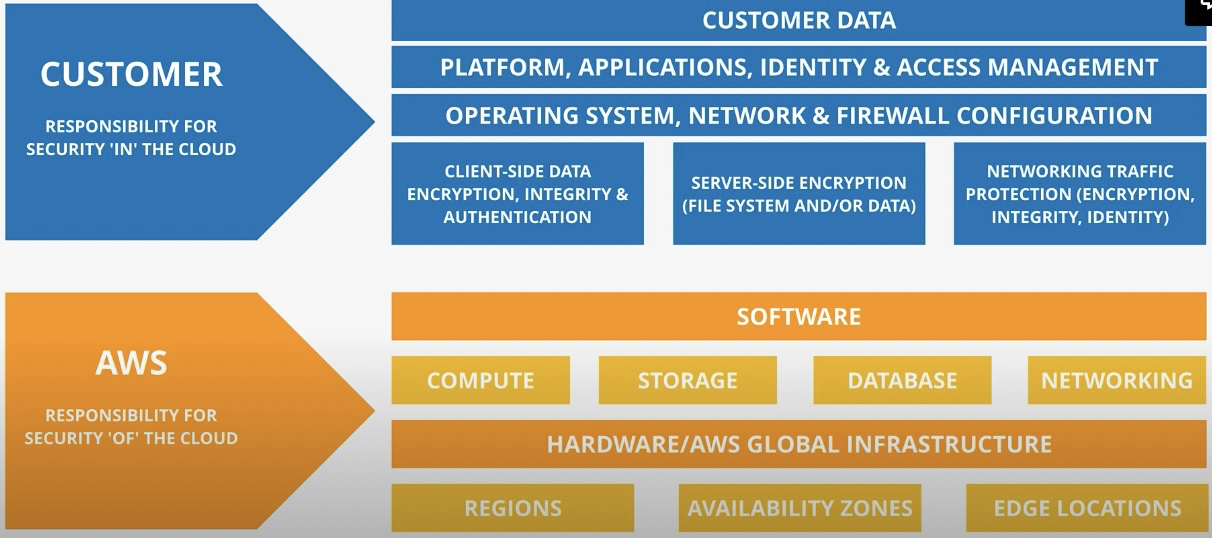
- AWS responsible for the security of the cloud
- Hardware/AWS Global Infrastructure
- Regions, AZ, Edge Locations
- Compute, Storage, Database, Networking
- Software
- Customer responsible for security in the cloud
- Client-side data encryption, integrity & authentication
- Server-side encryption (File system and/or data)
- Networking traffic protection (encryption, integrity, identity)
- OS, Network and Firewall configuration
- Platform, applications, identity and access management
- Customer Data
High-Availability (HA) vs Fault-Tolerance (FT) vs Disaster Recovery (DR)
High-Availability (HA)
Aims to ensure an agreed level of operational performance, usually uptime, for a higher than normal period. Maximizing a system’s uptime / minimize outages.
- E.g.
- 99.9% = 8.77 hours /year downtime
- 99.999% = 5.26 minutes /year downtime
- User disruption, such as re-login, is okay
- If a server goes down, but another is ready on standby, users may notice small disruptions, but thats okay
- Often require redundant service or architecture to achieve the agreed SL
Fault-Tolerance (FT)
Is the property that enables a system to continue operating properly in the event of the failure of some (one or more faults within) of its components. Operate through faults.
- High availability is not enough
- If a server goes down, disruption is not okay
- The system must be able to tolerate the failure
- Levels of redundancy and system of components which can route around failures
- Implementing FT when you need HA is expensive and is harder to implement
- Implementing HA when you need FT can be a disaster
Disaster Recovery (DR)
A set of policies, tools and procedures to enable the recovery or continuation of vital technology infrastructure and system following a natural or human-induced disaster. Used when FT and HA don’t work
- Parachute
Domain Name System (DNS) Basics
DNS 101
- DNS is a discovery service
- Distributed database
- Translates machine into human and vice-versa
- amazon.com → 104.98.34.131
- It’s huge and has to be distributed
- Zone files that can be queried
❗Remember these ❗
- DNS Client: Your laptop, phone, tablet, PC, etc.
- Resolver: Software on your device, or a server which queries DNS on your behalf
- Zone: A part of the DNS database (e.g. amazon.com)
- Zonefile: Physical database for a zone
- Nameserver: Where zonefiles are hosted
DNS Root
- Starting point of DNS
- www.amazon.com
- Read right to left
- Hosted on 13 Root servers
- Operated by 12 different large companies and organization
- Only operates the servers, not the database itself
- Each root server can be a cluster of servers
- Root Hints
- Provided by Vendor
- List of these root servers, pointer to DNS root servers
- Root Zone is operated by IANA - Internet Assigned Numbers Authority
DNS Hierarchy
- Root zone - Database of top level domains | IANA
- .com, .org, .uk, etc.
- .com zone | Verisign
- amazon.com
- NS - w.x.y.z
- amazon.com zone
- www ⇒ 104.98.34.131
Registry
- Organization that maintains the zones for a TLD
Registrar
- Organization with relationship with .org TLD zone manager allowing domain registration
DNS Resolution

❗Remember these❗
- Root hints: Config points at the root servers IPs and addresses
- Root Server: Hosts the DNS root zone
- Root zone: Point at TLD authoritative servers
- gTLD: generic Top Level Domain (.com .org etc)
- ccTLD: country-code Top Level Domain (.uk, .eu, etc)
Route53 Fundamentals
R53 Basics
- Register domains
- Host Zones … managed nameservers
- Global servers … single database
- Globally Resilient
Register domains
- Registries
- .com .io .net
- Create a zonefile
- animals4life.org
- Put zonefile to four nameservers
Hosted Zones
- Zone files in AWS
- Hosted on four managed name servers
- Can be public
- Or private … linked to VPC(s)
- Stores records (recordsets)
DNS Record Types
Nameserver (NS)
- Record types that allow delegation to occur in DNS
- .com zone
- Multiple nameserver records inside it for amazon.com
- Point at servers managed by the amazon.com team
- Multiple nameserver records inside it for amazon.com
A and AAAA Records
- Map host names to IP
- A: www → ipv4
- AAAA: → ipv6
CNAME Records
- Host to host
- ftp, mail, www (references) → A server
- Cannot point directly at an IP address, only other names
MX Records
- Important for email
- MX records are used as part of the process of sending email
- E.g. inside google.com zone
- MX 10 mail
- means mail.google.com
- MX 20 mail.other.domain.
- Fully qualified domain name
- means mail.other.domain
- Lower values for the priority field means higher priority
- MX 20 is only used if MX 10 doesn’t work
- MX 10 mail
TXT Records
- Allow you to add arbitrary text to a domain
- E.g. animals4life.org zone
- Add: TXT cats are the best
- Important to prove that you own domain (animals4life.com)
TTL - Time To Live
- TTL 3600 (seconds)
- Value configured by amazon.com admin
- Results of query stored at the resolver server for 1 hour
- Authoritative: Query results directly from amazon.com server
- Non-authoritative: If another client queries the resolver within 3600 seconds, the resolver can immediately return the results of the query
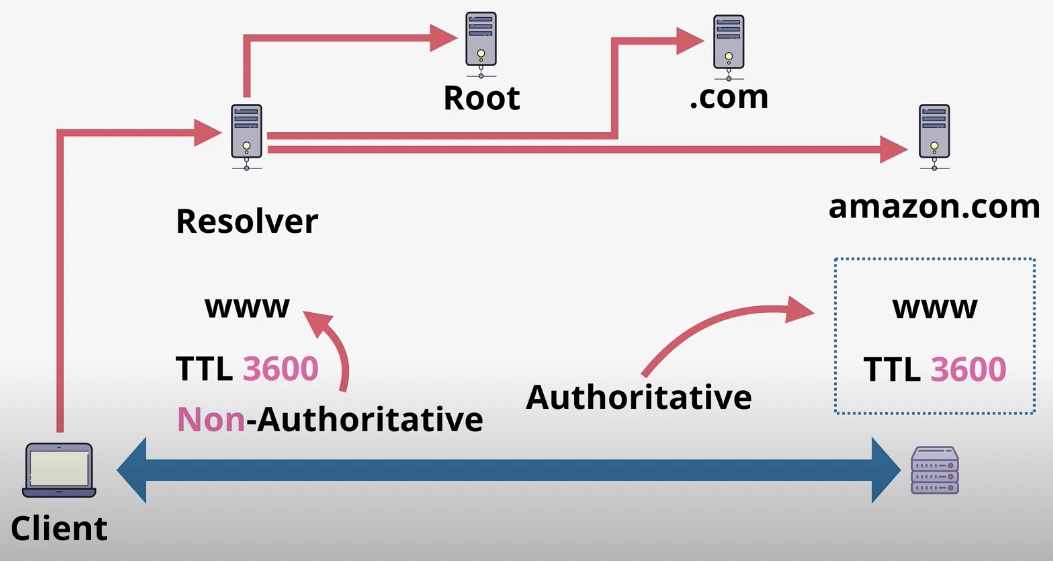
🦠 IAM, Account and AWS Organizations
IAM Identity Policies
- Users, groups and roles
- Grants access or denies access
IAM Policy Document
- At high level just one or more statements that grant or deny access
- Need to identify
- Statement only applies if the interaction with AWS match the action and the resource
- Wildcards (*) match any action
- Effect defines what to do if the action and resource match
- Often statements overlap, and you may be allowed and denied at the same time.
- Explicit denies are first priority. Deny always win.
- Priority list
- Explicit DENY
- Explicit ALLOW
- Default DENY
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Fullaccess", # StatementID
"Effect": "Allow",
"Action": ["s3:*"],
"Resource": ["*"],
},
{
"Sid": "DenyCatBucket",
"Effect": "Deny",
"Action": ["s3:*"],
"Resource": ["arn:aws:s3:::catgifs", "arn:aws:s3:::catgifs/*"],
}
]
}
Inline Policy
- Write a JSON for multiple users individually
- Bad practice for many users - have to change a lot of JSONs if there are 100 users
- Only use in special or exceptional allow or deny situations
Managed Policy
- Reusable
- Low management overhead
- Should be the default
IAM Users and ARNs
IAM Users are an identity used for anything requiring long-term AWS access e.g. humans, applications or service accounts
- Principal: Something or someone wanting access resources in AWS
- Must authenticate to gain access
- Access Keys
- Username/password
- Must authenticate to gain access
- When a principal is authenticated, it is known as a authenticated identity
- When the authenticated user tries to do an action, e.g. upload something to a S3 bucket, IAM checks that the authenticated user have access to perform that action (authorization)
Amazon Resource Name (ARN)
Uniquely identify resources within any AWS accounts
aws:partition:service:region:account-id:resource-id
aws:partition:service:region:account-id:resource-type
aws:partition:service:region:account-id:resource-type:resource-id
arn:aws:s3:::catgifs # Bucket
arn:aws:s3:::catgifs/* # Objects in bucket
# These two don't overlap. First is access to manage the bucket, second is to manage objects in bucket.
- 5000 IAM Users per account
- IAM User can be a member of 10 groups
- This has systems design impacts
- Internet-scale applications
- Large orgs and org merges
- IAM Roles and Identity Federation fix this (more later)
IAM Groups
IAM Groups are containers for Users
- Allow for easier management
- Groups can have (identity) policies attached to them
- Users can have individual (identity) policies too
- Trick question exam: “All users” group does not exist natively (but you can technically create it)
- ❗300 groups ❗
- ❗10 groups per user ❗
- No nesting
- Resource policies (e.g. for a bucket) can allow one or more specific user to allow access
- Resource policies cannot grant access to a group!
- Further, cannot be referenced from a resource policy at all
IAM Roles
*An IAM role is an IAM identity that you can create in your account that has specific permissions. An IAM role is similar to an IAM user, in that it is an AWS identity with permission policies that determine what the identity can and cannot do in AWS. However, instead of being uniquely associated with one person, a role is intended to be assumable by anyone who needs it. Also, a role does not have standard long-term credentials such as a password or access keys associated with it. Instead, when you assume a role, it provides you with temporary security credentials for your role session.
-* https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles.html
- Role best suited for unknown number of principals or more than 5000 users
- IAM Roles are assumed. You become that role.
- ❗**Two types of policy for a role:**❗
- Trust policy
- Permissions policy
- If a role is assumed by something that is allowed to assume it, temporary security credentials are created.
- ❗STS: Secure Token Service ❗
- Generates the security tokens
- sts:AssumeRole
- Permissions policy define what they have access to
- When they expire the role has to be assumed again to regain access
- ❗STS: Secure Token Service ❗
❓When to use IAM Roles
- Most common use case is for other AWS services
- E.g. AWS Lambda
- No permissions by default
- Lambda Execution Role
- Runtime environment assumes the role.
- Better to use a role than to hardcode access keys to the Lambda function
- Emergency or unusual situations
- E.g. team with read-only access:
- 99% read-only access is OK
- “Break glass for key”
- User of team can assume an emergency role to perform a certain write action
- A corporation with > 5000 ids
- ID federation
- Can allow an organization to use previous existing accounts for SSO (Active Directory)
- AD users are allowed to assume a role to gain access to e.g. a bucket
- App with millions of users
- Web Identity Federation
- Users might need to interact with a DynamoDB
- Users are allowed to assume a role to interact with the db
- No AWS credentials on the app
- Uses existing customer logins (twitter, fb, google)
- Scales to large number of accounts
- Cross AWS accounts
Service-linked Roles & PassRole
A service-linked role is a unique type of IAM role that is linked directly to an AWS service. Service-linked roles are predefined by the service and include all the permissions that the service requires to call other AWS services on your behalf. The linked service also defines how you create, modify, and delete a service-linked role. A service might automatically create or delete the role. It might allow you to create, modify, or delete the role as part of a wizard or process in the service. Or it might require that you use IAM to create or delete the role.
- IAM role linked to a specific AWS service
- Predefined by a service
- Providing permissions that a service needs to interact with other AWS services on your behalf
- Or allow you to during the setup or within IAM
- You can’t delete the role until it’s no longer required
- PassRole: Grant a user permission to pass a role to an AWS service
- Bad: Bob may create and assign a role to a AWS service that has permissions that exceeds the permissions that Bob has himself
- E.g. create resources
- Good: Bob cannot assign roles with permissions that exceeds his own
- Bad: Bob may create and assign a role to a AWS service that has permissions that exceeds the permissions that Bob has himself
AWS Organizations
Suitable for organization with multiple AWS accounts
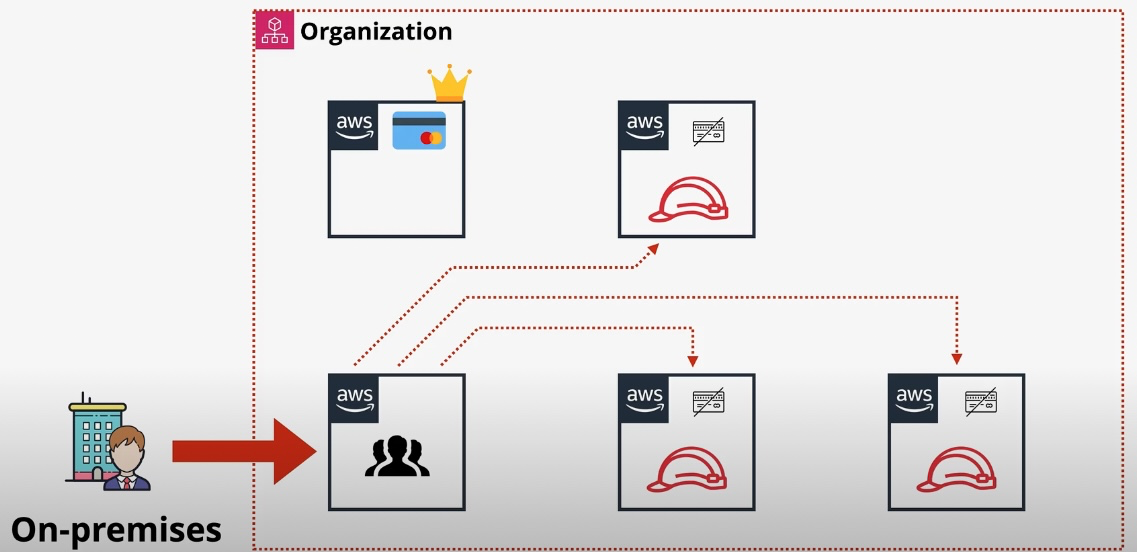
- Use a standard AWS account to create a AWS organization
- This account will be the management account or master account - can only be one
- The organization is not within the AWS account
- Invite other standard accounts into the organization
- Organization Root is a container within AWS Organization which contains either other AWS account or other organizational units
- Consolidated billing: Member accounts pass their billing to the payment/management/master account
- Removes financial overhead
- Consolidation of reservation and volume discounts
- Two important concepts of AWS Organizations:
- In a organization you can create accounts directly within the organization - one step process instead of invitation
- Don’t need to have IAM Users inside every AWS account. IAM Roles can be used. Can role switch into different accounts.
Service Control Policies (SCP)
JSON doc with policies. Can be attached to organizations as a whole. Cascade to all orgs below that which it is attached to. Management account is special and is unaffected by SCP!
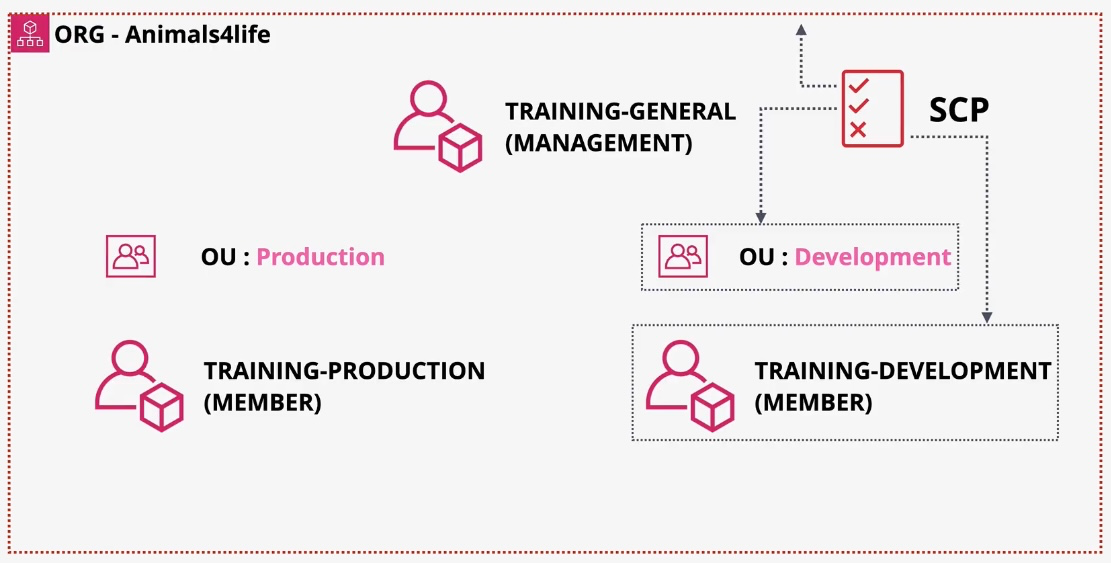
- SCPs are account permissions boundaries
- They limit what the account (including account root user) can do
- SCPs can e.g. limit the size of an EC2 instance within a specific region
- SCPs don’t grant any permissions!
- Allow list vs Deny list
- Default is a deny list
- FullAWSAccess Default for new account
- DenyS3 - Deny S3 to organizations - even though they have FullAWSAccess (deny, access, deny)
- To implement allow list:
- Remove FullAWSAccess - add a new list: AllowS3EC2
- Explicit say which services are allowed
- More overhead, may block access to services you don’t intend to block
- Remove FullAWSAccess - add a new list: AllowS3EC2
- Best practice is deny list architecture
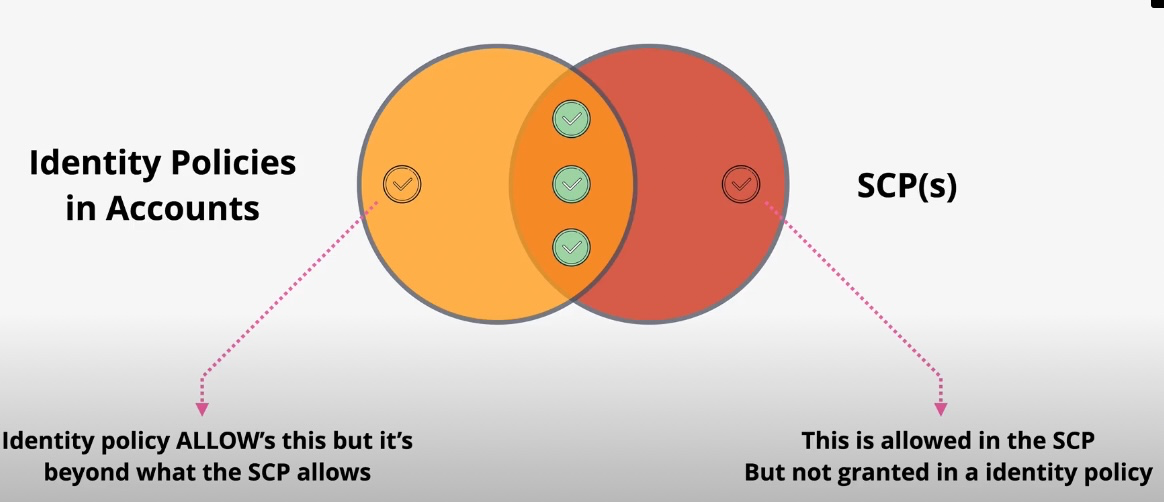
CloudWatch Logs
CloudWatch Logs is a service which can accept logging data, store it and monitor it. It is often the default place where AWS Services can output their logging too. CloudWatch Logs is a public service and can also be utilized in an on-premises environment and even from other public cloud platforms.
💡 Public Service: Usable from AWS or on-premises
- Store, Monitor and access logging data
- AWS Integrations - EC2, VPC Flow logs, Lambda, CloudTrail, R53 and more
- Metric filter: Can generate metrics based on logs
- Regional service
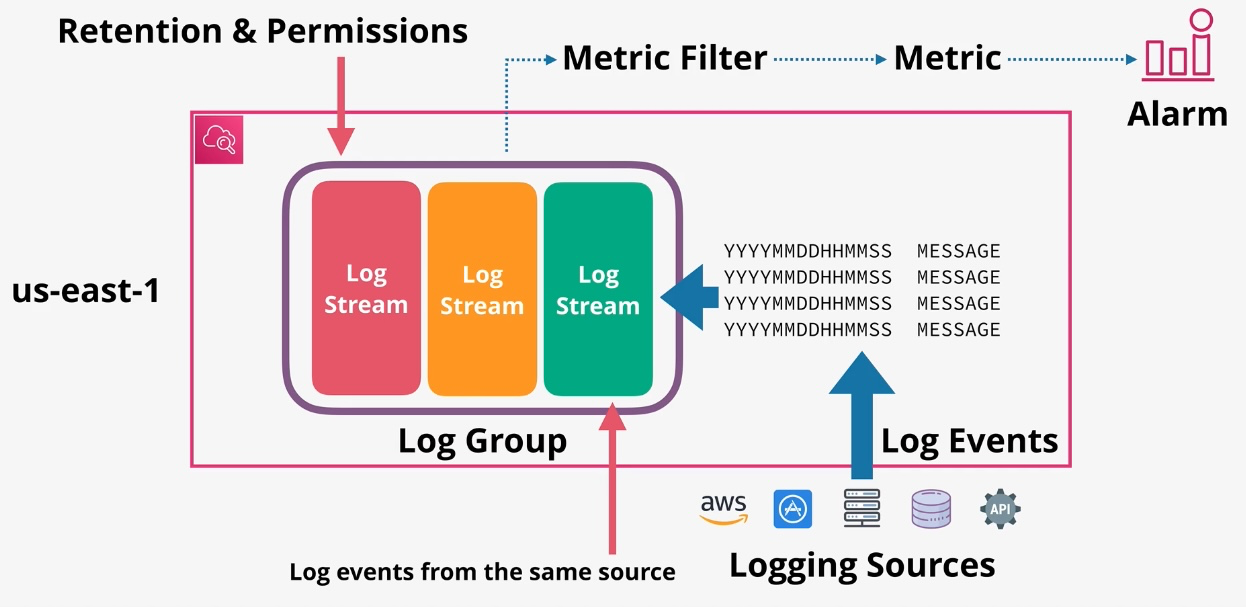
CloudTrail Essentials
CloudTrail Basic
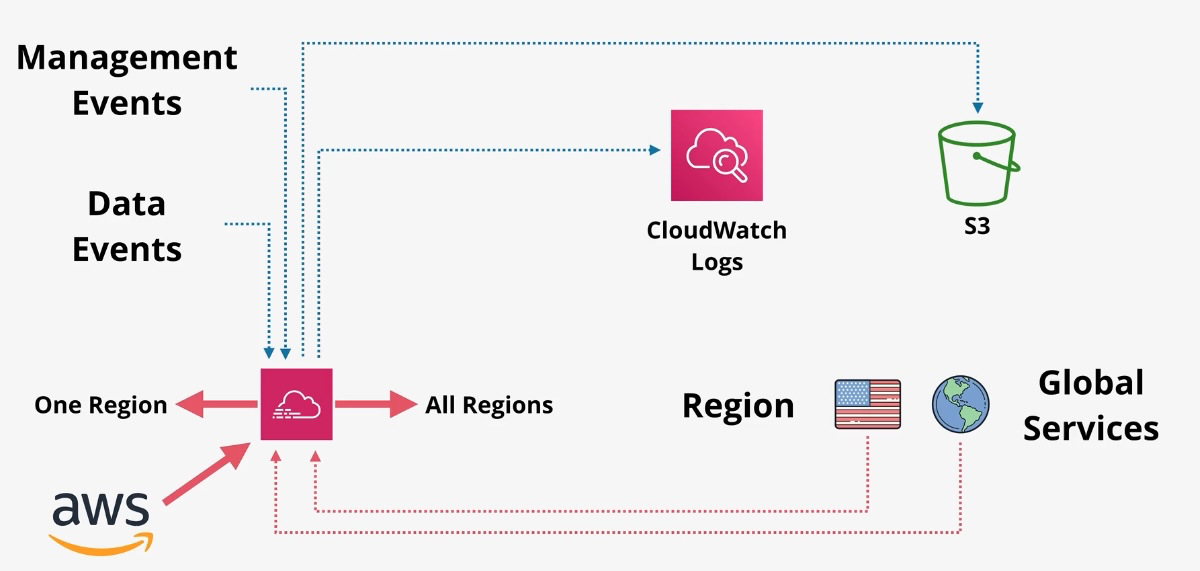
- Logs API calls/activities as a CloudTrail Event
- 90 days stored by default in Event History
- Enabled by default - no cost for 90 day history. No S3.
- To customize the service, create one or more Trails
- Management events
- Provide information about management operation that are performed on resources in your AWS account
- AKA Control Plane Operations
- Create EC2 instance etc
- Enabled by default ❗
- Data events
- Objects being uploaded to S3
- Lambda being invoked
- Not enabled by default. Come at an extra cost. ❗
- Trails can be set to one region or all regions
- Organizational trail - it is what it sounds like
- Trails are how you configure S3 and CWLogs.
- Management event only by default
- IAM, STS, CloudFront → Global Service Events
- Only these logs global
- NOT REALTIME - There is a delay
- Typical 15 minutes ❗
AWS Control Tower
*AWS Control Tower offers a straightforward way to set up and govern an AWS multi-account environment, following prescriptive best practices. AWS Control Tower orchestrates the capabilities of several other AWS services, including AWS Organizations, AWS Service Catalog, and AWS IAM Identity Center (successor to AWS Single Sign-On), to build a landing zone in less than an hour. Resources are set up and managed on your behalf.
AWS Control Tower orchestration extends the capabilities of AWS Organizations. To help keep your organizations and accounts from drift, which is divergence from best practices, AWS Control Tower applies preventive and detective controls (guardrails). For example, you can use guardrails to help ensure that security logs and necessary cross-account access permissions are created, and not altered.*
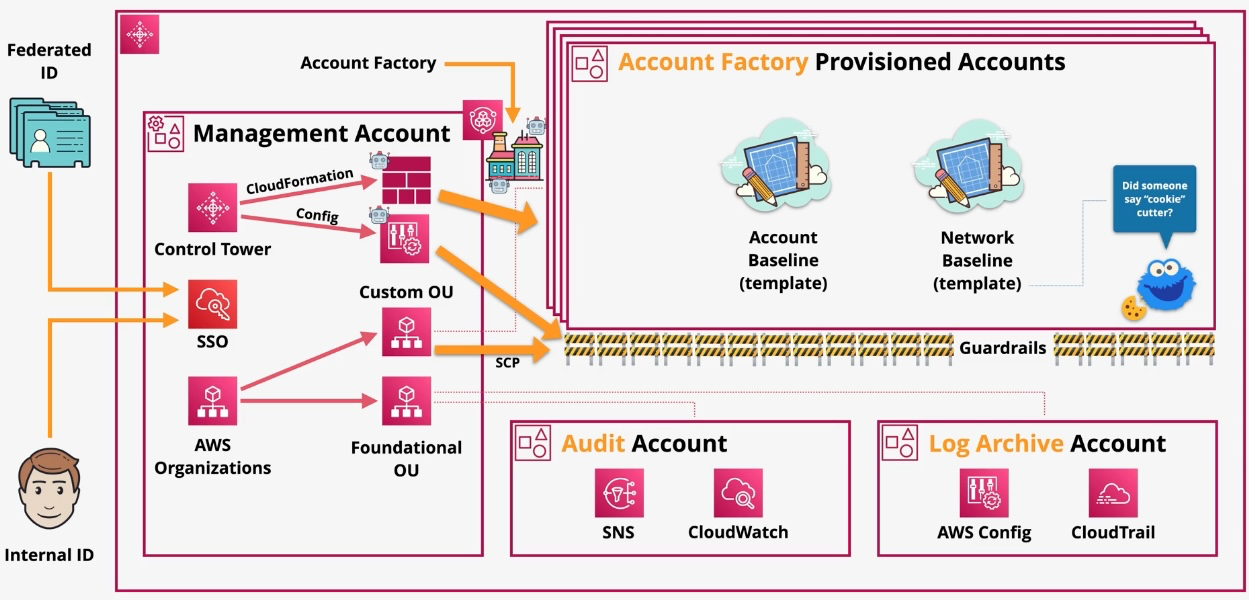
- Quick and easy setup of multi-account environment
- Orchestrates other AWS services to provide this functionality
- Organizations, IAM Identity Center, CloudFormation, Config and more
- Landing Zone - multi-account environment
- SSO/ID Federation, Centralized Logging and Auditing
- Guard Rails - Detect/Mandate rules/standard across all accounts
- Account Factory - Automates and standardizes new account creation
- Dashboard - single page oversight of the entire environment
Landing Zone
- Well Architected multi-account environment. Home region.
- Built with AWS Organizations, AWS Config, CloudFormation
- Security OU (Organizational Unit) - Log Archive and Audit Accounts (CloudTrail & Config Logs)
- Sandbox OU - Test/less rigid security
- You can create other OU’s and Accounts
- IAM Identity Center (AWS SSO) - SSO, multiple-accounts, ID Federation
- Monitoring and Notifications - CloudWatch and SNS
- End User account provisioning via Service Catalog
Guard Rails
- Guardrails are rules for multi-account governance
- Mandatory, strongly recommended or elective
- Preventive - Stop you doing things (AWS ORG SCP)
- Enforced or not enabled
- i.e. allow or deny regions or disallow bucket policy changes
- Detective - compliance checks (AWS CONFIG Rules)
- Clear, in violation or not enabled
- Detect CloudTrail enabled or EC2 Public IPv4
Account Factory
- Automated Account Provisioning
- Cloud admins or end users (with appropriate permissions)
- Guardrails - automatically added
- Account admin given to a named user (IAM Identity Center)
- Account & network standard configuration
- Account can be closed or repurposed
- Can be fully integrated with a business SDLC (Software Development Life Cycle)
💾 Simple Storage Service S3
S3 Security
S3 is private by default
S3 Bucket Policies
-
A form of resource policy ❗
-
Like identity policies, but attached to a bucket
-
Resource perspective permissions
-
ALLOW/DENY same or different accounts
-
ALLOW/DENY anonymous principals
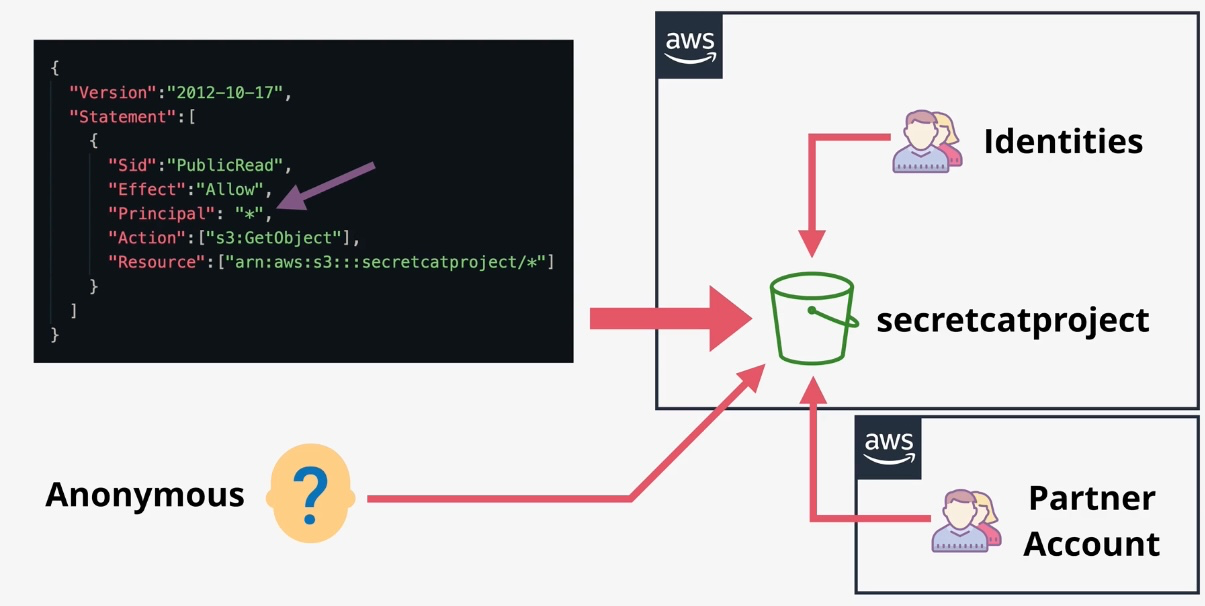
Access Control Lists (ACLs)
- ACLs on objects and bucket
- A subresource
- **LEGACY!**❗
- Inflexible and simple permissions
Block Public Access
- Fail safe
Summary
- Identity: Controlling different resources
- Identity: You have a preference for IAM
- Identity: Same account
- Bucket: Just controlling S3
- Bucket: Anonymous or Cross-Account
- ACLs: Never - unless you must
S3 Static Hosting
Static Website Hosting
- Normal access is via AWS APIs
- This feature allows access via HTTP - e.g. Blogs
- Index and Error documents are set
- Website Endpoint is created
- Custom Domain via R53 - Bucket name matters!
- Offloading: Large data files such as pictures can be saved in a static S3 bucket to offload the page being accessed
- Out-of-band pages: During maintenance of a server, configure DNS to point at an error HTML page hosted at static S3.
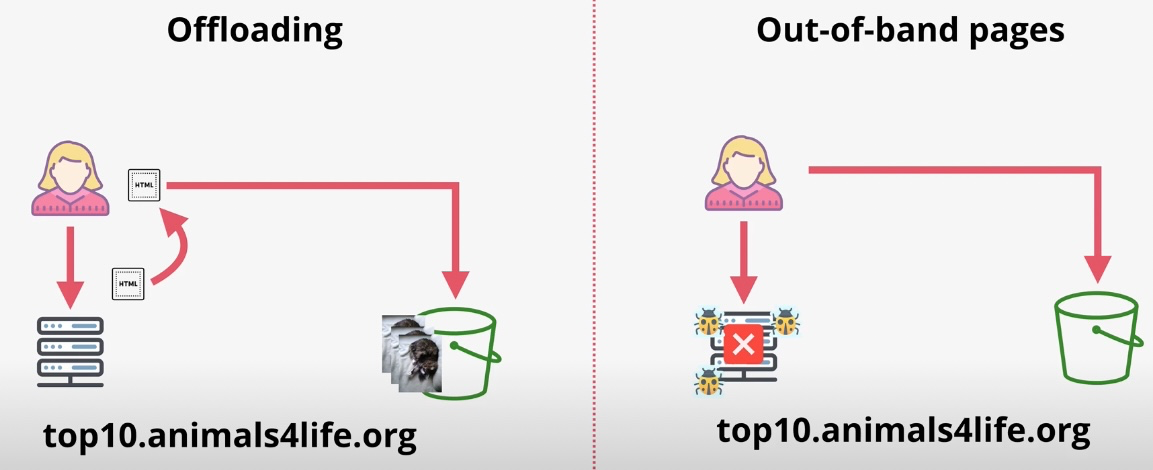
S3 Pricing
- Per GB month charge ❗
- Every GB in is free ❗
- Every GB out of S3 is charged ❗
- GET, PUT, POST etc pricing per 1000 requests ❗
Object Versioning & MFA Delete
Once enabled, you can never disable it again! Can be suspended and reenabled. Versioning lets you store multiple versions of objects within a bucket. Operations which would modify objects generate a new version.
Almost guaranteed to feature on the exam ❗
- Without versioning each object is identified by their key
- With versioning disabled on an object, the id of the object is set to null
- If an object is requested without specifying the id, you always retrieve the latest object
- If we delete an object without specifying id, the objects is not actually deleted but it adds a delete marker.
- Delete markers can be deleted
- To fully delete you must provide the id of the object you delete
- OBJECT VERSIONING CANNOT BE SWITCHED OFF
- Space is consumed by all versions
- You are billed for all versions
MFA Delete (Multi-Factor Authentication)
- Enabled in versioning configuration
- MFA is required to change bucket versioning state
- MFA is required to delete versions
- Serial number (MFA) + Code passed with API CALLS
S3 Performance Optimization
Single PUT Upload
- Single data stream to S3
- Stream fails - upload fails
- Requires full start
- Speed & reliability = limit of 1 stream
- Any upload to to 5 GB
Multipart Upload
- Data is broken up
- Min data size 100 MB
- 10 000 max parts, 5MB → 5GB ❗
- Parts can fail, and be restarted
- Transfer rate = speed of all parts
S3 Accelerated Transfer (Off)
- Uses the network of edge locations
- Default turned off
- Some restrictions to enable it
- Transfers data via the AWS network - more efficient than public internet
- Lower, consistent latency
- The worse the initial connection, the bigger the gain of uses accelerated transfer
Key Management Service (KMS)
Regional & Public Service Create, Store and Manage Keys Symmetric and Asymmetric Keys Cryptographic operations (encrypt, decrypt &…) Keys never leave KMS - Provides FIPS 140-2 (L2)
KMS Keys
- Consider it a container
- Logical - ID, date, policy, desc & state
- … backed by physical key material
- Generated or imported
- KMS Keys can be used for up to 4KB of data
- Everything on disk is encrypted, never in plaintext form ❗
- May be in plaintext in memory ❗
KMS and KMS Keys
CMK - Customer Managed Keys
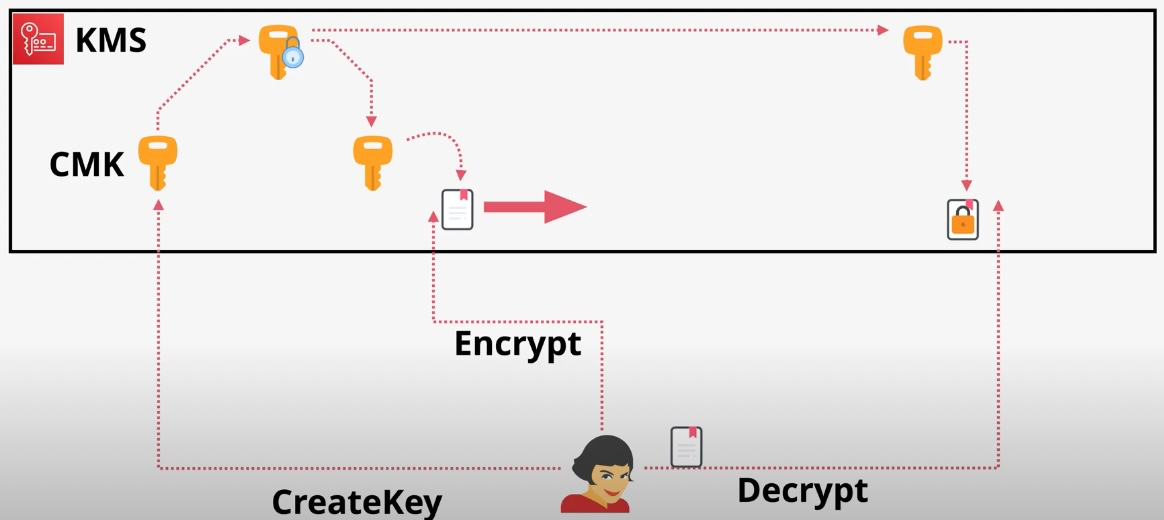
Data Encryption Keys (DEKs)
- GenerateDataKey - works on > 4KB
- Plaintext Version → Lock (Encrypt data)
- Ciphertext Version → Unlock (Decrypt data)
- Encrypt data using plaintext key
- Discard plaintext version
- Store encrypted key with data
Key Concepts
- KMS Keys are isolated to a region and lever leave
- Multi-region keys exist
- AWS Owned & Customer Owned
- Customer Owned: AWS Managed og Customer Managed KEYS
- Customer Managed keys are more configurable
- KMS Keys support rotation
- Backing Key (and previous backing keys)
- Aliases
Key Policies and Security
- Key Policies (Resource)
- Every KEY has one
- Key Policies + IAM Policies
- Key Policies + Grants
{
"Sid": "Enable IAM User Permissions",
"Effect": "Allow",
"Principal": {"AWS": "arn:aws:iam:1122334455:root"},
"Action": "kms:*",
"Recource": "*"
}
{
"Version": "2012-10-17",
"Statement": {
"Effect":"Allow",
"Action": [
"kms:Encrypt",
"kms:Decrypt"
]
"Resource": [
"arn:aws:kms:*:1122334455:key/*"
]
}
}
S3 Encryption
Buckets aren’t encrypted. Objects are!
- Client-Side Encryption
- Encrypted by client before upload
- Keys, process, tooling
- Server-Side Encryption
- Objects themselves aren’t encrypted. Reaches S3 in plaintext, and is then encrypted.
Server-Side Encryption (SSE-C , SSE-S3 and SSE-KMS)
- Server-Side Encryption with Customer-Provided Keys (SSE-C)
- Customer is responsible for keys used to encrypt/decrypt
- S3 manages the actual encryption - no CPU requirement on client, but still need to manage the actual keys ❗
- When uploading an object, provide object and key ❗
- Encrypted objects is stored on S3
- To decrypt you must provide a key to decrypt and specify the object you wish to retrieve
- Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3) [AES256]
- AWS Manages encryption & keys
- S3 creates a root key
- Creates a key thats unique for every object
- This key encrypts plaintext object, then root key is used to encrypt that key
- Original unencrypted version of this key is discarded
- ?Root key decrypts unique key, that is again used to decrypt object?
- Cons:
- No access to keys
- No control over rotation of keys
- No role separation
- Server-Side Encryption with KMS KEYS Stored in AWS KMS (SSE-KMS)
-
Root key is handled by KMS
-
The KMS key is used to generate a unique key for every object that is encrypted using SSE-KMS
-
You are not restricted to use the KMS Key provided på AWS. You can use your own customer-managed KMS key.
- You can control permissions and rotation
-
Role separation! S3 admin with full access can’t see the unencrypted version of objects - need access to the KMS key
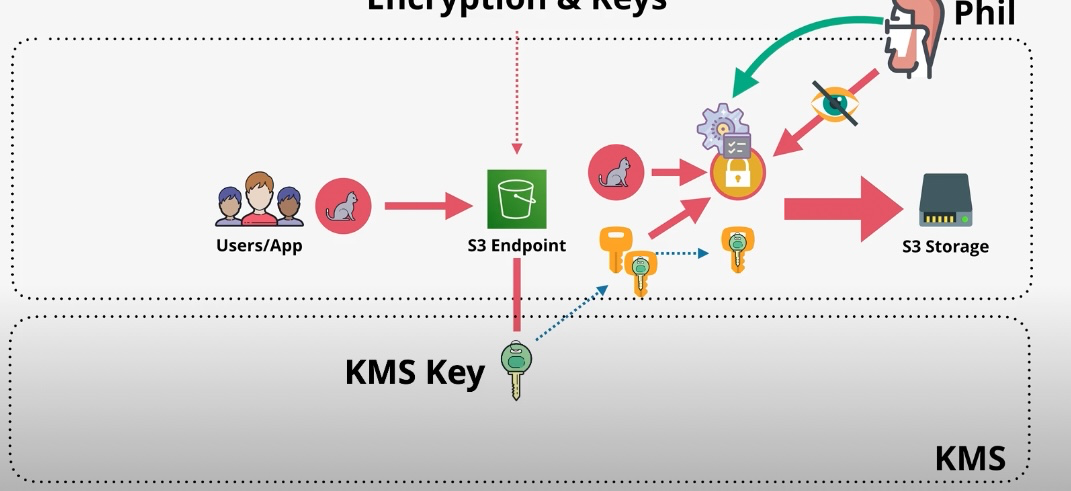
| Method | Key Management | Encryption Processing | Extras | | | | | | | Client-Side | You | You | | | SSE-C | You | S3 | | | SSE-S3 | S3 | S3 | | | SSE-KMS | S3 & KMS | S3 | Rotation Control Role Separation |
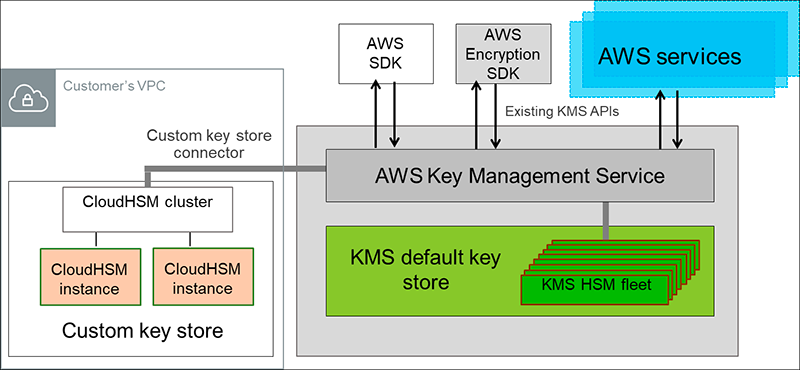
Bucket Default Encryption
- PUT operation when uploading
- header
- x-amz-server-side-encryption : “AES256” eller “aws:kms”
- How you specify to use S3 encryption
- AES-256: SSE-S3
- aws:kms : SSE-KMS
- x-amz-server-side-encryption : “AES256” eller “aws:kms”
- Can set a default for a bucket when you don’t specify this header
- Can also restrict what encryption is possible on a bucket
-
S3 Object Storage Classes
S3 Standard
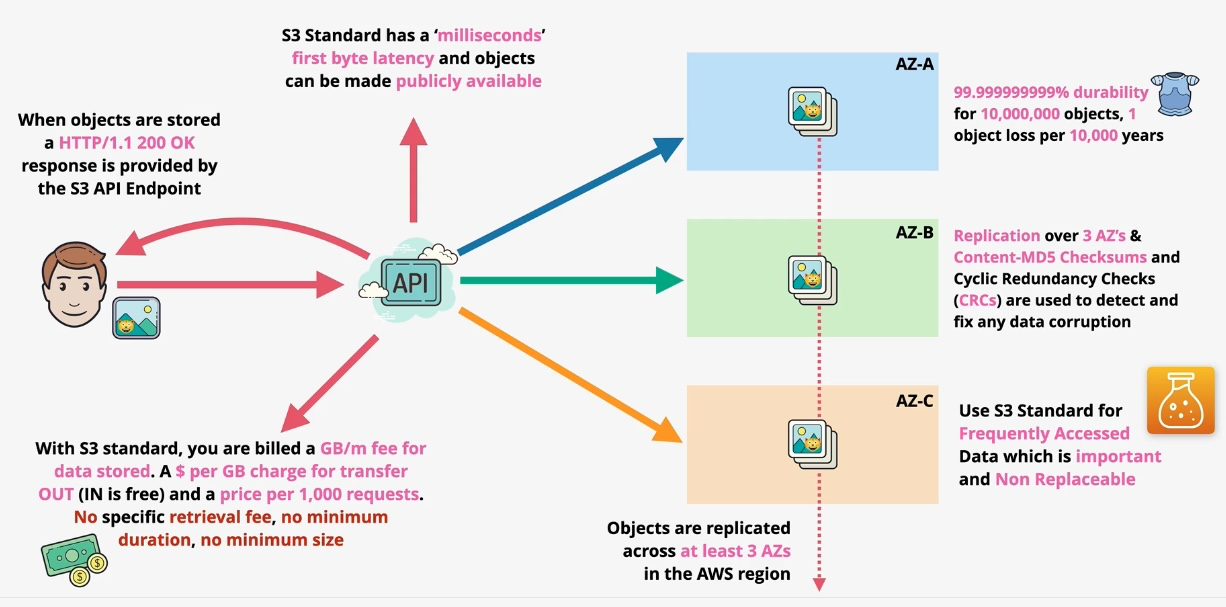
S3 Standard-IA (Infrequent Access)
Cheaper! But, retrieval fee. Overall cost increases with frequent access.
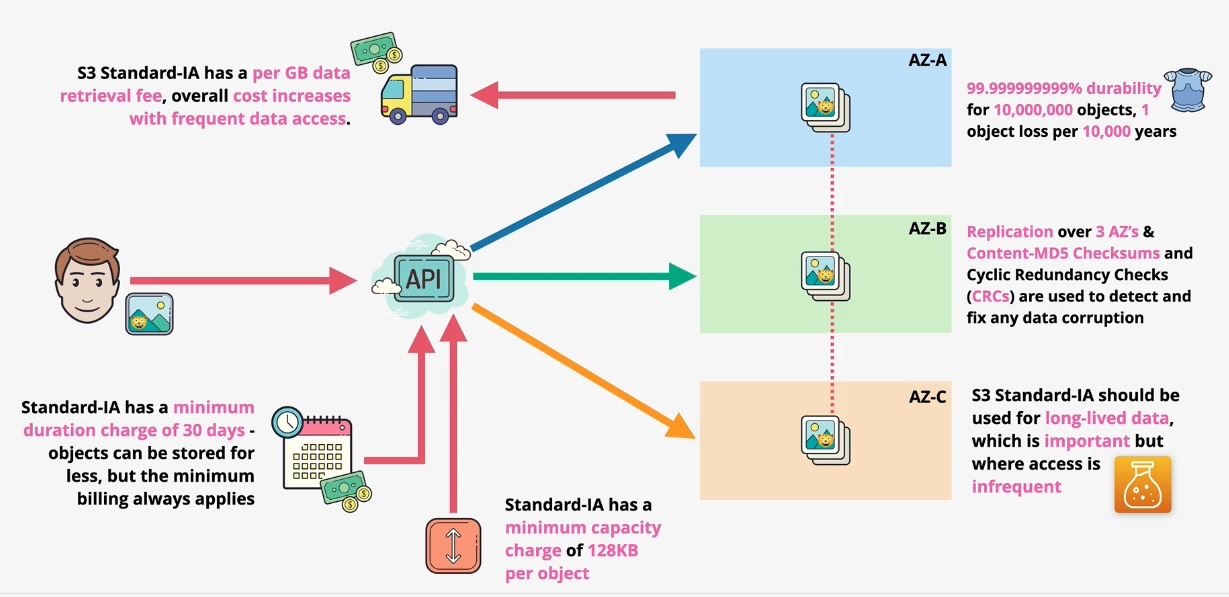
S3 One Zone-IA
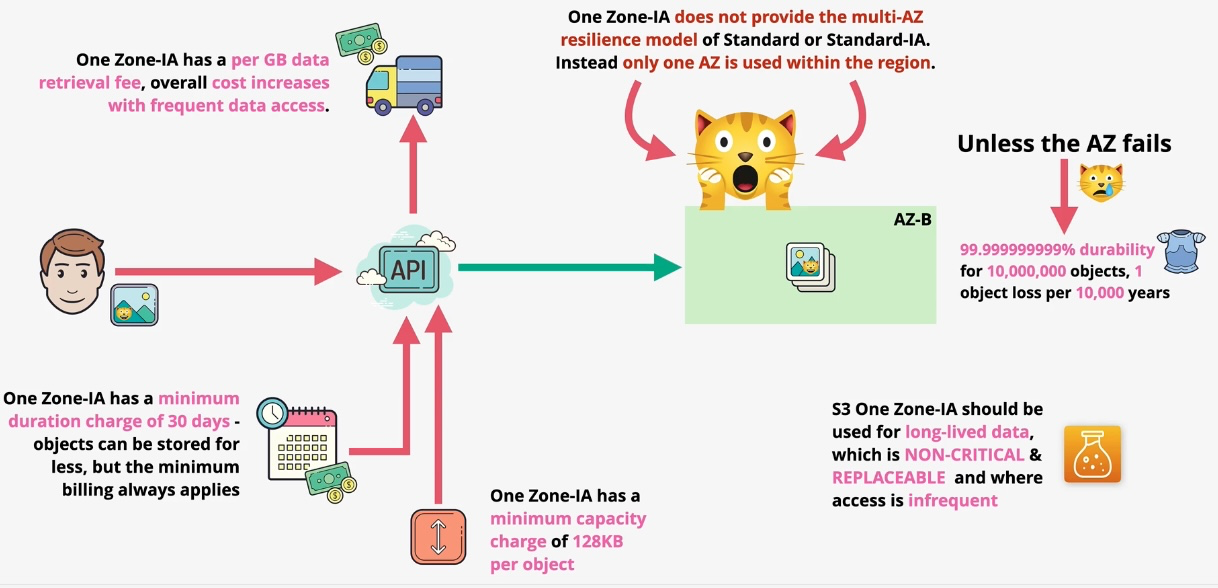
S3 Glacier Instant
Like S3 Standard-IA… cheaper storage, more expensive retrieval, longer minimum
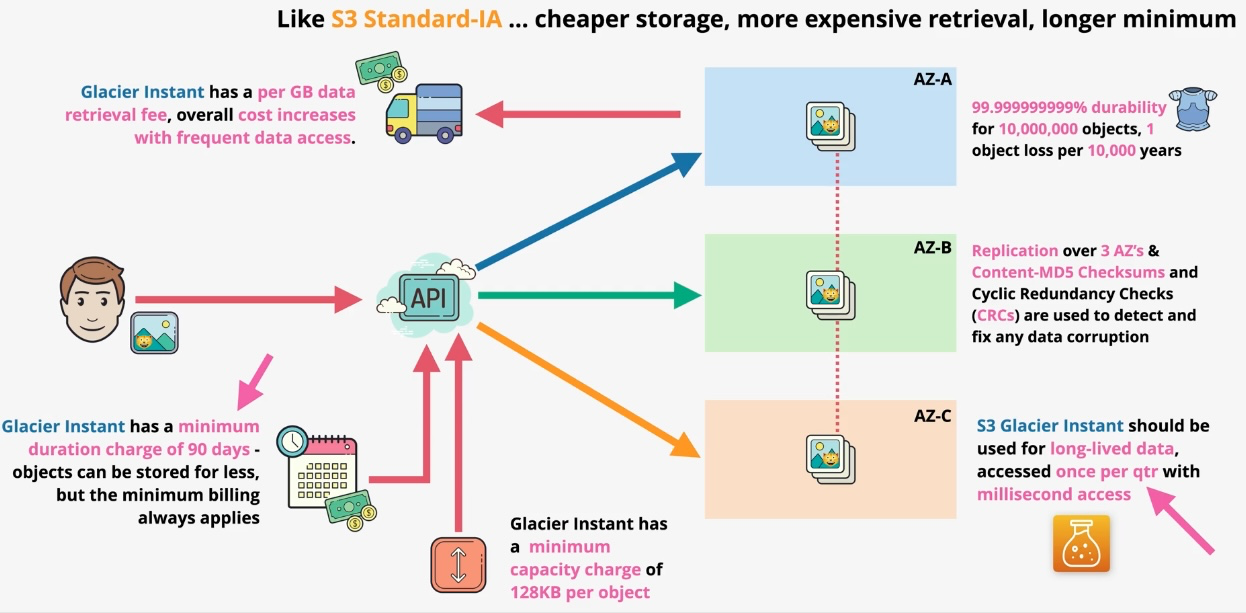
S3 Glacier Flexible
Cold objects Objects cannot be made publicly accessible. Any Access of data requires a retrieval process.
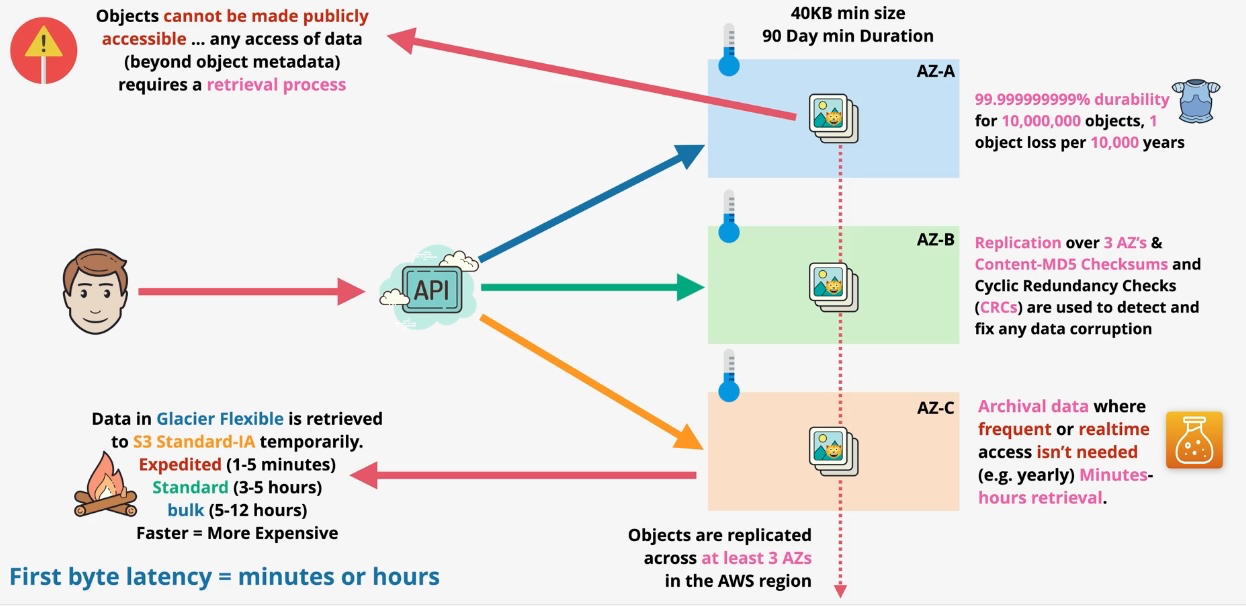
S3 Glacier Deep Archive
Cheapest alternative. LONG time to retrieve - hours to days.
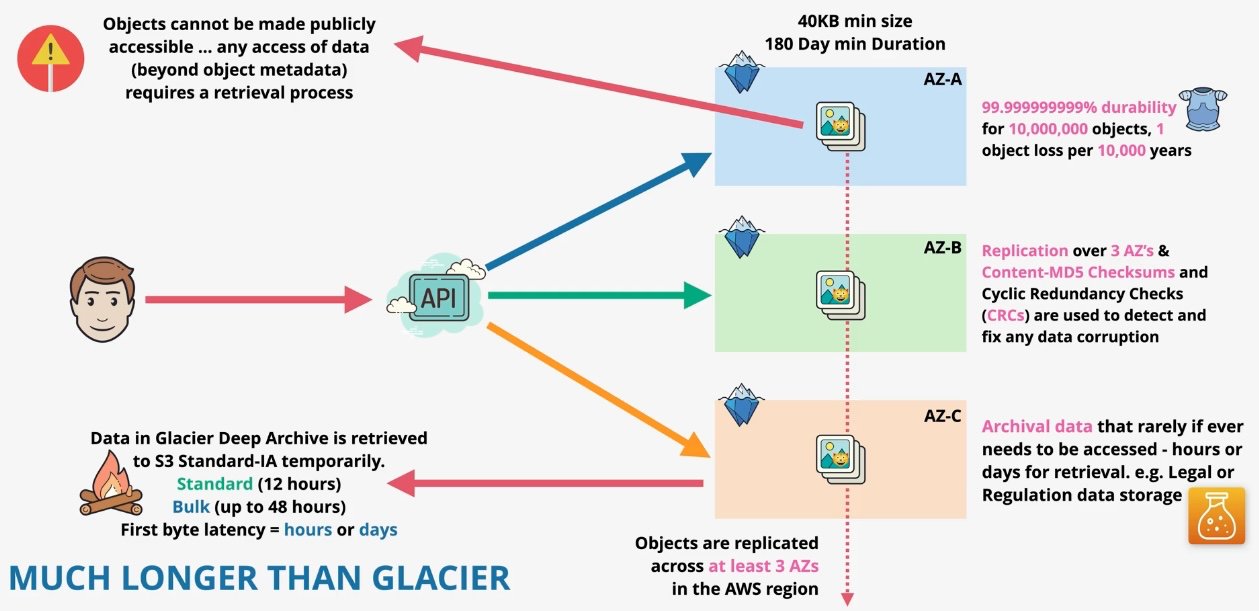
S3 Intelligent-Tiering
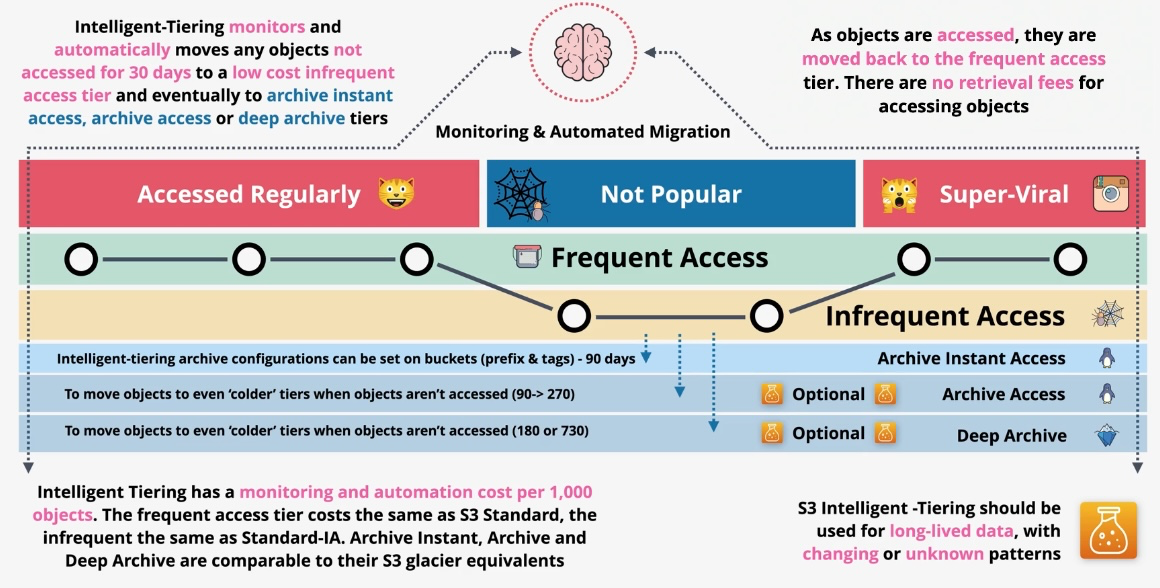
S3 Lifecycle Configuration
Automatically transition or expire objects in a bucket. Optimize costs.
- A lifecycle configuration is a set of rules
- Rules consist of actions
- on a bucket or groups of objects
- Transition actions
- e.g. to S3 Glacier
- Expiration actions
- Delete object(s) after a certain time
Transitions
Sort of waterfall between the S3 Storage Classes
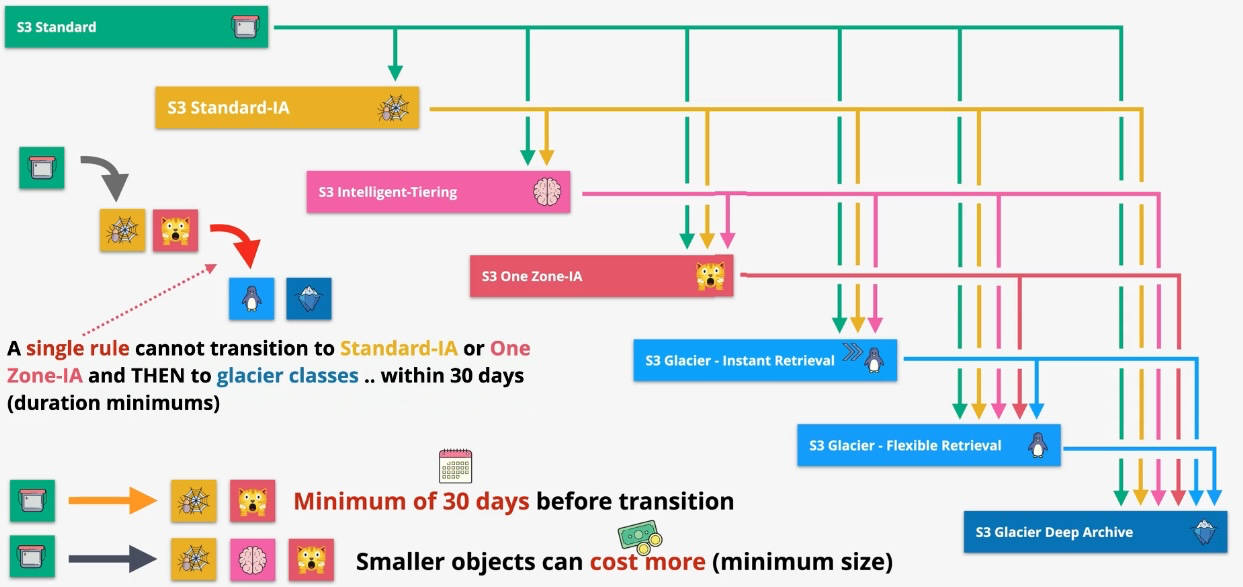
S3 Replication
- CRR: Cross-Region Replication
- Replicate buckets across regions
- Same-Region Replication:
- Replicate buckets within the same region
- Only differ by whether they are in the same or different account
- For different accounts:
- Role is not trusted by default since its configured by another account
- Add bucket policy to allow role
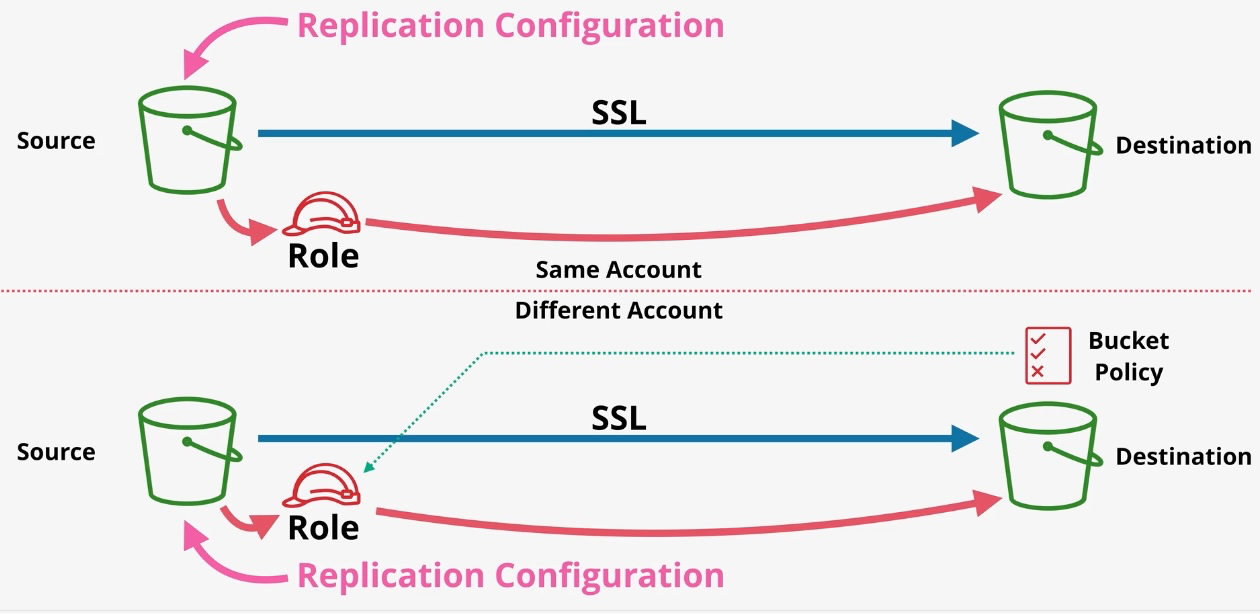
S3 Replication Options
- All objects or a subset
- Storage Class - default is to maintain
- Ownership - default is the source account
- Can override such that destination account is the owner
- RTC: Replication Time Control
- Make sure that buckets are in sync
- 15 minutes
S3 Replication Considerations
-
Not retroactive! Versioning needs to be ON
-
One-way replication: Source to destination
- Objects added to destination wont be added to source
-
Unencrypted, SSE-S3 & SSE-KMS (with extra config)
- Not SSE-C! ❗
-
Source bucket owner needs permissions to objects
-
No system events, Glacier or Glacier Deep Archive
- Lifecycle actions wont be replicated at destination
- Can’t replicate any objects within Glacier+
-
NO DELETES
- Delete markers are not replicated
- Not enabled by default
Why use replication?
SSR: Same Region Replication CRR: Cross Region
- SSR - Log Aggregation
- SSR - Prod and Test Sync
- SSR - Resilience with strict sovereignty
- CRR - Global Resilience Improvements
- CRR - Latency Reduction
S3 Presigned URLs
Give another person or application access to a object in a bucket using your credentials in a safe way!
- Expire at a certain time
- Person using URL is acting as the person who created the presigned URL
- PUT, GET
- Offload media to S3
- You can create a URL for an object you have no access to
- Few use cases, but possible
- When using the URL, the permissions match the identity which generated
- Access denied could mean the generating ID never had access, or doesn’t now
- Don’t generate with a role! URL stops working when the temporary credentials expire.

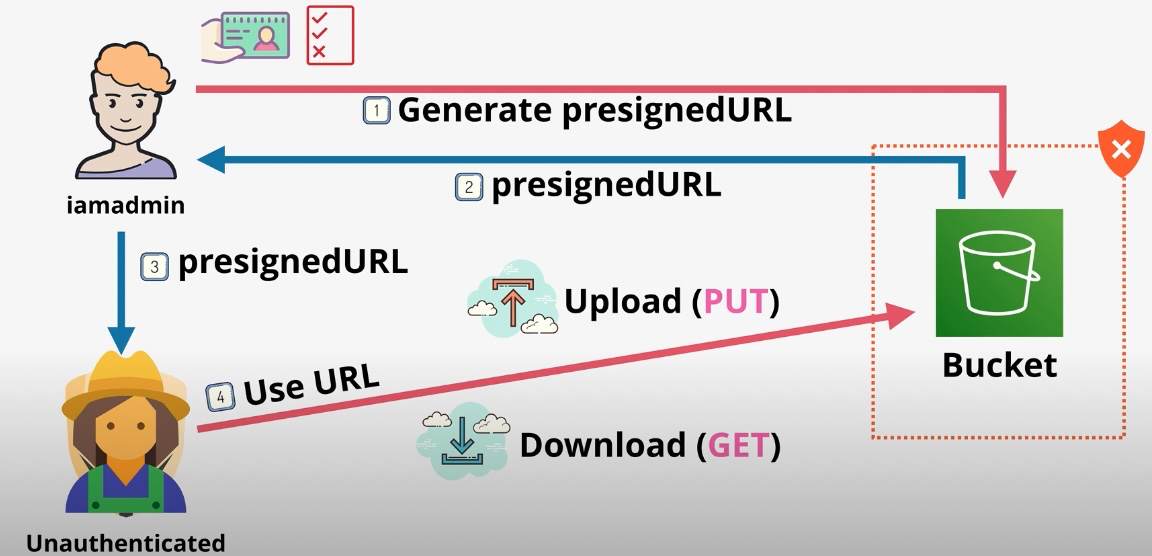
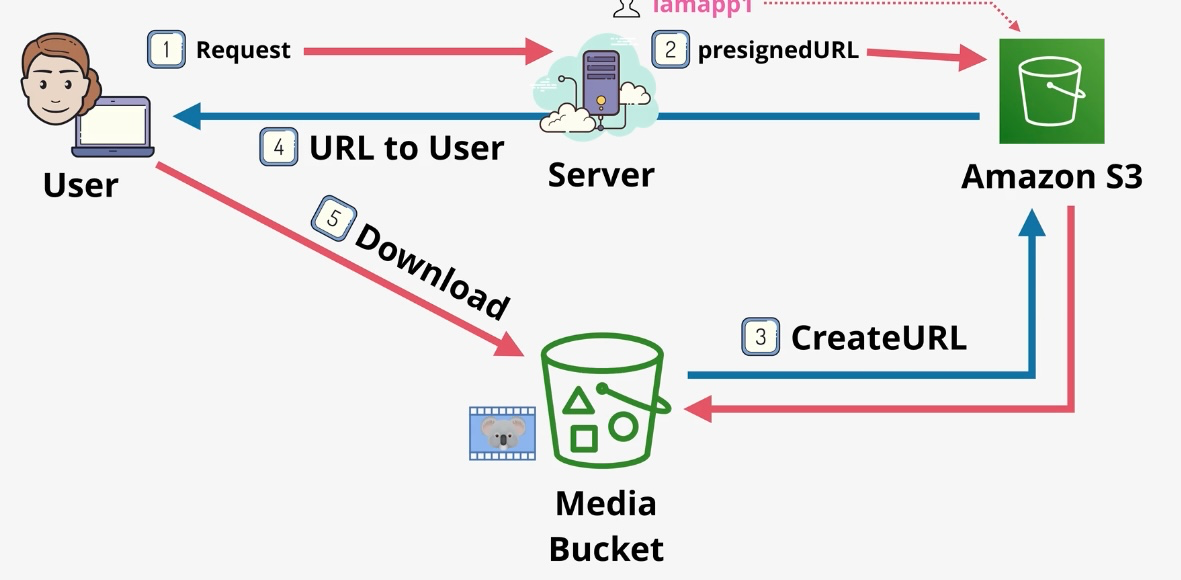
S3 Select and Glacier Select
Ways to retrieve parts of objects rather than the object. SQL-Like statement
- S3 can store objects up to 5 TB
- You often want to retrieve the entire objects
- S3/Glacier select let you use SQL-Like statements
- select part of the object, pre-filtered by S3
- CSV, JSON, Parquet, BSZIP2 compression for CSV and JSON
Architecture
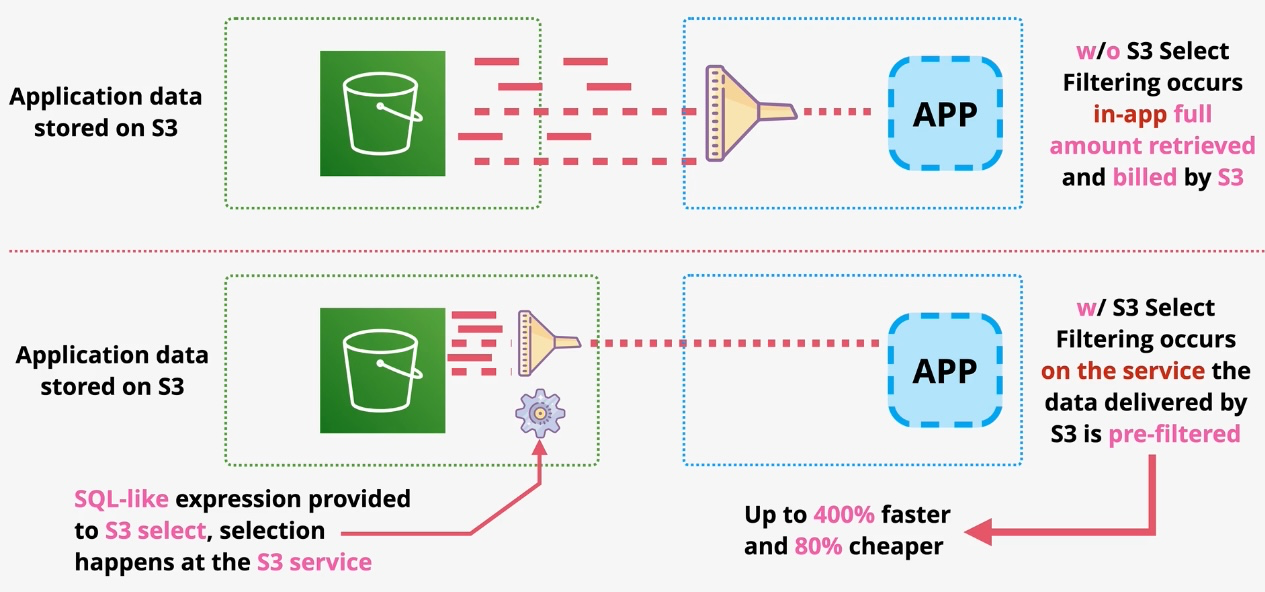
S3 Events
Receive notifications when certain events happen in your bucket
S3 Notifications
- Notification generated when events occur in a bucket
- can be delivered to SNS, SQS and Lambda functions
- Object Created (Put, Post, copy, CompleteMultiPartUpload)
- Object Delete (*, Delete, DelteMarkedCreated)
- Object Restore (Post(Initiated), Completed)
- Replication
- Use EventBridge as default!
- Newer and adds support for more services and events
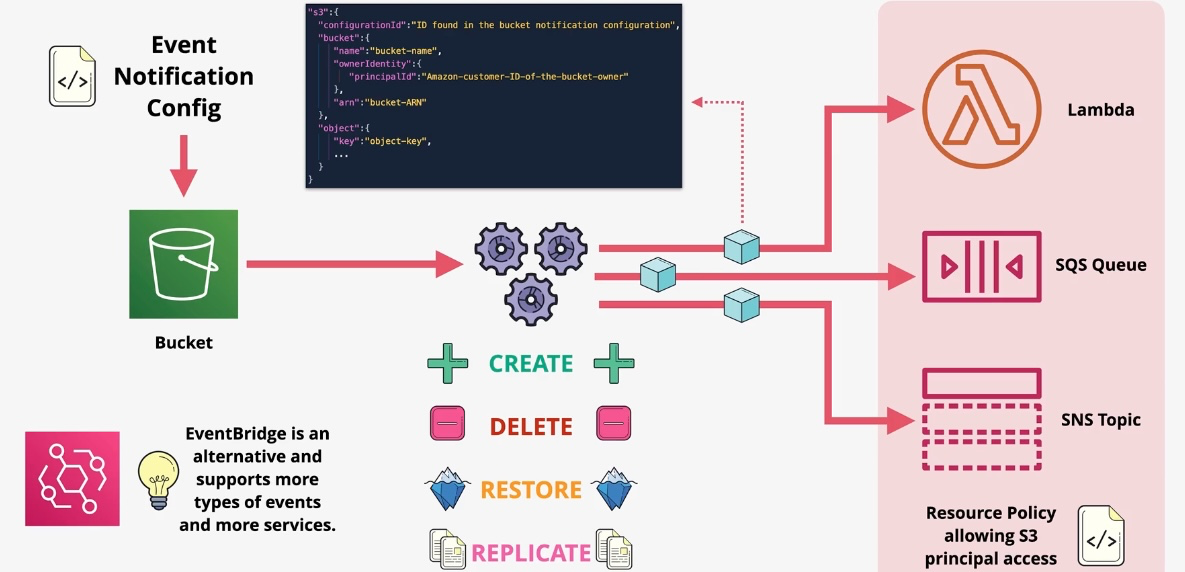
S3 Access Logs
Provides detailed records for the requests that are made to a bucket
S3 Object Lock
You can use S3 Object Lock to store objects using a write-once-read-many (WORM) model. It can help you prevent objects from being deleted or overwritten for a fixed amount of time or indefinitely. You can use S3 Object Lock to meet regulatory requirements that require WORM storage, or add an extra layer of protection against object changes and deletion.
- Object Lock enabled on “new” buckets* (Support for existing)
- Write-Once-Read-Many (WORM) - No delete, No owerwrite
- Requires versioning - individual versions are locked
- 1 - Retention Period
- 2 - Legal Hold
- Both, One or the other, or none
- A bucket can have default object lock settings
Retention
- Specify DAYS & YEARS - A Retention Period
- COMPLIANCE - Cant be adjusted, deleted, overwritten
- even by account root user
- until retention expires
- Use due to compliance
- GOVERNANCE - special permissions can be granted allowing lock settings to be adjusted
- s3:ByPassGovernanceRetention
- x-ams-bypass-governance-retention:true (console default)
Legal Hold
- Set on an object version - ON or OFF
- No retention
- NO DELETES or changes until removed
- s3:PutObjectLegalHold is required to add or remove
- Prevent accidental deletion of object version
⛅ Virtual Private Cloud (VPC)
VPC Sizing and Structure
VPC Considerations
- VPC CIDR range
- What size should the VPC be
- Are there any networks we can’t use?
- VPC’s, Cloud, On-premises, Partners & Vendors
- Try to predict the future
- VPC Structure - Tiers & Resiliency (Availability) Zones
- Global architecture
- E.g. ranges to avoid in a real-case scenario
- VPC minimum /28 (16 IPs), maximum /16 (65536 IPs)
- Personal preference for the 10.x.y.z range
- Avoid common ranges - avoid future issues
- Reserve 2+ networks per region being used per account
| VPC Size | Netmask | Subnet Size | Hosts/Subet* | Subnets/VPC | Total IPs* | | | | | | | | | Micro | /24 | /27 | 27 | 8 | 216 | | Small | /21 | /24 | 251 | 8 | 2008 | | Medium | /19 | /22 | 1019 | 8 | 8152 | | Large | /18 | /21 | 2043 | 8 | 16344 | | Extra Large | /16 | /20 | 4091 | 16 | 65456 |
VPC Structure
- Number of AZs for VPC
- Start with 3 as default
- 1 as spare for future
- Four tiers default
- Web, app, db, spare
Custom VPCs
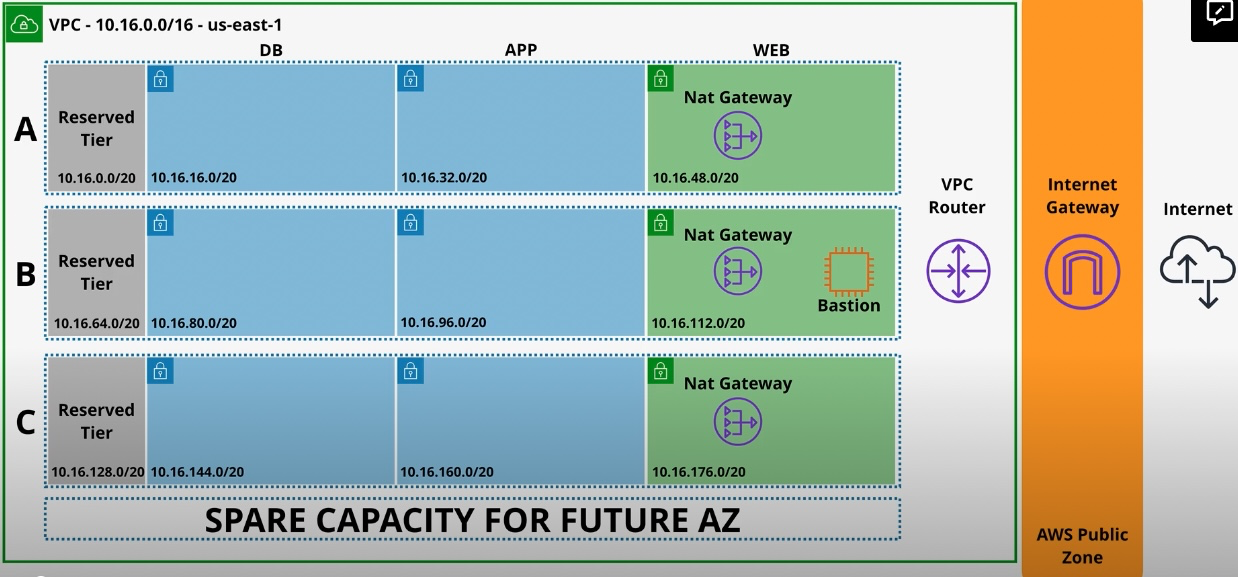
VPC Design - End state
Custom VPC Fundamentals
- Regional service - All AZ’s in the region
- Isolated network
- Nothing IN or OUT without explicit configuration
- Flexible configuration - simple or multi-tier
- Hybrid networking - other cloud & on-premises
- Default or dedicated tenancy
- IPv4 Private CIDR Blocks & Public IPs
- 1 Primary Private IPv4 CIDR Block
- min /28 max /16 (16 - 65536 IPs)
- Optional secondary IPv4 Blocks
- Optional single assigned IPv6 /56 CIDR Block
DNS in a VPC
- Provided by R53
- VPC ‘Base IP +2’ Address
- enableDnsHostnames
- gives instances DNS Names
- enableDnsSupport
- enables DNS resolution in VPC
VPC Subnets
- AZ resilient
- A subnetwork of a VPC - within a particular AZ
- 1 subnet → 1 AZ, 1 AZ → 0+ Subnets
- IPv4 CIDR is a subset of the VPC CIDR
- Cannot overlap with other subnets
- Optional IPv6 CIDR (/64 subset of the /56 VPC - space for 256)
- Subnets can communicate with other subnets in the VPC
Subnet IP Addressing
- Reserved IP addresses (5 in total)
- 10.16.16.0/20 (10.16.16.0 → 10.16.16.255)
- Reserved addresses
- Network Address (10.16.16.0)
- First in network is always reserved. Goes for all networks.
- Network+1 (10.16.16.1)
- VPC Router
- Network+2 (10.16.16.2)
- Reserved (DNS*)
- Network+3 (10.16.16.3)
- Reserved Future Use
- Broadcast Address 10.16.31.255
- Last IP in subnet
- Network Address (10.16.16.0)
- DHCP Option Set (Dynamic Host Configuration Protocol)
- How devices receive IP addresses automatically
- Per subnet:
- Auto assign public IPv4
- Auto assign public IPv6
VPC Routing and Internet Gateway
VPC Router
- Every VPC has a VPC Router - Highly available
- In every subnet ’network+1’ address
- Routes traffic between subnets
- Controlled by ‘route tables’ each subnet has one
- A VPC has a Main route table - subnet default
- Route tables are attached to 0 or more subnets
/nhigher n = more specific = higher priority- A subnet has to have a route table. Either main by VPC or a custom.
- Route table controls what happens to data as it leaves the subnet that route table is associate with
- A subnet can only be associated with 1 route table at the time
Internet Gateway (IGW)
- Region resilient gateway attached to a VPC
- 1 VPC = 0 or 1 IGW, 1 IGW = 0 or 1 VPC
- Runs from within the AWS Public Zone
- Gateways traffic between the VPC and the Internet or AWS Public Zone (S3, SQS, SNS, etc)
- Managed - AWS handles performance
- Self note:
- Maps private IP to Public IP and vice versa
Using an IGW
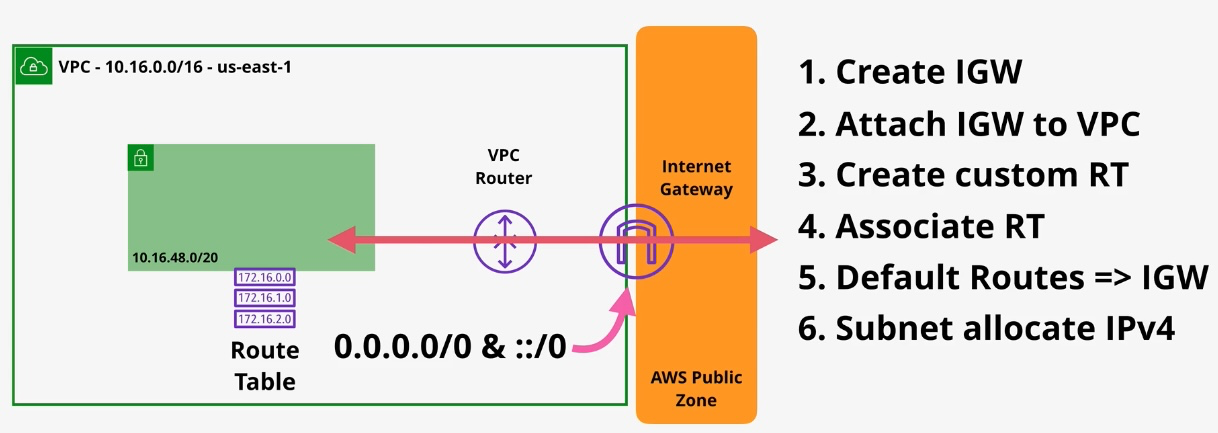
IPv4 Addresses with a IGW
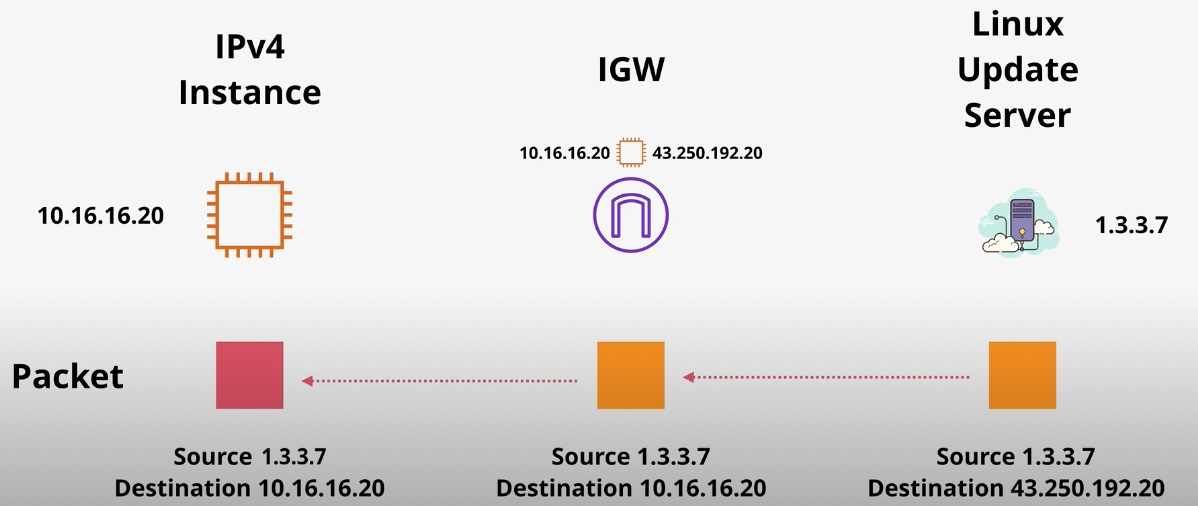
- OS on EC2 is at no point aware of its public IPv4!
Bastion Host / Jumpbox
- Bastion Host = Jumpbox
- An instance in a public subnet
- Incoming management connections arrive there
- Then access internal VPC resources
- Often the only way IN to a VPC
Stateful vs Stateless Firewalls
Transmission Control Protocol (TCP)
TCP is a connection based protocol. A connection is established between two devices using a random port on a client and a known port on the server. Once established the connection is bi-directional. The “connection” is a reliable connection, provided via the segment encapsulated in IP packets.
💡 HTTP: Port 80 HTTPS: Port 443
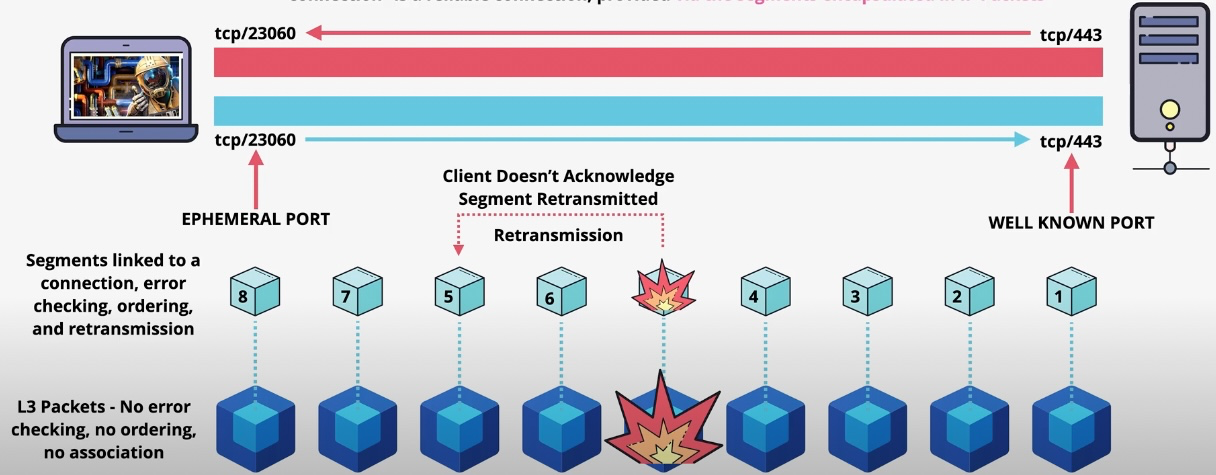
Stateful vs Stateless Firewalls
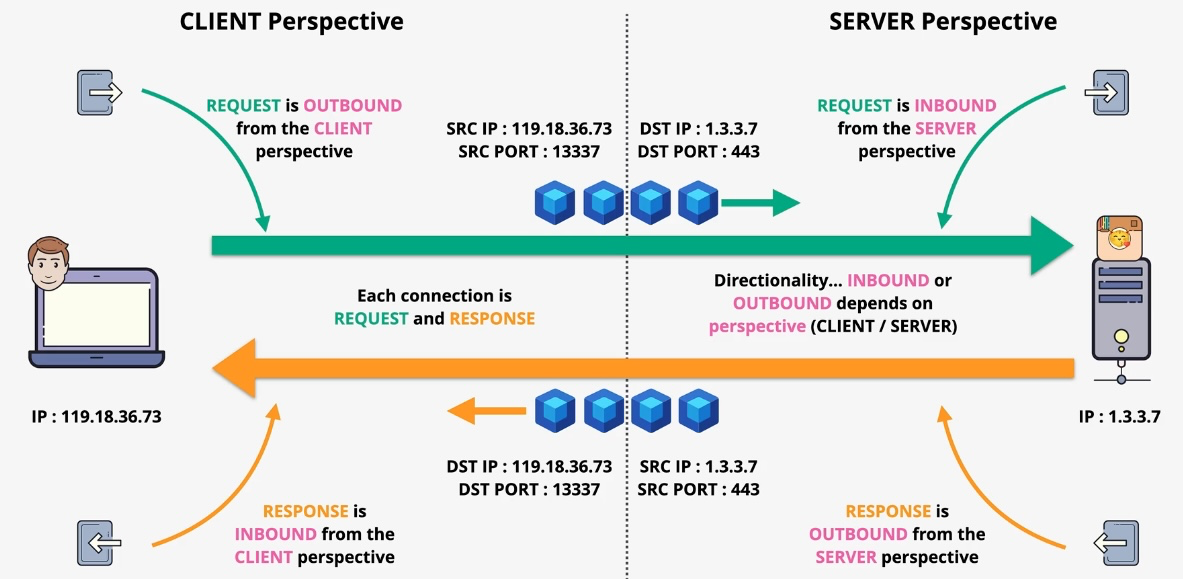
Stateless Firewalls
2 Rules (1 IN, 1 OUT) per connection (inbound application) 2 Rules (1 OUT, 1 IN) per connection (outbound application)
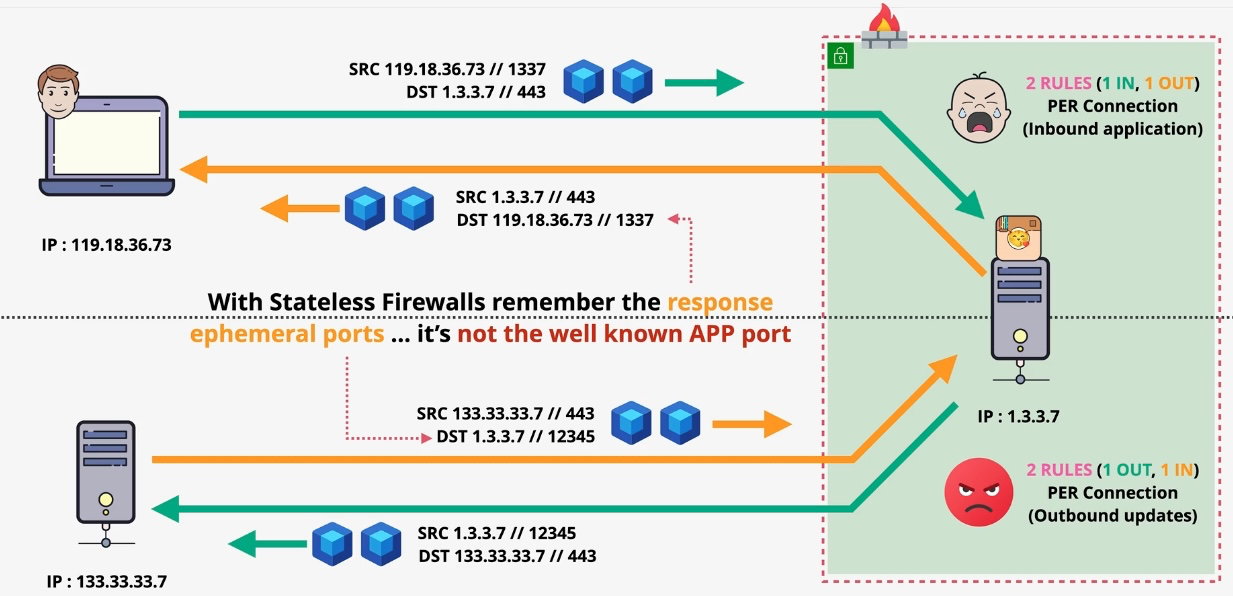
Stateful Firewalls
Intelligent enough to identify the request and response components of a connection as being related
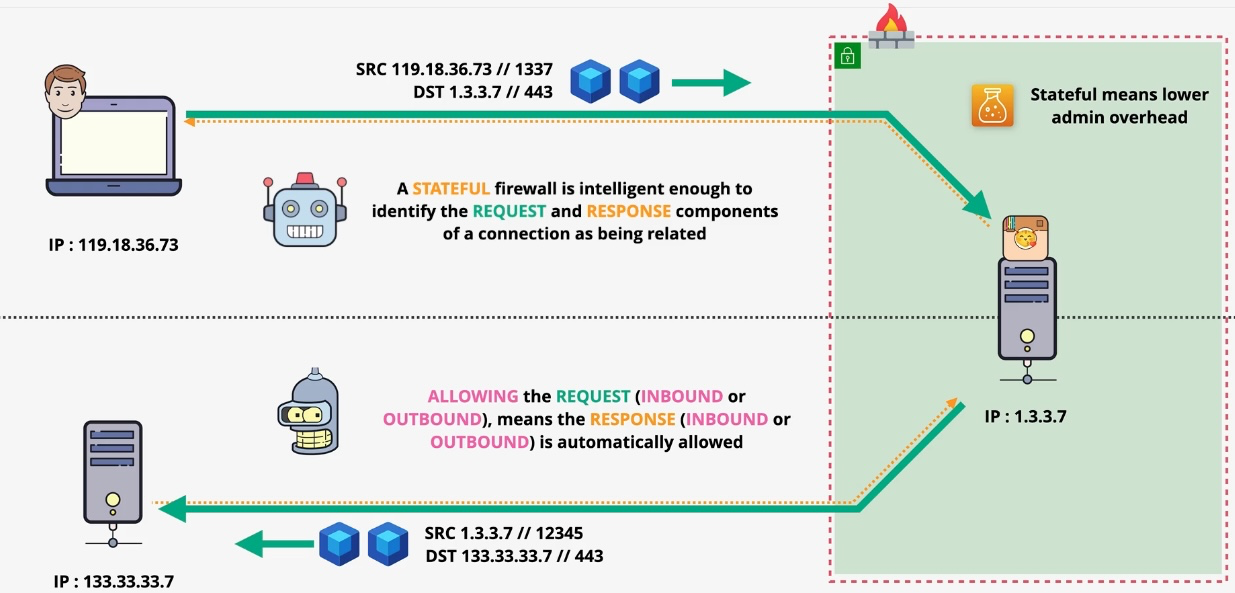
Network Access Control Lists (NACL)
Can be considered a traditional firewall within AWS VPC Every subnet has an associated NACL
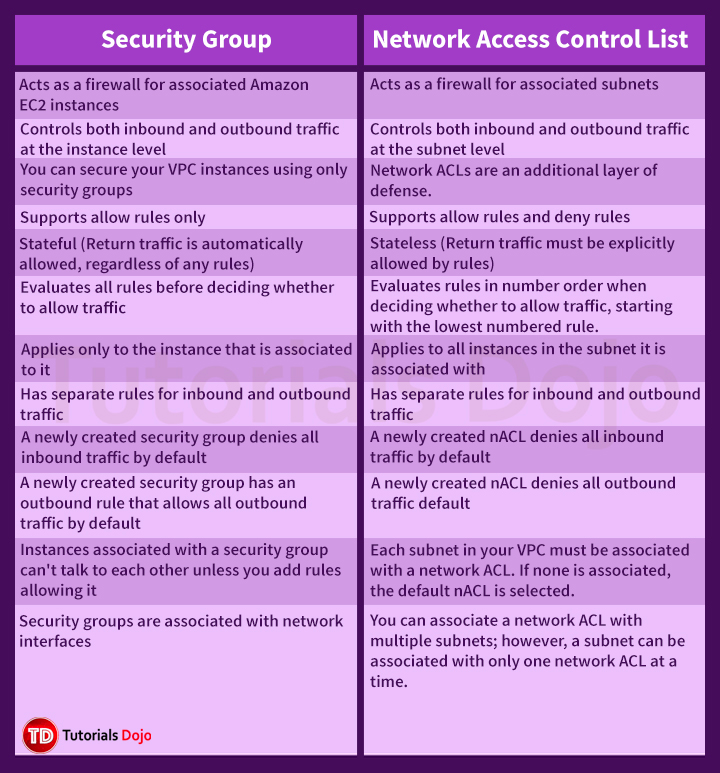
- Inbound rules and Outbound rules.
- Inbound: Traffic entering the subnet
- Outbound: Traffic leaving the subnet
- Rules match the DST IP/Range, DST Port and Protocol and Allow or Deny based on that match
- Rules are processed in order, lowest rule number first. Once a match occurs, processing STOPS.
-
- is an implicit DENY if nothing else matches
-
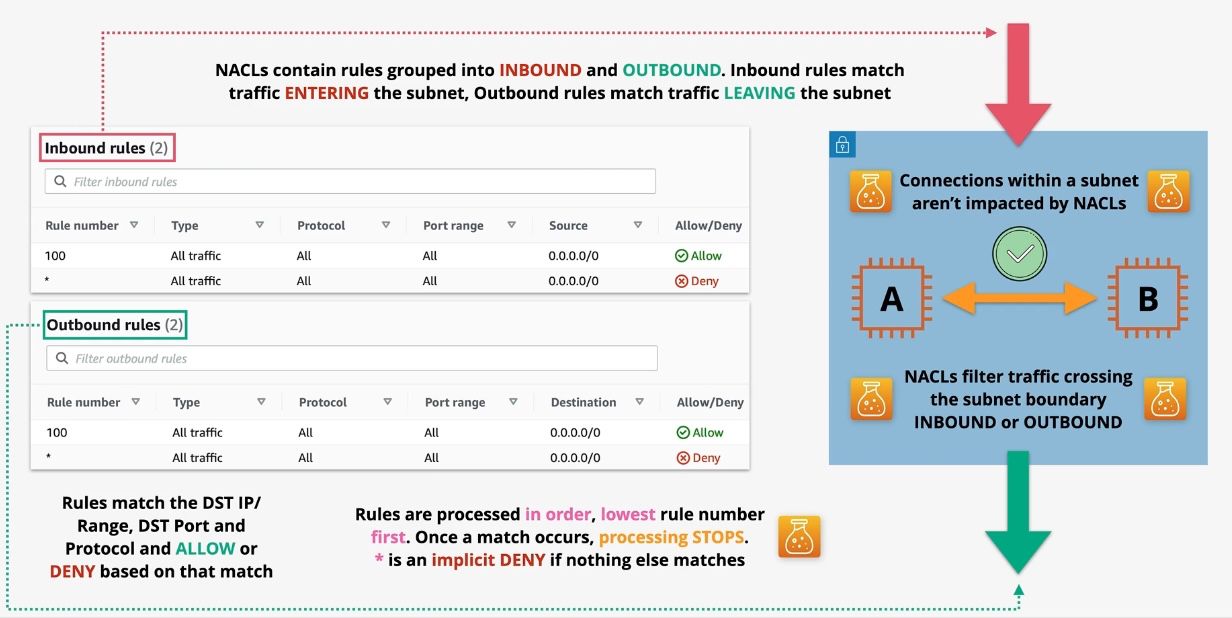
- NACLs are STATELESS. Both request and response need individual rules.
- These rule-pairs (app port and ephemeral ports) are needed on each NACL for each communication type which occurs
- Within a VPC
- TO a VPC
- FROM a VPC
- These rule-pairs (app port and ephemeral ports) are needed on each NACL for each communication type which occurs
- A VPC is created with a default NACL
- Inbound and outbound rules have the implicit deny (*) and an ALLOW ALL rule
- The result - all traffic is allowed, the NACL has no effect
Custom NACL
Custom NACLs can be created for a specific VPC and are initially associated with no subnets
- They only have 1 INBOUND rule - implicit (*) DENY
- All traffic is denied
- They only have 1 OUTBOUND rule - the implicit (*) DENY
NACL Key Points
- Stateless: Request and Response seen as different
- Only impacts data crossing subnet boundary
- NACL can explicitly ALLOW and DENY
- IPs/CIDR, Ports & Protocols - no logical resources
- NACLs cannot be assigned to AWS resources - only subnets
- Use together with Security Groups to add explicit DENY (Bad IPs/Nets)
- Each subnet can have ONE NACL (default or custom)
- A NACL can be associated with MANY Subnet
VPC Security Groups (SG)
Security Groups (SGs) are another security feature of AWS VPC ... only unlike NACLs they are attached to AWS resources, not VPC subnets.
SGs offer a few advantages vs NACLs in that they can recognize AWS resources and filter based on them, they can reference other SGs and also themselves.
But.. SGs are not capable of explicitly blocking traffic - so often require assistance from NACLs
💡 STATEFUL NO EXPLICIT DENY - Need assistance from NACL
- STATEFUL - detect response traffic automatically
- Allowed (IN or OUT) request = allowed response
- NO EXPLICIT DENY - only allow or Implicit DENY
- can’t block specific bad actors
- Support IP/CIDR and logical resources
- including other security groups and itself
- Attached to ENI’s (Elastic Network Interfaces) not instances (even if the UI shows it this way)
Logical References
Logical referencing scales. Any new instances which use the webSG are allowed to communicate with any instances using the APP SG. Reduce admin overhead
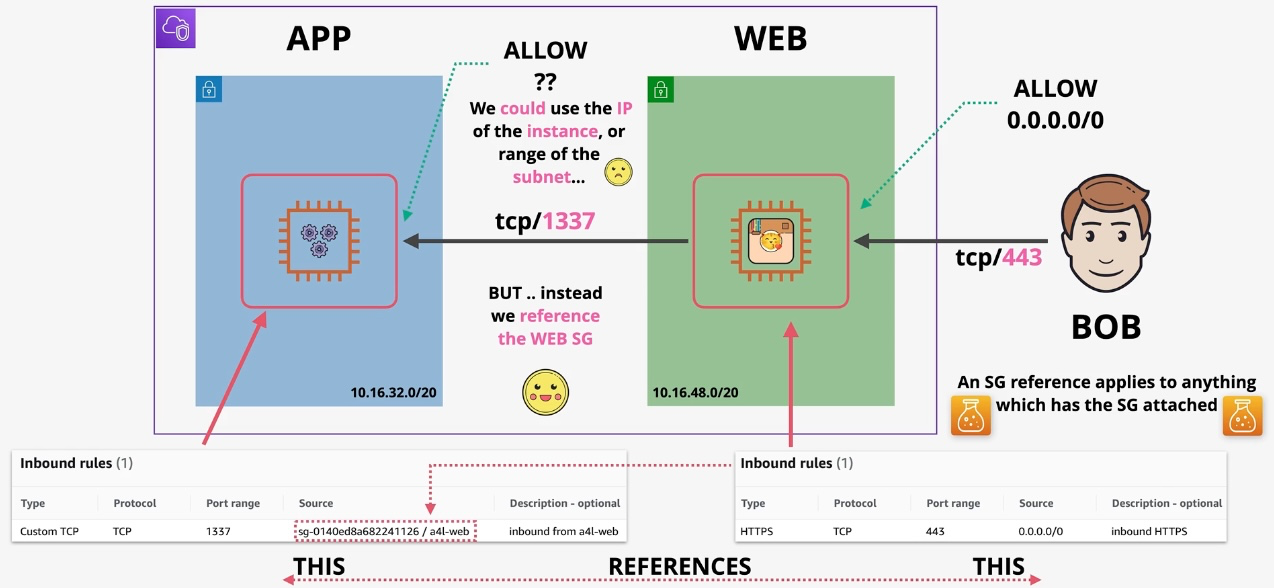
SG Self References
Anything with the same security group can communicate
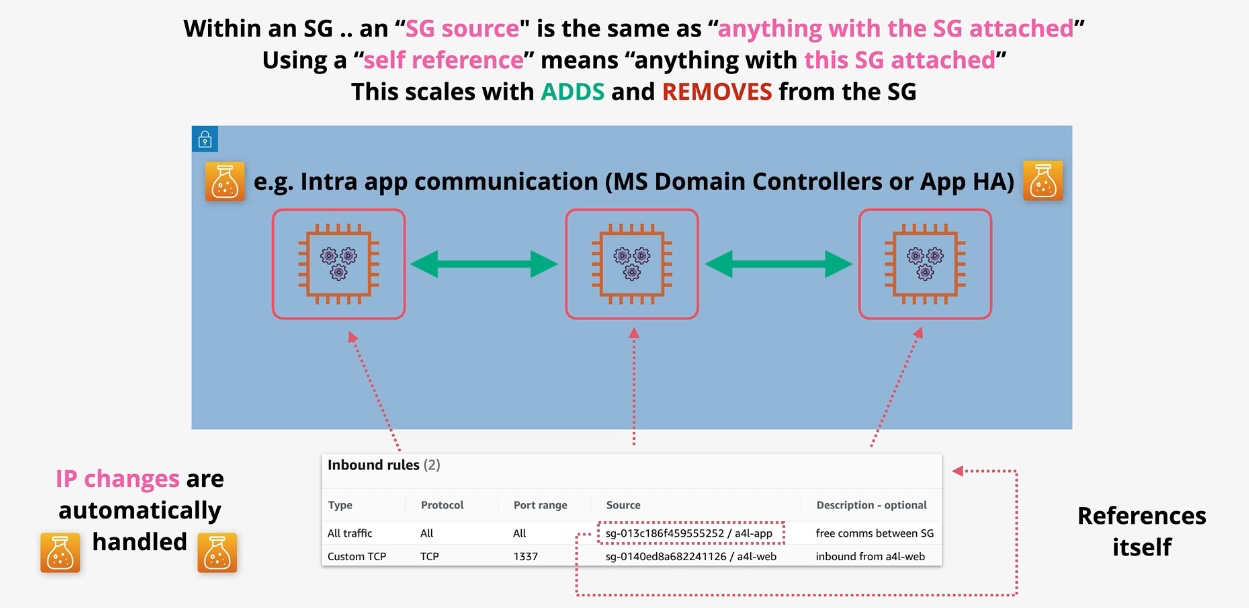
Network Address Translation (NAT) and NAT Gateways
Giving a private resource outgoing access to the internet
What is NAT?
- A set of processes - remapping source og dest IPs
- IP masquerading: Hiding CIDR Blocks behind one IP
- Gives Private VID range outgoing internet* access
NAT Architecture
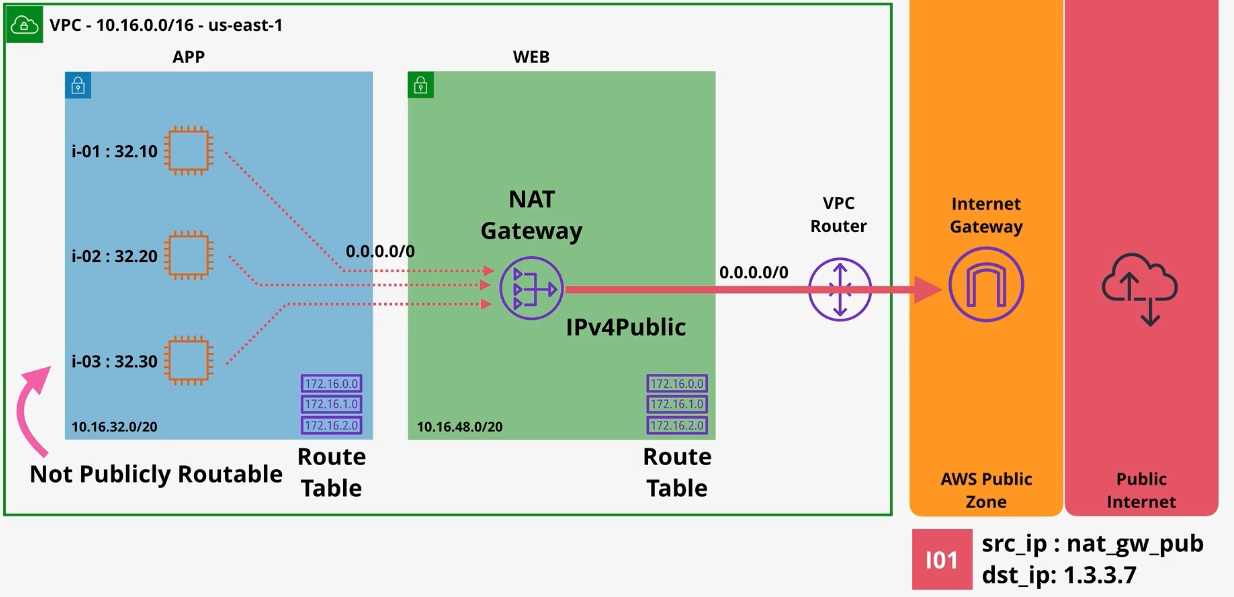
NAT Gateways
- Runs from a public subnet
- Uses ELASTIC IPs (Static IPv4 Public)
- Don’t support security groups! Only NACLs
- AZ resilient Service (HA in that AZ)
- Need a NATGW in every AZ
- For region resilience - NATGW in each AZ
- RT in for each AZ with that NATGW as target
- Managed, scales to 45 Gpbs
- $ Duration & Data Volume
VPC Design - NATGW Full Resilience
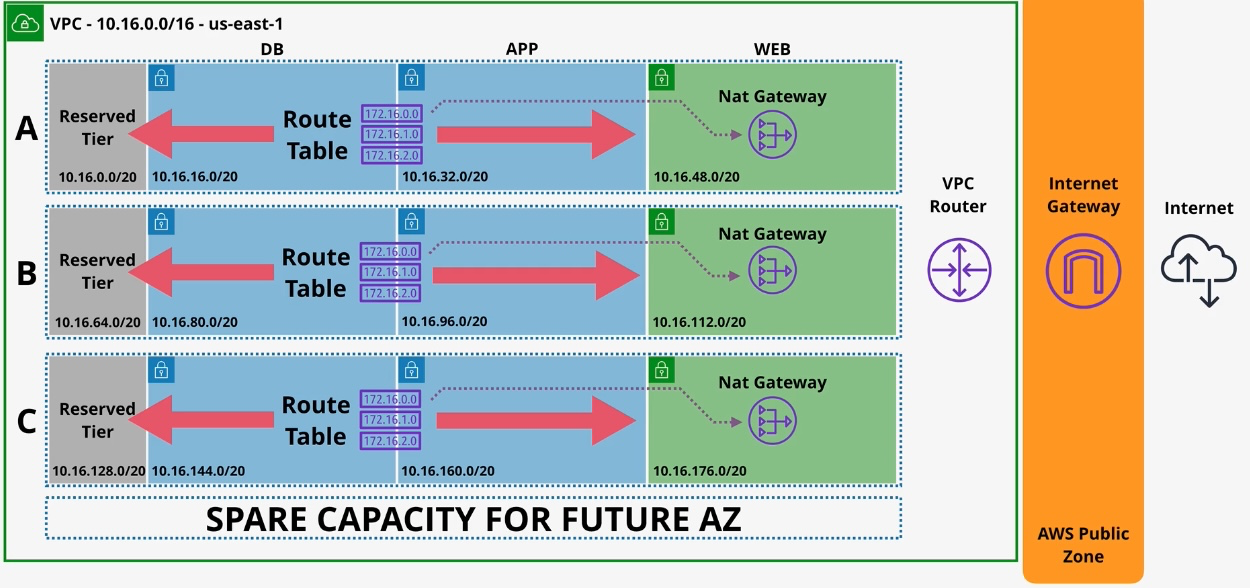
Nat Instance vs NAT Gateway
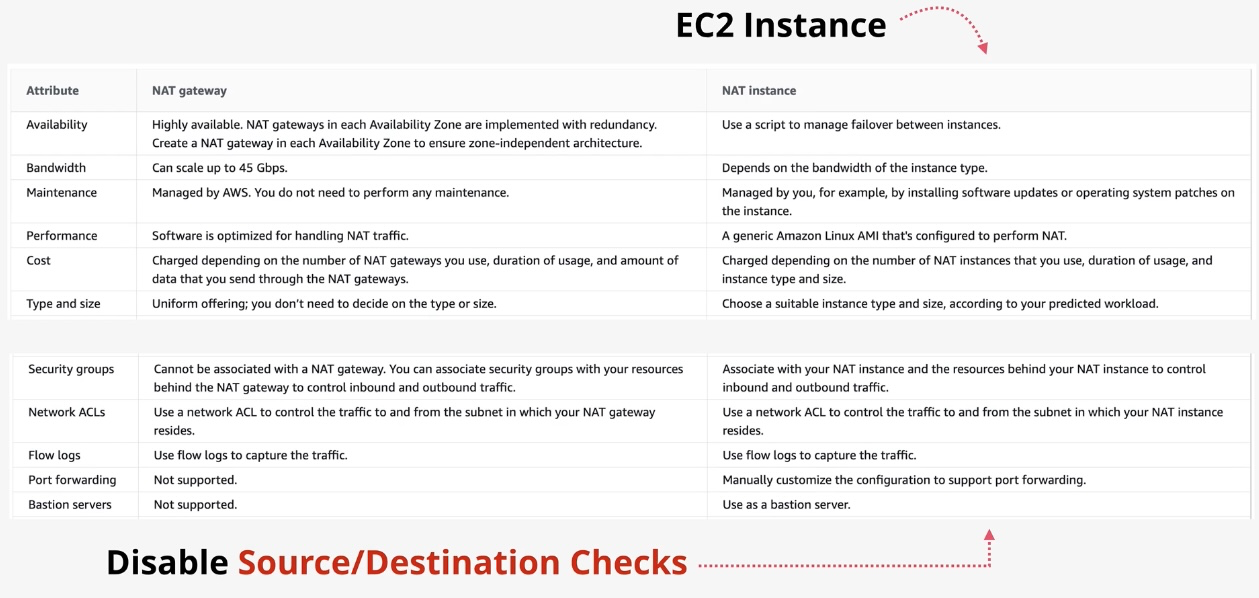
What about IPv6?
- NAT isn’t required for IPv6
- All IPv6 addresses in AWS are publicly routable
- The internet gateway works with all IPv6 IPs directly
- NAT Gateways don’t work with IPv6
- ::/0 Route + IGW for bi-directional connectivity
- ::/0 Route + Egress-Only Internet Gateway - Outbound Only
🖥 Elastic Compute Cloud (EC2) Basics
AZ resilient - very reliant on the AZ it is running in
Virtualization 101
EC2 is virtualization as a Service (IaaS)
💡 Virtualization is running more than one operating system on a physical hardware or server Kernel is the only part of the operating system that is able to directly interact with the hardware (CPU & MEM, Network, Devices)

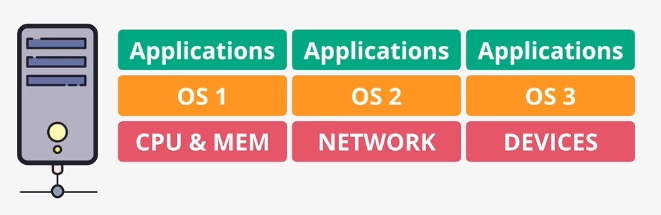
Emulated Virtualization (Software Virtualization)
- Software run i privileged mode and had access to HW
- Emulated hardware, but OS believed it was running on real hardware.
- OS tried to control HW despite it
- Overwrite each other, crash
- Slow!
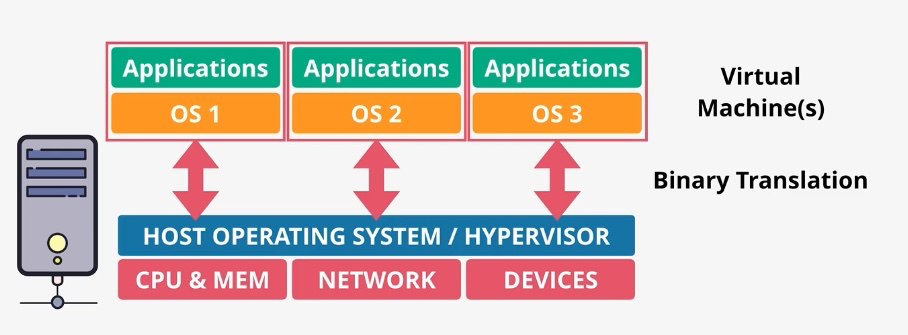
Para-Virtualization
- Only works on a small subset of OS
- Modified source code to call the hypervisor rather than the hardware
- OS became almost aware of virtualization
Hardware Assisted Virtualization
- Hardware itself is aware of virtualization
SR-IOV (Single Root IO Virtualization)
In EC2 - This is enhanced networking
- Network card can present themself as multiple cards rather than one
- Less CPU usage for the host CPU
EC2 Architecture and Resilience
- EC2 instances are virtual machines (OS + Resources)
- EC2 Instances run on EC2 Hosts
- Shared hosts or Dedicated hosts
- Shared hosts default
- Hosts = 1 AZ - AZ Fails, Host Fails, Instances Fails
- EBS: Elastic Block Storage
EC2 Architecture
What’s EC2 Good for?
- Traditional OS+Application Compute
- Long-Running compute
- Server style applications
- either burst or steady-state load
- Monolithic application stacks
- Migrated application workloads or Disaster Recovery
- Tends to be default compute service within AWS!
EC2 Instance Types
- Raw CPU, Memory, Local Storage Capacity & Type
- Resource Ratios
- Storage and Data Network Bandwidth
- System Architecture / Vendor
- ARM vs x86
- Additional Feature and Capabilities
- GPUs, FPGAs
EC2 Categories
Five main categories
- General Purpose. Default. Diverse workloads, equal resource ratio.
- Computed Optimized. Media Processing, HPC, Scientific Modeling, gaming, Machine Learning
- Memory Optimized. Processing large in-memory datasets, some database workloads
- Accelerated Computing. Hardware GPU, fields programmable gate arrays (FPGAs)
- Storage Optimized. Sequential and Random IO - scale-out transactional databases, data warehousing, Elasticsearch, analytics workloads
Decoding EC2 Types
R5dn.8xlarge - Instance type **R - Instance Familiy 5 - generation dn - can vary. (d NVMe storage, n network optimized) 8xlarge - Instance Size
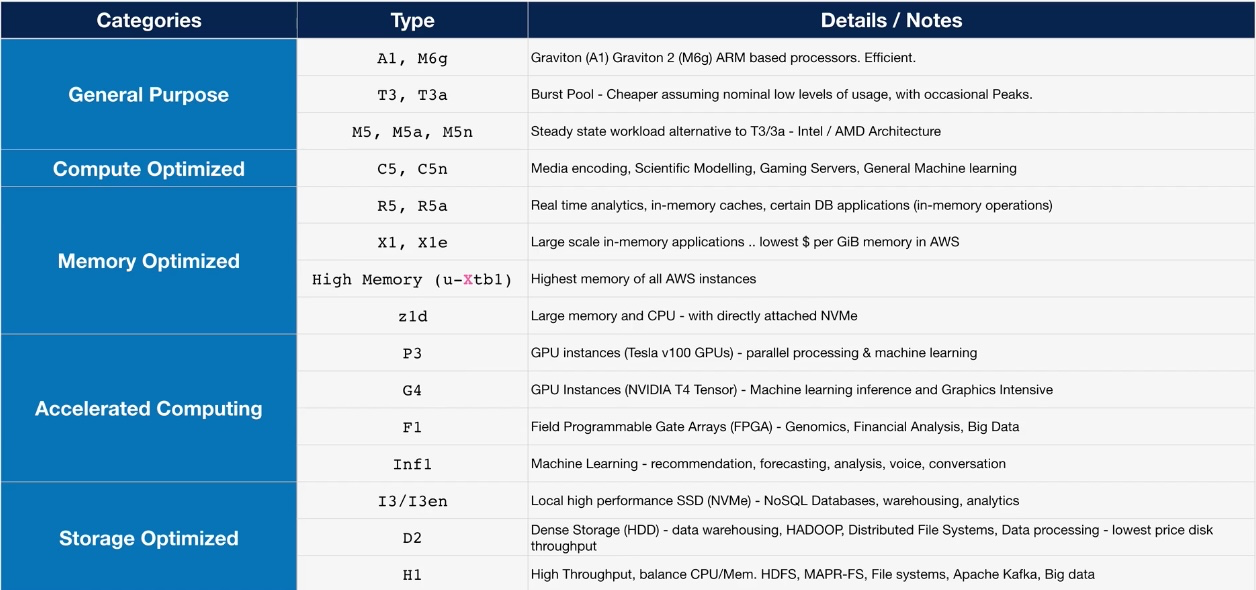
https://aws.amazon.com/ec2/instance-types/
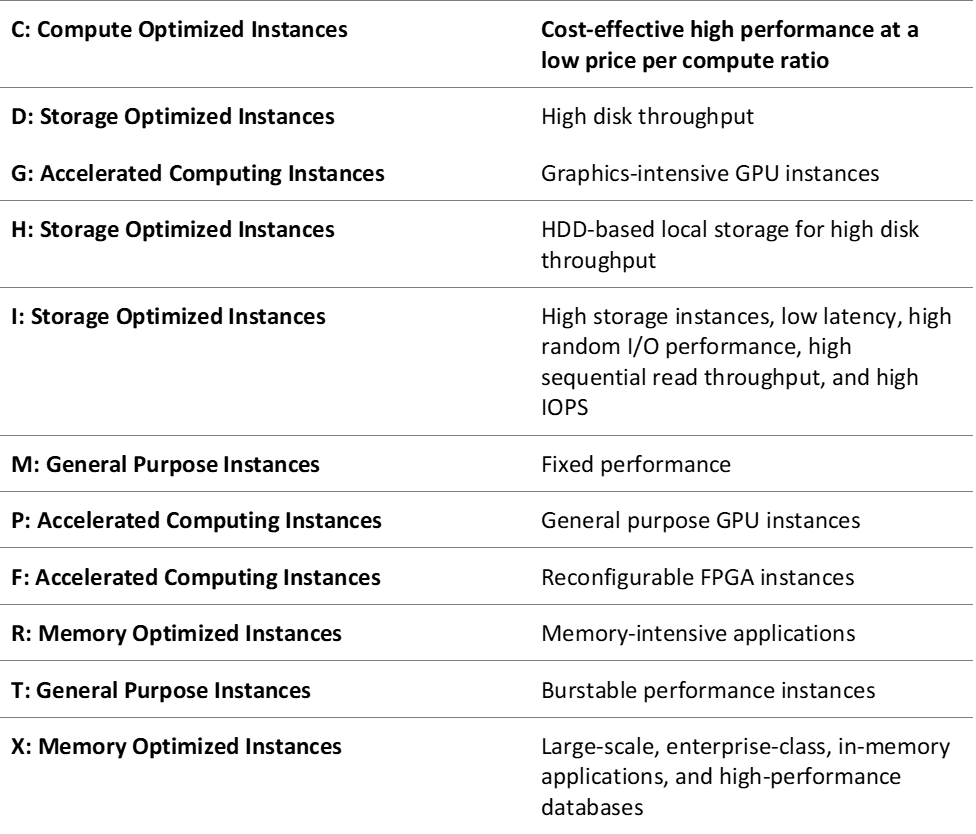
Storage Refresher
Key Terms
- Direct (local) attached Storage - Storage on the EC2 Host
- Network attached Storage - Volumes delivered over the network (EBS)
- Ephemeral storage - Temporary Storage
- Persistent storage - Permanent storage - lives on past the lifetime of the instance
- Block storage - Volume presented to the OS as a collection of blocks. No Structure provided.
- Mountable
- Bootable
- File storage - Presented as a file share. Has structure.
- Mountable.
- NOT Bootable
- Object storage. Collection of objects, flat.
- Not mountable
- Not bootable
- S3
Storage Performance
- IO (block size)
- “Bigger wheels”
- IOPS (Input Output Per Second)
- “Rev of wheels”
- Throughput (MB/s)
- “End speed”
- Block size: 16 KB, IOPS: 100 → 1.6 MB/s
- 1 MB block size wont necessarily lead to 1000 MB/s - throughput limits etc
Elastic Block Storage (EBS)
Amazon Elastic Block Store (Amazon EBS) provides block level storage volumes for use with EC2 instances. EBS volumes behave like raw, unformatted block devices. You can mount these volumes as devices on your instances. EBS volumes that are attached to an instance are exposed as storage volumes that persist independently from the life of the instance. You can create a file system on top of these volumes, or use them in any way you would use a block device (such as a hard drive).
- Block storage: Raw disk allocations (volume). Can be encrypted using KMS.
- Instances see block device and create file system on this device (ext3/4, xfs)
- Storage is provisioned in ONE AZ (AZ Resilient)
- Attached to *one EC2 instance (or other service) over a storage network
- Detached and reattached. Not lifecycle linked to one instance. Persistent.
- Snapshot (backup) into S3. Create a volume from snapshot (migrate between AZs).
- Different physical storage types, different sizes, different performance profiles.
- Billed based on GB-month (and is some cases performance)
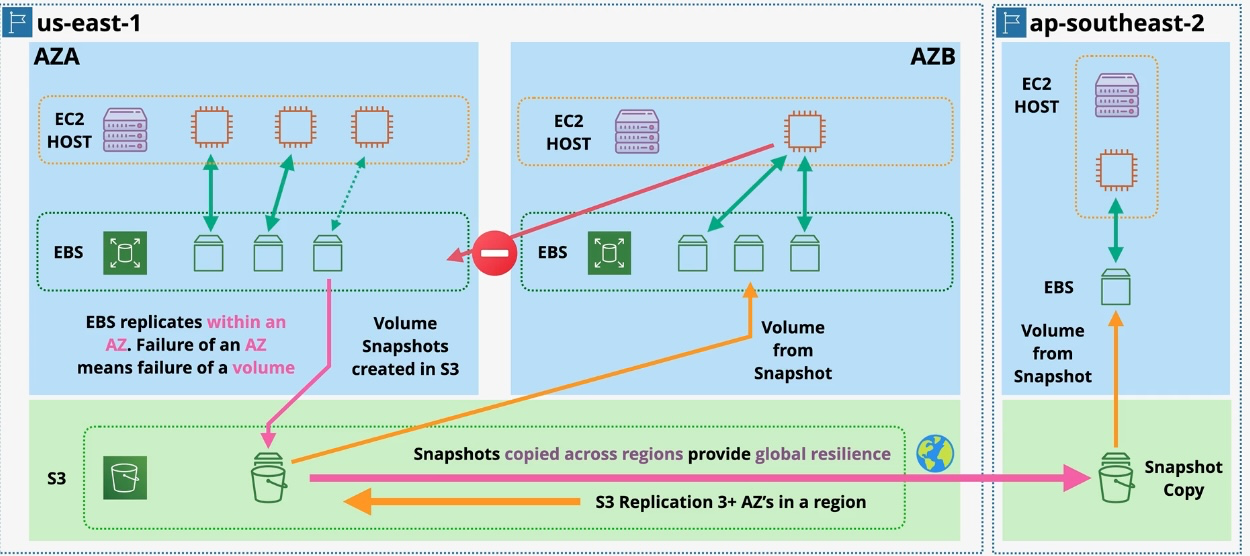
EBS Volume Types - General Purpose SSD
GP2 and GP3
GP2
- 1GB to 16 TB
- 1 IO credit = 16 KB chunk of data
- IO Credit bucket capacity of 5.4 million IO Credits
- Fills at rate of Baseline Performance
- Bucket fills with min 100 IO Credits per second
- Regardless of volume size
- Beyond this, bucket fill with 3 IO credits per second, per GB of volume size (Baseline Performance)
- Burst up to 3000 IOPS by depleting the bucket
- Bucket starts off full! 5.4 million IO credits
- If you’re depleting the bucket at a higher rate than it’s refilling you’re losing credits
- Volumes up to 1 TB use this IO credit architecture
- Above 1 TB baseline is above burst. Credit system isn’t used and you always achieve baseline
- Up to maximum for GP2 of 16000 IO credit per second (baseline performance)
GP3
Removes credit bucket architecture
- 3000 IOPS
- 125 MiB/s - Standard
- GP3 is cheaper (20%) vs GP2
- Extra cost for up to 16000 IOPS or 1000 MiB/s
- 4x Faster max throughput vs GP2
- 1000 MiB/s vs 250 MiB/s
- Benefits of both GP2 and IO1
- Suitable for
- Virtual desktops, medium sized single instance databases such as MSSQL Server and Oracle DB, low-latency interactive apps, dev&test, boot volumes
Provisioned IOPS SSD (io1/2)
- io1/2/BlockExpress
- IOPS can be adjusted independently of size
- Consistent Low latency and jitter
- Up to:
- 64000 IOPS per volume (4x GP2/3)
- 256000 IOPS per volume (Block Express)
- 1000 MB/s throughput
- 4000 MB/s throughput (Block Express)
- 4GB - 16TB io1/2
- 4GB-64TB BlockExpress
- Limits:
- io1 50 IOPS/GB (max)
- io2 500 IOPS/GB (max)
- BlockExpress 1000 IOPS/GB (max)
- Per instance restriction:
- io1 - 260000 IOPS & 7500 MB/s
- io2 - 160000 IOPS & 4750 MB
- io2 Block Express - 260000 IOPS & 7500 MB/s

HDD-Based
- Two types (three, but legacy)
- st1
- Throughput optimized
- Cheap
- 125GB - 16 GB
- Max 500 IOPS (1MB blocks)
- Max 500 MB/s
- 40MB/s TB Base
- 250 MB/s Burst
- Frequent Access
- Throughput-intensive
- Sequential
- Big data, data warehouses, log processing
- sc1
- Cheaper
- Cold
- Max 250 IOPS (1 MB blocks)
- Max 250 MB/s
- 12 MB/s/TB Base
- 80 MB/s/TB Burst
- Coder data requiring fewer scans per day
- Lowest cost HDD volume designed for less frequently accessed workloads
Instance Store Volumes
An instance store provides temporary block-level storage for your instance. This storage is located on disks that are physically attached to the host computer. Instance store is ideal for temporary storage of information that changes frequently, such as buffers, caches, scratch data, and other temporary content, or for data that is replicated across a fleet of instances, such as a load-balanced pool of web servers.
An instance store consists of one or more instance store volumes exposed as block devices. The size of an instance store as well as the number of devices available varies by instance type.
The virtual devices for instance store volumes are
ephemeral[0-23]. Instance types that support one instance store volume haveephemeral0. Instance types that support two instance store volumes haveephemeral0andephemeral1, and so on.
- Block Storage devices
- Physically connected to one EC2 host
- Instances on that host can access them
- Highest storage performance in AWS!
- Included in instance price
- ATTACH AT LAUNCH!
- Can’t be added after launch
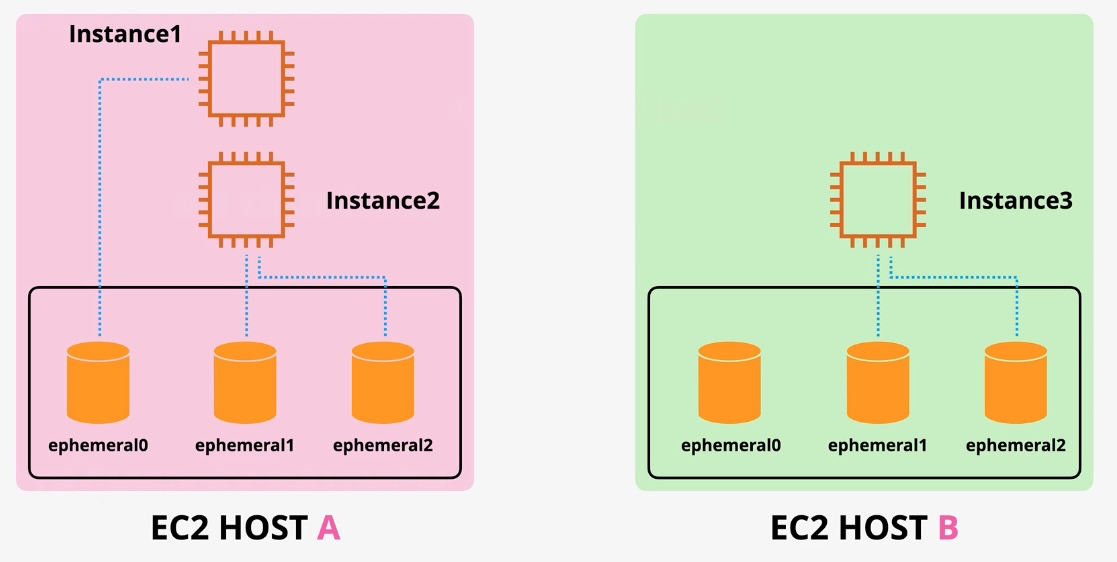
- When instances move across volumes their storage will be blank
- Stop and start will migrate to a new host
- D3 = 4.6 GB/s throughput
- I3 = 16 GB/s of sequential throughput
- More IOPS and throughput vs EBS!
Key points
- Local on EC2 Host
- Add at launch ONLY
- Lost if instance move, resize or hardware failure
- High performance
- Tradeoff - much higher performance but higher risk
- You pay for it anyway - included in instance price
- TEMPORARY!
- Not for persistent storage of data
Instance Store vs EBS
EBS
- Persistence
- Resilience
- Storage isolated from lifecycle
- Resilience with app in-built replication
- High performance needs
Instance Store
- Resilience with app in-built replication
- High performance needs
- Super high performance needs
- Cost (often included)
Instance Store vs EBS
- Cheap = ST1 or SC1
- Throughput, streaming… = ST1
- Boot = NOT ST1 or SC1
- GP2/3 - up to 16000 IOPS
- IO1/2 up to 64000 IOPS (*256000)
- RAID0 + EBS up to 260000 IOPS (io1/2-BE/GP2/3)
- More than 260000 IOOPS → INSTANCE STORE!
EBS Snapshots
EBS Snapshots are backups of data consumed within EBS Volumes - Stored on S3.
Snapshots are incremental, the first being a full backup - and any future snapshots being incremental.
Snapshots can be used to migrate data to different availability zones in a region, or to different regions of AWS.
- Snapshots are incremental volume copies to S3
- The first is a full copy of “data” on the volume
- If 10GB of 40GB is used, the 10GB is copied
- Future snaps are incremental
- They only store the difference between this and previous snapshot
- Volumes can be created (restored) from snapshots
- Snapshots can be copied to another region
- STOP and START of EC2 instances will move to another host
- You will lose your data
EBS Snapshots/Volume Performance
- New EBS volume = full performance immediately
- Snaps restore lazily - fetched gradually
- Requested blocks are fetched immediately
- Force a real of all data immediately
- Fast Snapshot Restore (FSR) - Immediate restore
- Up to 50 snaps per region. Set on the Snap & AZ
Snapshot Consumption and Billing
- GB per month
- Used NOT allocated data
CLI Commands to Mount Filesystem on a EBS Volume
# Commands User
## Instance 1
lsblk
sudo file -s /dev/xvdf # Output data, because EBS is only attached but has no mounted fs
sudo mkfs -t xfs /dev/xvdf # Make file system on EBS volune
sudo file -s /dev/xvdf # Will output file system
sudo mkdir /ebstest # Make directory to mount EBS on
sudo mount /dev/xvdf /ebstest # Mounts attached EBS volume to directory
cd /ebstest
sudo nano amazingtestfile.txt
# add a message
# save and exit
ls -la
## Reboot Instance 1
sudo reboot
## Instance 1 After Reboot
df -k # Volume won't show - must configure st volume is auto mounted on reboot
sudo blkid # List unique IDs for all mounted volumes
sudo nano /etc/fstab
ADD LINE
UUID=YOURUUIDHEREREPLACEME /ebstest xfs defaults,nofail
sudo mount -a # Will mount all files in the /etc/fstab file
cd /ebstest
ls -la # Amazingtestfile.txt still exists - volume is persistent even after reboot
## Instance 2
# We mount the same volume we detached from instance 1, and see that content is still the same
lsblk
sudo file -s /dev/xvdf
sudo mkdir /ebstest
sudo mount /dev/xvdf /ebstest
cd /ebstest
ls -la
## Instance 3
# Instance in another AZ - we created a snapshot and created a volume from the snapshot in another AZ
lsblk
sudo file -s /dev/xvdf
sudo mkdir /ebstest
sudo mount /dev/xvdf /ebstest
cd /ebstest
ls -la
## InstanceStoreTest
lsblk
sudo file -s /dev/nvme1n1
sudo mkfs -t xfs /dev/nvme1n1
sudo file -s /dev/nvme1n1
sudo mkdir /instancestore
sudo mount /dev/nvme1n1 /instancestore
cd /instancestore
sudo touch instancestore.txt
## InstancStoreTest - After Restart
df -k
its not there
but we can mount it
sudo mount /dev/nvme1n1 /instancestore
cd /instancestore
ls -la
## InstanceStoreTest - After Stop/Start
sudo file -s /dev/nvme1n1
EBS Encryption
By default no encryption is applied. This adds risk - encryption helps mitigate this risk.
💡 Data only exist in encrypted form on the volume. Plaintext data only ever exist in the memory of the EC2 host KMS Keys - aws/ebs or customer managed
Key Concepts
- Accounts can be set to encrypt by default - default KMS Key
- Otherwise choose a KMS Key to use
- Each volume uses 1 unique DEK (Data Encryption Key)
- Snapshots & future volumes use the same DEK
- Can’t change a volume to NOT be encrypted!!
- OS isn’t aware of the encryption
- No performance loss!
- If you need the OS to encrypt things, you must configure volume encryption (software disk encryption) by yourself
(Elastic) Network Interfaces, Instance IPs and DNS
EC2 Network & DNS Architecture
ENI - Elastic Network Interface
- Every EC2 instance has at least one ENI
- Must be in same AZ
- When you launch an instance with SGs, that SG is on the ENI, not the instance itself
- (Primary) (Elastic) Network interfaces have…
- MAC Addresses!
- IPv4 Private IP → 10.16.0.10 → (dns) ip-10-16-0-10.ec2.internal
- DNS can be used for internal use
- 0 or more secondary IPs
- 0 or 1 Public IPv4 Address → random IP → random dns based on IP
- 1 elastic IP per private IPv4 address
- If you assign it
- Removes the Public IPv4
- Replaces with the Elastic IP
- You can’t regain the old public IPv4 if you remove Elastic IP
- 0 or more IPv6 addresses
- Security Groups
- Source/Destination Check
- Enable/disable
- Disable to use EC2 instance as NAT
- Secondary ENI
- As above, but can be detached and moved to other EC2 instances
Key Concepts
- Secondary ENI + MAC = Licensing
- Move licensing between instances by moving ENI
- Multi-homed (subnets) Management and Data
- Different Security Groups - multiple interfaces with different SG on each
- OS - DOESN’T SEE PUBLIC IPv4.
- Stop & Start = Change
- Public DNS = private IP in VPC
- Public IP everywhere else
DEMO: Installation of Wordpress on EC2
# DBName=database name for wordpress
# DBUser=mariadb user for wordpress
# DBPassword=password for the mariadb user for wordpress
# DBRootPassword = root password for mariadb
# STEP 1 - Configure Authentication Variables which are used below
DBName='a4lwordpress'
DBUser='a4lwordpress'
DBPassword='REPLACEME'
DBRootPassword='REPLACEME'
# STEP 2 - Install system software - including Web and DB
sudo yum install -y mariadb-server httpd wget
sudo amazon-linux-extras install -y lamp-mariadb10.2-php7.2 php7.2
# STEP 3 - Web and DB Servers Online - and set to startup
sudo systemctl enable httpd
sudo systemctl enable mariadb
sudo systemctl start httpd
sudo systemctl start mariadb
# STEP 4 - Set Mariadb Root Password
mysqladmin -u root password $DBRootPassword
# STEP 5 - Install Wordpress
sudo wget http://wordpress.org/latest.tar.gz -P /var/www/html
cd /var/www/html
sudo tar -zxvf latest.tar.gz
sudo cp -rvf wordpress/* .
sudo rm -R wordpress
sudo rm latest.tar.gz
# STEP 6 - Configure Wordpress
sudo cp ./wp-config-sample.php ./wp-config.php
sudo sed -i "s/'database_name_here'/'$DBName'/g" wp-config.php
sudo sed -i "s/'username_here'/'$DBUser'/g" wp-config.php
sudo sed -i "s/'password_here'/'$DBPassword'/g" wp-config.php
sudo chown apache:apache * -R
# STEP 7 Create Wordpress DB
echo "CREATE DATABASE $DBName;" >> /tmp/db.setup
echo "CREATE USER '$DBUser'@'localhost' IDENTIFIED BY '$DBPassword';" >> /tmp/db.setup
echo "GRANT ALL ON $DBName.* TO '$DBUser'@'localhost';" >> /tmp/db.setup
echo "FLUSH PRIVILEGES;" >> /tmp/db.setup
mysql -u root --password=$DBRootPassword < /tmp/db.setup
sudo rm /tmp/db.setup
# STEP 8 - Browse to http://your_instance_public_ipv4_ip
Amazon Machine Images (AMI)
Amazon Machine Images (AMI) 's are the images which can create EC2 instances of a certain configuration.
In addition to using AMI's to launch instances, you can customize an EC2 instance to your bespoke business requirements and then generate a template AMI which can be used to create any number of customized EC2 instances.
- AMI’s can be used to launch EC2 instance
- AWS or Community provided
- Marketplace (can include commercial software)
- Regional. Unique ID. e.g. ami-0a893824e0928592f20
- Permissions (Public, Your Account, Specific Accounts)
- You can create an AMI from an EC2 instance you want to template
- AMI’s are containers that reference snapshots
AMI Lifecycle
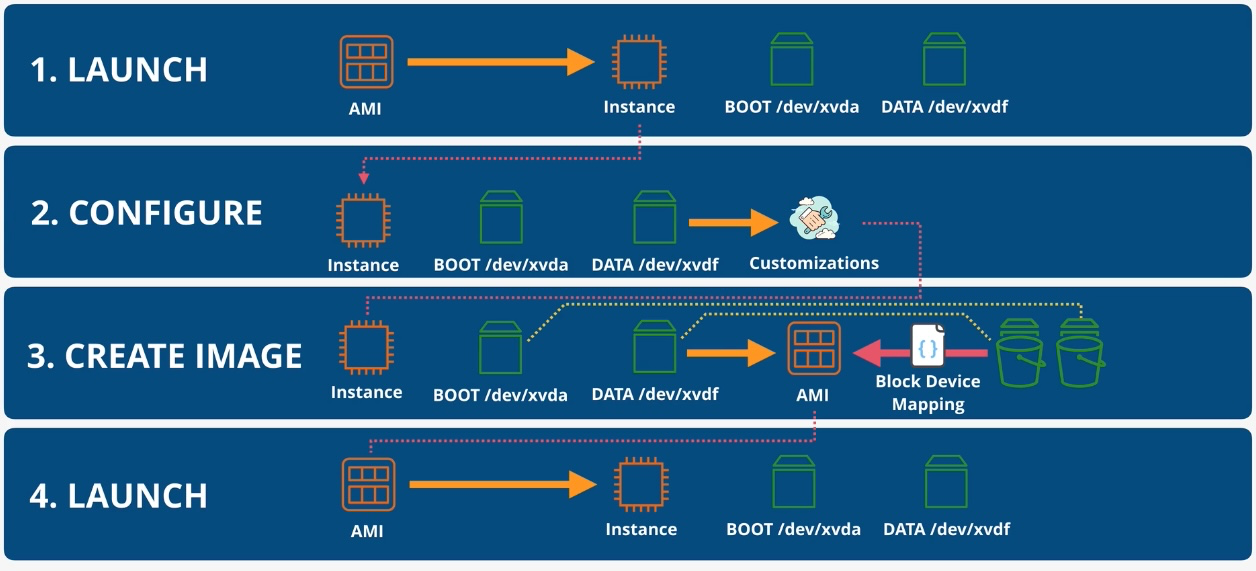
Key Concepts
- AMI = One region. Only works in that one region.
- AMI Baking - Creating an AMI from a configured instance + application
- An AMI can’t be edited. Launch instance, update configuration and make a new AMI
- Can be copied between regions (includes its snapshots)
- Remember permissions. Default = your account
DEMO: A4L AMI
# DBName=database name for wordpress
# DBUser=mariadb user for wordpress
# DBPassword=password for the mariadb user for wordpress
# DBRootPassword = root password for mariadb
# STEP 1 - Configure Authentication Variables which are used below
DBName='a4lwordpress'
DBUser='a4lwordpress'
DBPassword='4n1m4l$L1f3'
DBRootPassword='4n1m4l$L1f3'
# STEP 2 - Install system software - including Web and DB
sudo yum install -y mariadb-server httpd wget
sudo amazon-linux-extras install -y lamp-mariadb10.2-php7.2 php7.2
# STEP 3 - Web and DB Servers Online - and set to startup
sudo systemctl enable httpd
sudo systemctl enable mariadb
sudo systemctl start httpd
sudo systemctl start mariadb
# STEP 4 - Set Mariadb Root Password
mysqladmin -u root password $DBRootPassword
# STEP 5 - Install Wordpress
sudo wget http://wordpress.org/latest.tar.gz -P /var/www/html
cd /var/www/html
sudo tar -zxvf latest.tar.gz
sudo cp -rvf wordpress/* .
sudo rm -R wordpress
sudo rm latest.tar.gz
# STEP 6 - Configure Wordpress
sudo cp ./wp-config-sample.php ./wp-config.php
sudo sed -i "s/'database_name_here'/'$DBName'/g" wp-config.php
sudo sed -i "s/'username_here'/'$DBUser'/g" wp-config.php
sudo sed -i "s/'password_here'/'$DBPassword'/g" wp-config.php
sudo chown apache:apache * -R
# STEP 7 Create Wordpress DB
echo "CREATE DATABASE $DBName;" >> /tmp/db.setup
echo "CREATE USER '$DBUser'@'localhost' IDENTIFIED BY '$DBPassword';" >> /tmp/db.setup
echo "GRANT ALL ON $DBName.* TO '$DBUser'@'localhost';" >> /tmp/db.setup
echo "FLUSH PRIVILEGES;" >> /tmp/db.setup
mysql -u root --password=$DBRootPassword < /tmp/db.setup
sudo rm /tmp/db.setup
# STEP 8 - Browse to http://your_instance_public_ipv4_ip
# Step 9
sudo yum install -y cowsay
cowsay "oh hi"
Create file /etc/update-motd.d/40-cow
sudo nano /etc/update-motd.d/40-cow
#!/bin/sh
cowsay "Amazon Linux 2 AMI - Animals4Life"
sudo chmod 755 /etc/update-motd.d/40-cow
sudo rm /etc/update-motd.d/30-banner
sudo update-motd
sudo reboot
Relogin
## STEP 10 - CREATE AMI
## STEP 11 - USE AMI to launch an instance
EC2 Purchase Options (Launch Types)
On-Demand
- Default
- No specific pros or cons
- Instances of different sizes run on the same EC2 hosts - consuming a defined allocation of resources
- On-Demand instances are isolated but multiple customer instances run on shared hardware
- Per-second billing while an instance is running. Associated resources such as storage consume capacity, so bill, regardless of instance state
- Default purchase option.
- No interruption
- Predictable pricing
- No upfront cost
- No discount
- Short term workloads
- Unknown workloads
- Apps which can’t be interrupted
Spot
- SPOT pricing is AWS selling unused EC2 host capacity for up to 90% discount - the spot price is based on the spare capacity at a given time
- If spot price goes above your limit the instances are terminated
- Makes Spot unreliable
- Never use spot for workloads which can’t tolerate interruptions
- Non time critical
- Anything which can be rerun
- Bursty capacity needs
- Cost sensitive workloads
- Anything which is stateless
Reserved
Long term consistent usage of EC2
- Matching instances - reduced or no per sec price
- Unused reservation still billed
- Partial coverage of larger instance
- You commit to AWS that you will use the instance for a longer period of time - regardless of whether you use them or not
- Reservations are for one or three years
- No-Upfront:
- Some savings for agreeing to the term
- Per second
- All upfront:
- Means no per second fee
- Partial upfront:
- Reduced per second fee
Dedicated Instance
- No other customers use the same hardware
- You have the hardware to yourself
- You neither own or share the host
- Extra charges for instances, but dedicated hardware
- You don’t manage capacity
Dedicated Host
The host is allocated to you in its entirety
- Pay for HOST
- No instance charges
- You must managed the capacity and the resources
- Use because of licensing based on sockets/cores requirements
- Host affinity links instances to hosts
Reserved Instances
Aka Standard Reserved
Scheduled Reserved Instances
- Ideal for long term usage which doesn’t run constantly
- Options:
- Batch processing daily for 5 hours starting at 23:00
- Weekly data, sales analysis. Every friday for 24 hours
- 100 hours of EC2 per month
- Doesn’t support all instance types or regions. 1200 hours per year and 1 year term minimum
Capacity Reservations
In case of disaster and lack of capacity, AWS uses a priority list of whom to give capacity to
- Regional Reservation provides a billing discount for valid instances launched in any AZ in that region
- While flexible they don’t reserve capacity within in AZ - which is risky during major faults when capacity can be limited
- Zonal reservations only apply to one AZ providing billing discounts and capacity reservation in that AZ
- On-demand capacity reservations can be booked to ensure you always have access to capacity in an AZ when you need it - but at full on-demand price. No term limits - but you pay regardless of if you consume it.
EC2 Savings Plan
- A hourly commitment for a 1-3 year term
- A reservation of general compute $ amounts($20 per hour for 3 years)
- Or a specific EC2 Savings plan - flexibility on size & OS
- Compute products, currently EC2, Farge & Lambda
- Products have an on-demand rate and a savings plan rate
- Resource usage consumes savings plan commitment at the reduced savings plan rate
- Beyond your commitment on-demand is used
Instance Status Checks & Auto Recovery
With instance status monitoring, you can quickly determine whether Amazon EC2 has detected any problems that might prevent your instances from running applications. Amazon EC2 performs automated checks on every running EC2 instance to identify hardware and software issues. You can view the results of these status checks to identify specific and detectable problems.
You can create an Amazon CloudWatch alarm that monitors an Amazon EC2 instance and automatically recovers the instance if it becomes impaired due to an underlying hardware failure or a problem that requires AWS involvement to repair. Terminated instances cannot be recovered. A recovered instance is identical to the original instance, including the instance ID, private IP addresses, Elastic IP addresses, and all instance metadata
Instance Status Checks
- Every EC2 instance have 2 status check
- First
- System status
- Loss of system power
- Loss of network connectivity
- Host software issues
- Host hardware issues
- System status
- Second
- Instance status
- Corrupted file system
- Incorrect instance networking
- OS Kernel issues
- Instance status
Termination Protection
💡 Termination Protection is a feature which adds an attribute to EC2 instances meaning they cannot be terminated while the flag is enabled.
It provides protection against unintended termination and also allows role separation, where junior admins can be allowed to terminate but ONLY for instances with no protection attribute set.
Horizontal and Vertical Scaling
*Within AWS Horizontal and Vertical scaling are two ways which systems have to deal with increasing or decreasing user-side load.
Adding or removing resources to a system*
Vertical Scaling
- Resizing EC2 instance
- t3.large → t3.xlarge
- Each resize requires a reboot - disruption
- Larger instances often carry a $ premium
- There is an upper cap on performance - instance size
- No application modification required
- Works for ALL applications - even monoliths
Horizontal Scaling
- Adds more instances as load increases
- Load Balancer
- Between servers and customers
- Distribute load over all servers
- Sessions, sessions, sessions
- Requires application support OR off-host sessions (stateless sessions)
- No disruption when scaling
- Connections can be moved between servers (if stateless sessions without disruption)
- Often less expensive - no large instance premium
- More granular
Instance Metadata
Instance metadata is data about your instance that you can use to configure or manage the running instance. Instance metadata is divided into categories, for example, host name, events, and security groups.
Instance metadata is accessed from an EC2 instance using
http://169.254.169.254/latest/meta-data/
- EC2 Service provides data to instances
- Accessible inside ALL instances
- http://169.254.169.254
- http://169.254.169.254/latest/meta-data/
- REMEMBER THIS
- All information about environment can be queried
- Networking
- Authentication
- User-Data
- NOT AUTHENTICATED or ENCRYPTED
- Treat metadata as something that can and will be exposed
🐳 Containers & ECS
Introduction to Containers
Virtualization Problems
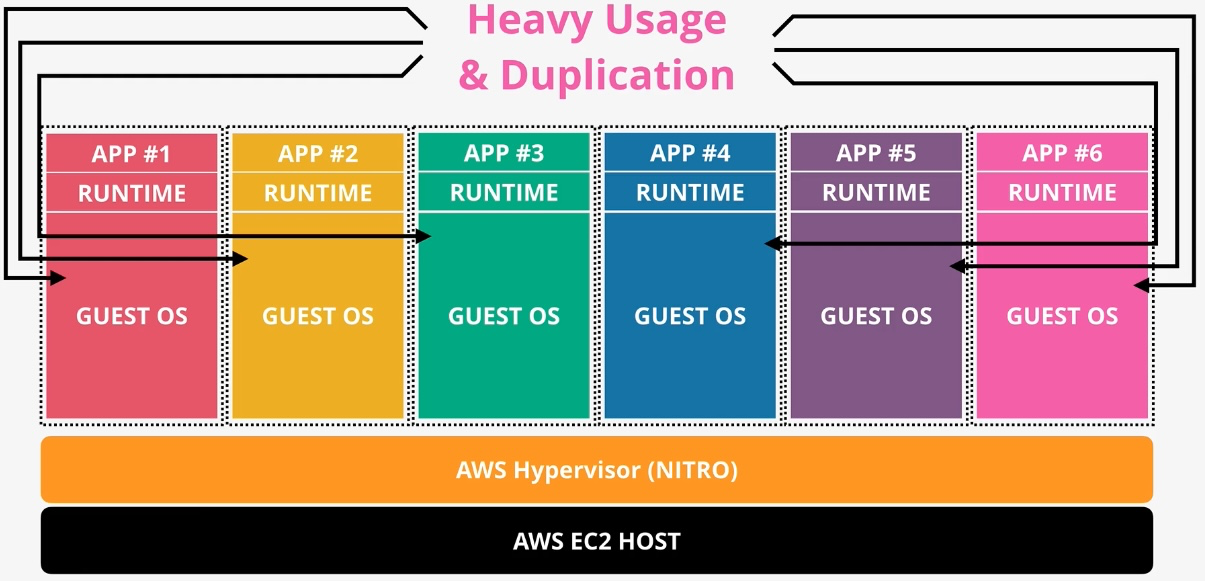
Containerization
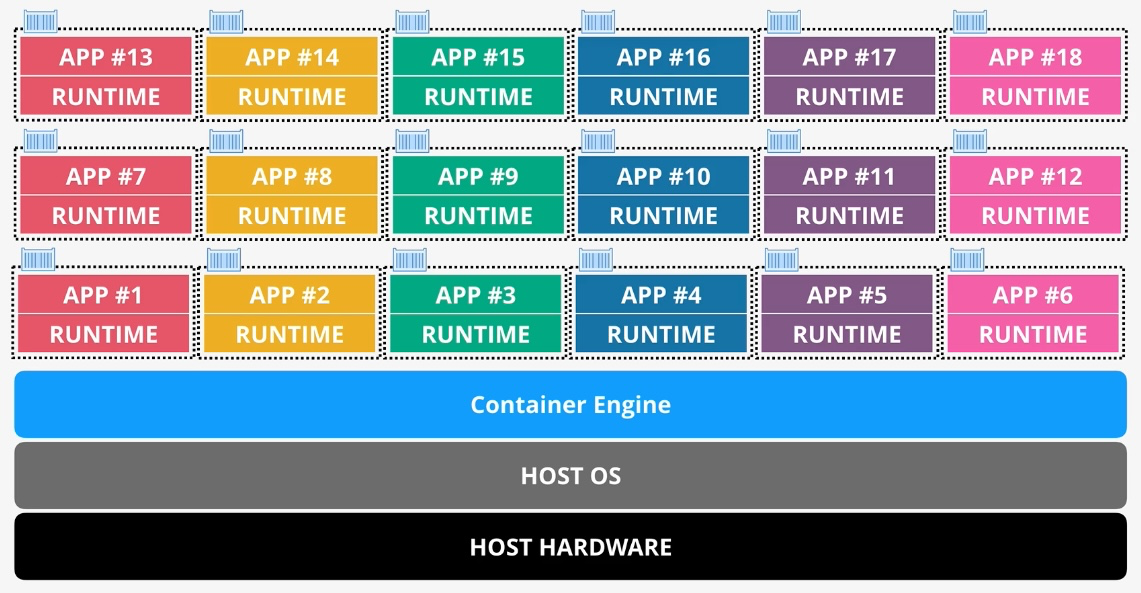
Image Anatomy
- Running copy of a docker image
- Made up of multiple layers
- Dockerfile creates docker image
- Each step creates fs layers
- Images are created from a base image or scratch
- Images contain readonly layers, changes are layered onto the image using a differential architecture
Container Anatomy
- Running copy of a docker image with one difference - one additional read/write layer
- Anything happening during running is only stored in this layer
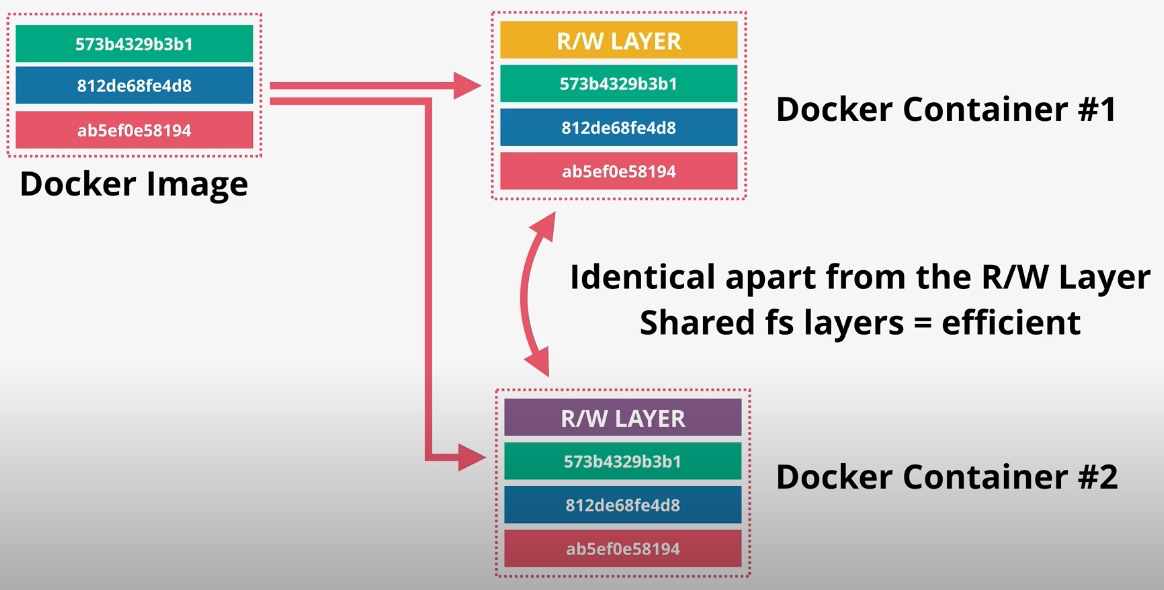
Container Registry (e.g. Docker Hub)
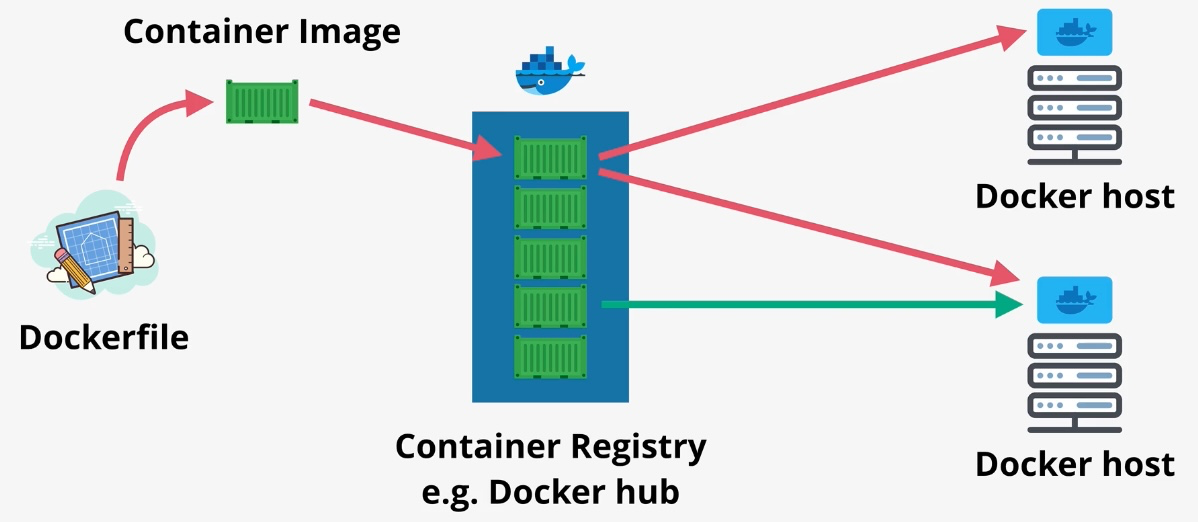
Container Key Concepts
- Dockerfiles are used to build images
- Portable - self-contained, always run as expected
- Lightweight - Parent OS used, fs layers are shared
- Container only runs the application & environment it needs
- Provides much of the isolations VM’s do
- Ports are exposed to the host and beyond
- Application stack can be multi-container…
Elastic Container Service (ECS) Concepts
Remove admin overhead of managing containers
ECS
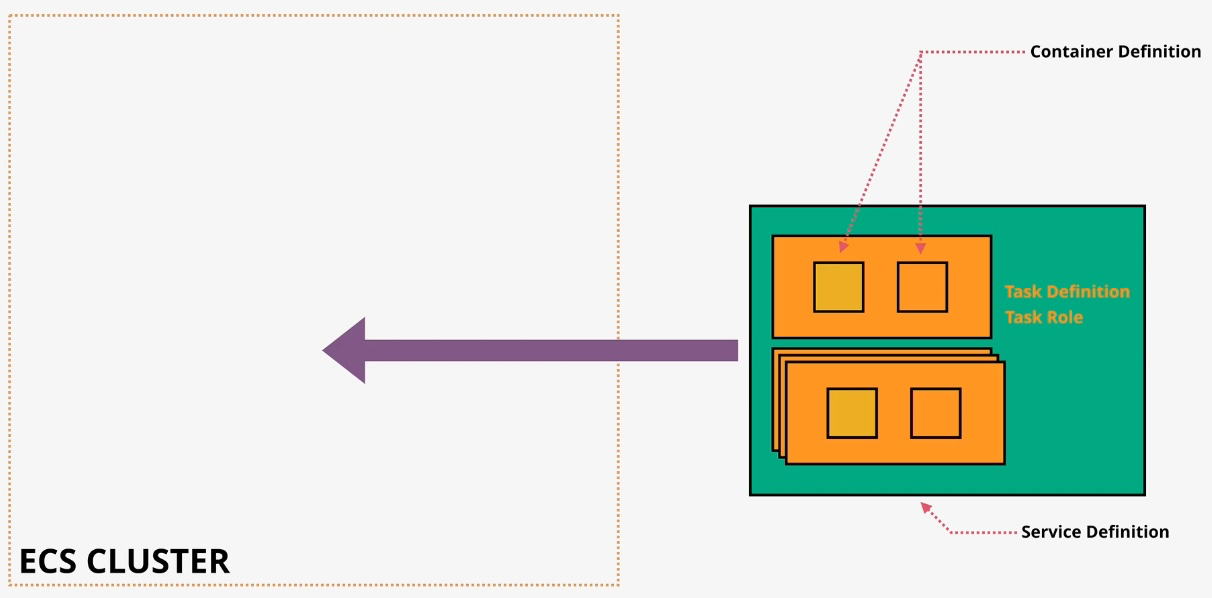
- Runs in two modes
- EC2
- Fargate
- 20 GB of free ephemeral storage
- Create ECS Cluster
- ECR - Elastic Container Registry (AWS alt to Docker Hub)
- Container definition - Tell container where container image is
- Task definition - One or many container inside it
- Represents the application as a whole
- Store the resources used by the task
- CPU, Memory, Network mode, compatibility (ec2 vs fargate)
- Task role
- IAM role that the task can use
- Best way to give tasks access to resources
- Service definition
- How many copies of a task we want to run
- Add Load balancer
- Scaling
- High availability
- Service is what is deployed into the ECS Cluster!
ECS Concepts
- Container Definition - Image & Ports
- Task Definition - Security (Task Role), Container(s), Resources
- Task Role - IAM Role which the TASK assumes
- Service - How many copies, HA, Restarts
ECS - Cluster Mode
ECS is capable of running in EC2 mode or Fargate mode.
EC2 mode deploys EC2 instances into your AWS account which can be used to deploy tasks and services.
With EC2 mode you pay for the EC2 instances regardless of container usage
Fargate mode uses shared AWS infrastructure, and ENI's which are injected into your VPC
You pay only for container resources used while they are running
EC2 Mode
- EC2 cluster is created within a VPC - benefit from multiple AZ’s
- ASG - Auto Scaling Group
- Horizontal scaling
- Container Registry (ECR)
- If you want to use containers, but need to manage the host the container is running on - EC2!
- Keep overhead and flexibility
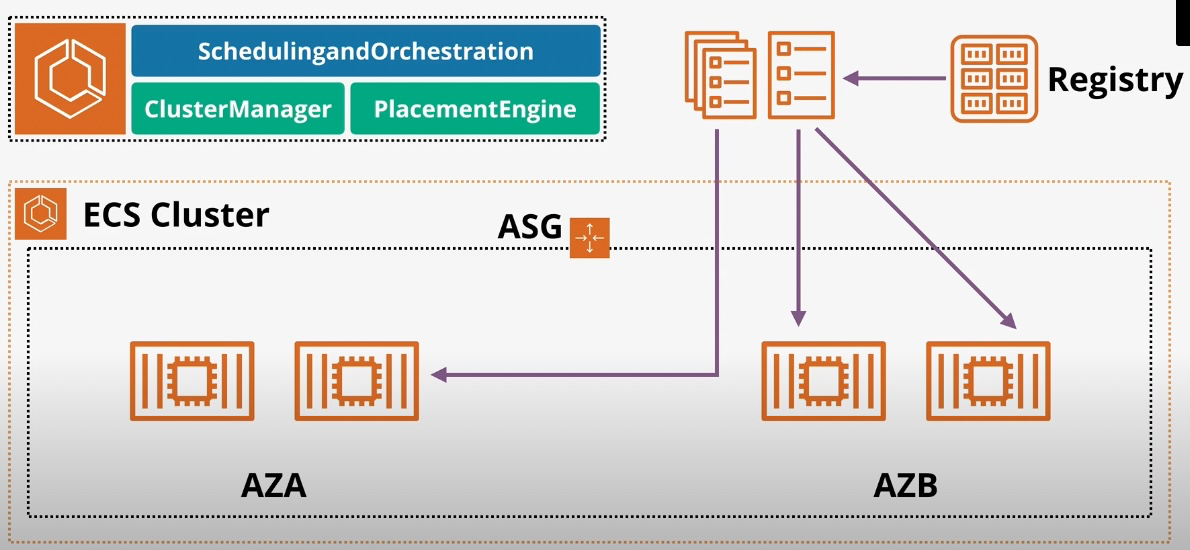
Fargate Mode
- “Serverless” - No servers to manage
- Not paying for EC2 instances regardless of you’re using them or not
- How containers are hosted are different from EC2 mode
- Fargate Shared Infrastructure
- Tasks are services actually running from a shared infrastructure platform
- Tasks injected into the VPC - given ENI
- A lot of customizability
- You only pay for the containers you are using based on the resources you consume!
EC2 vs ECS (EC2) vs Fargate
- If you use containers - ECS!
- Large workload - price conscious - EC2 Mode
- Beware of management overhead
- Large workload - overhead conscious - Fargate
- Small/burst workloads - Fargate
- Batch/periodic workloads - Fargate
Elastic Container Registry (ECR)
- Managed container image registry service
- like Dockerhub but for AWS
- Each AWS account has a public and private registry
- Each registry can have many repository
- Each repository can contain many images
- Images can have several tags
- Public = public R/O
- R/W requires permissions
- Private = permissions required for any R/O or R/W
- Integrated with IAM
- Image scanning, basic and enhanced (inspector)
- nr real-time Metrics → CW(auth, push, pull)
- API actions = CloudTrail
- Events → EventBridge
- Replication
- Cross-region AND Cross-account
Kubernetes 101
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications.
Cluster Structure
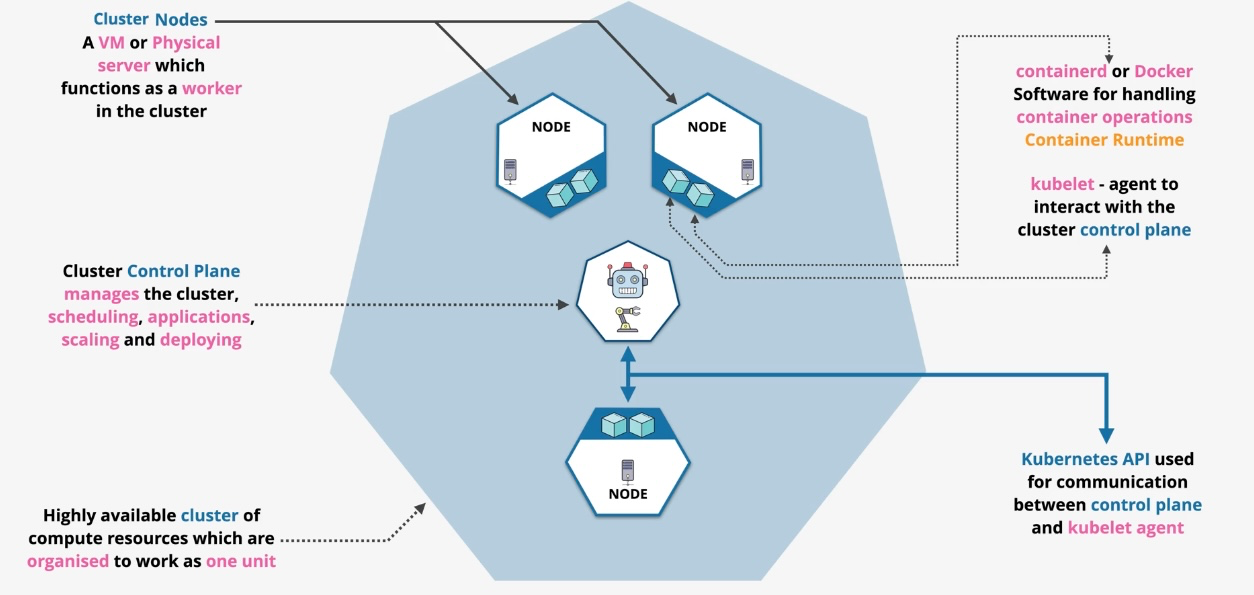
Cluster Detail
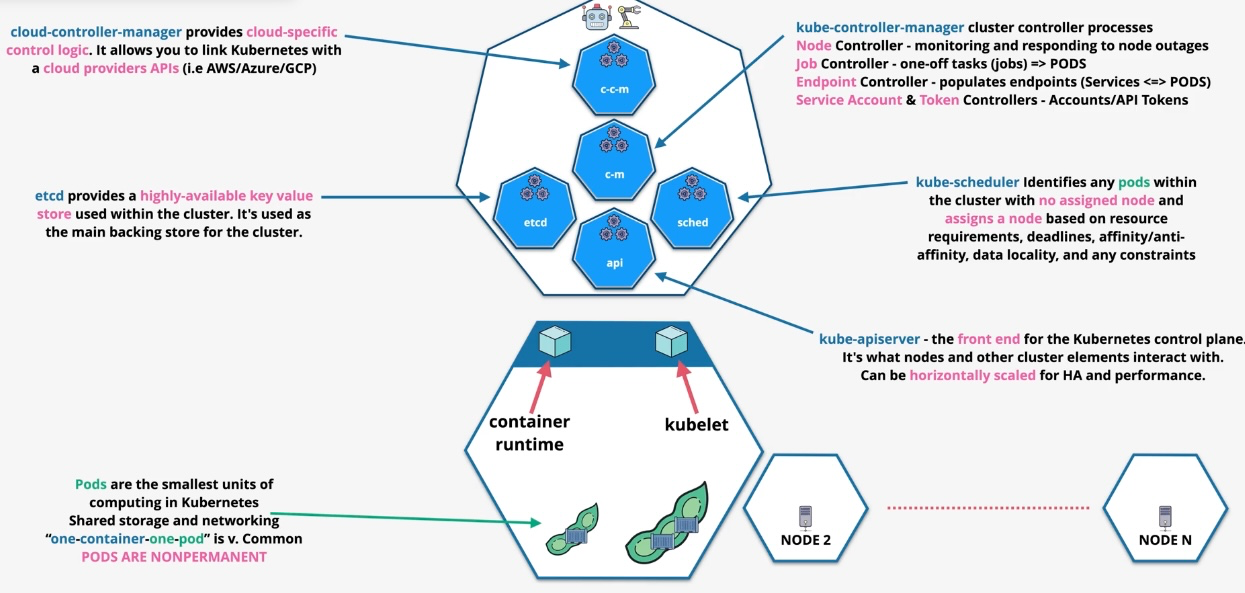
Key Concepts
- Cluster - A deployment of Kubernetes, management, orchestration …
- Node - Resources; pods are placed on nodes to run
- Pod - 1+ containers; smallest unit in Kubernetes; often 1 container 1 pod
- Service - Abstraction, service running on 1 ore more pods
- Job - ad-hoc, creates one ore more pods until completion
- Ingress - Exposes a way into a service (Ingress → Routing → Service → 1+ Pods)
- Ingress Controller - used to provide ingress (e.g. AWS LB Controller uses ALB/NLB)
- Persistent Storage (PV) - Volume whose lifecycle lives beyond any 1 pod using it
Elastic Kubernetes Service (EKS) 101
Amazon Elastic Kubernetes Service (Amazon EKS) is a fully-managed, Kubernetes implementation that simplifies the process of building, securing, operating, and maintaining Kubernetes clusters on AWS. Kubernetes as a Service (KaaS?)
- AWS Managed Kubernetes - open source & cloud agnostic
- AWS, Outposts, EKS Anywhere, EKS Distro
- Control plane scales and runs on multiple AZs
- Integrates with AWS services - ECR, ELB, IAM, VPC
- EKS Cluster = EKS Control Plane & EKS Nodes
- etcd distributed across multiple AZs
- Nodes - Self managed, managed node groups or Fargate pods
- Windows, GPU, Inferentia, Bottlerocket, Outposts, Local zones
- Check node type
- Windows, GPU, Inferentia, Bottlerocket, Outposts, Local zones
- Storage Providers include - EBS, EFS, FSx Lustre, FSx for NetApp ONTAP
- Two VPC!
- AWS Managed
- Customer VPC
- These will communicate
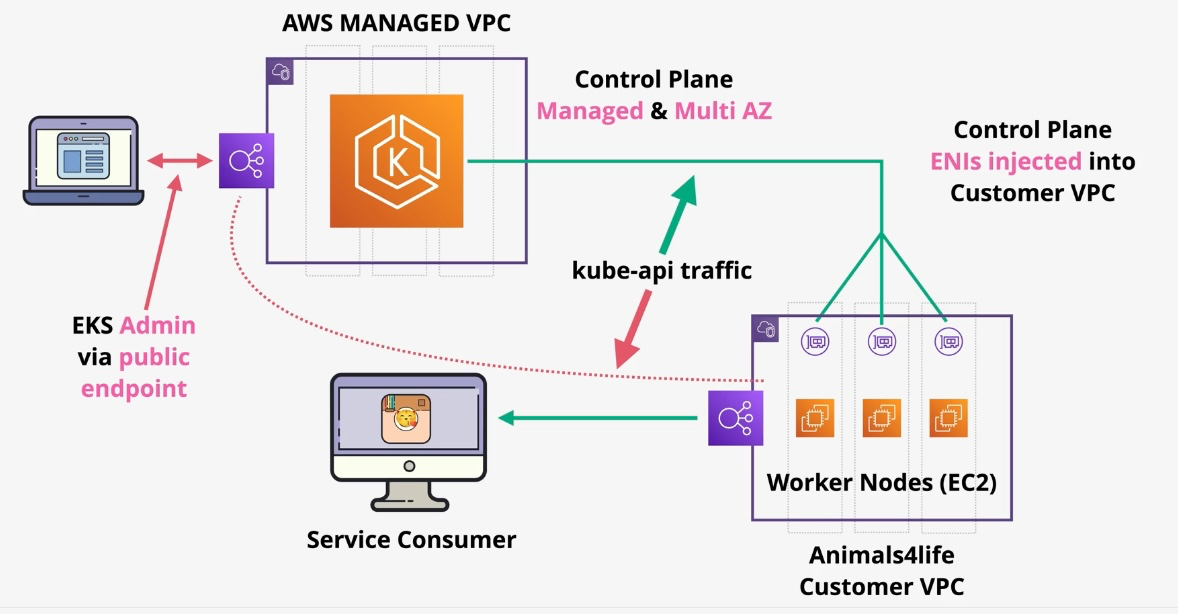
🉐 Advanced EC2
Bootstrapping EC2 Using User Data
EC2 Bootstrapping is the process of configuring an EC2 instance to perform automated install & configuration steps 'post launch' before an instance is brought into service. With EC2 this is accomplished by passing a script via the User Data part of the Meta-data service - which is then executed by the EC2 Instance OS
EC2 Bootstrapping
-
Bootstrapping is a process which allows a system to self-configure
-
Bootstrapping allows EC2 Build Automation
-
Anything in User Data is executed by the instance OS
-
ONLY on launch
-
EC2 doesn’t interpret, the OS needs to understand the User Data
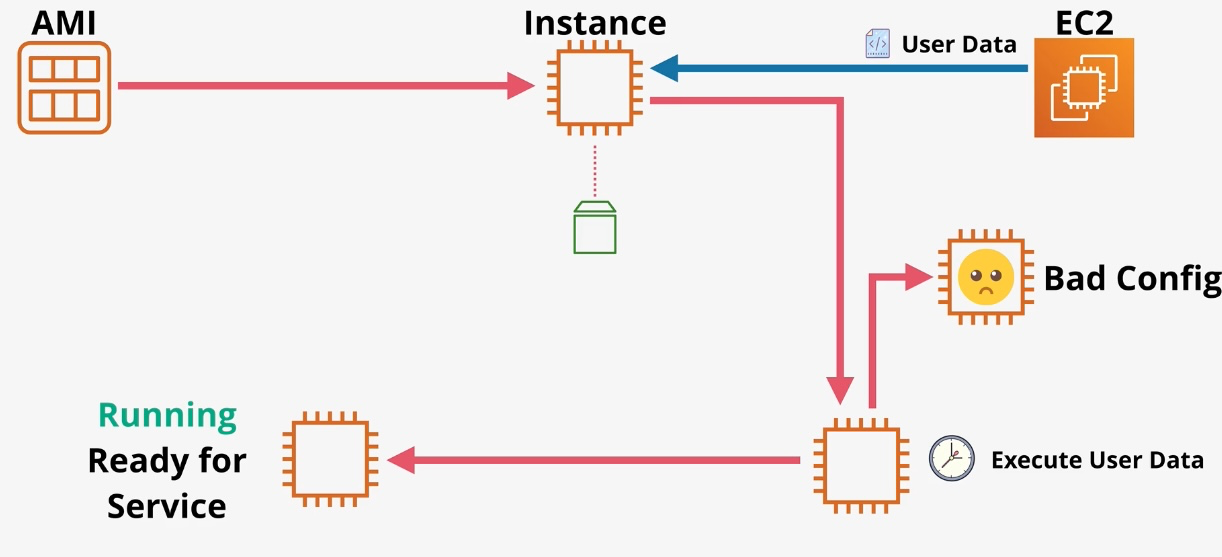
User Data Key Points
-
It’s opaque to EC2 - its just a block of data
-
It’s NOT secure - don’t use it for passwords or long term credentials (ideally)
-
User data is limited to 16 KB in size
-
Can be modified when instance is stopped
-
But only executed once at launch
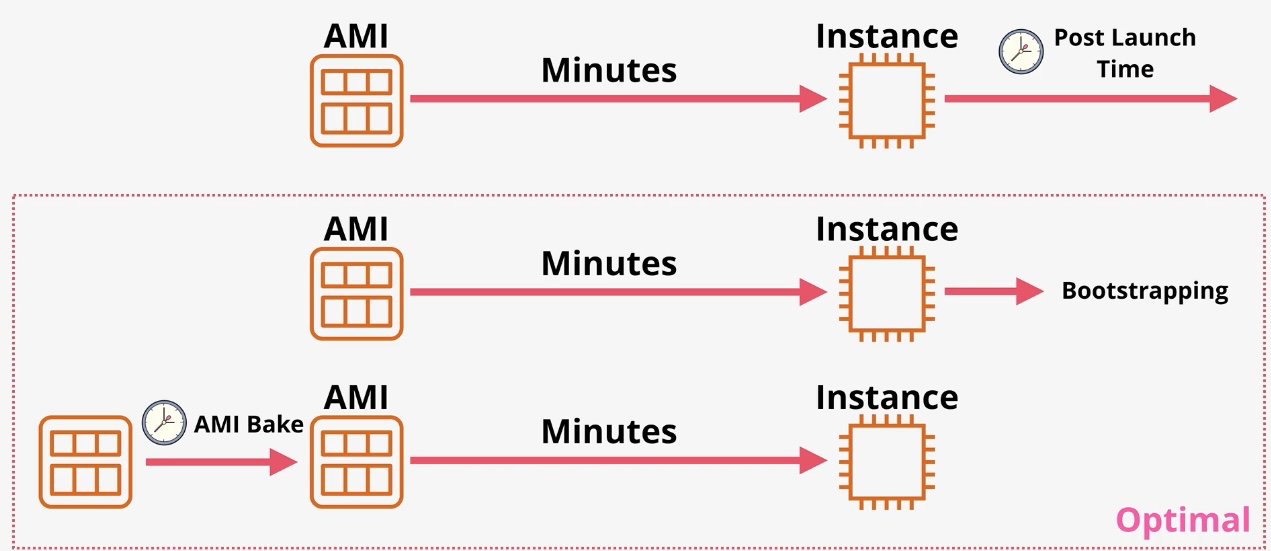
Enhanced Bootstrapping with CFN-INIT
CFN-INIT is a powerful desired-state-like configuration engine which is part of the CFN suite of products.
It allows you to set a state for things like packages, users, groups, sources and files within resources inside a template - and it will make that change happen on the instance, performing whatever actions are required.
Creation policies create a 'WAIT STATE' on resources .. not allowing the resource to move to CREATE_COMPLETE until signalled using the cfn-signal tool.
- cfn-init helper script - installed on EC2 OS
- Simple configuration management system
- Procedural (User Data) vs Desired State (cfn-init)
- Packages, Groups, Users, Sources, Files, Commands and Services
- Provided with directives via Metadata and AWS::ClodFormation::Init on a CFN resource
- Variables passed into User Data by CloudFormation
cfn-init
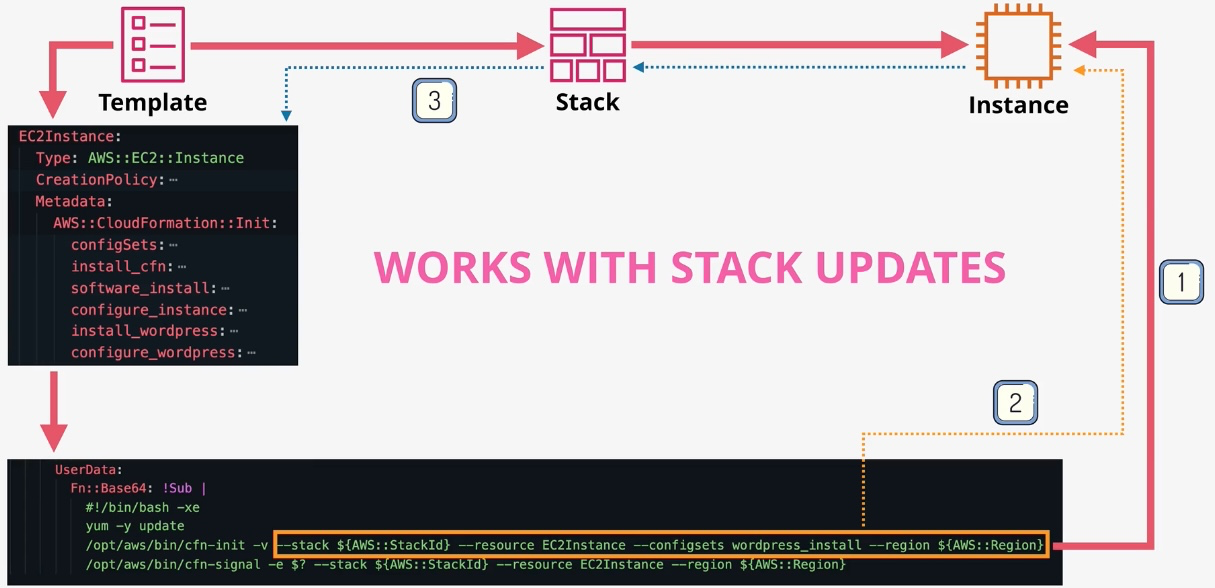
CreationPolicy and Signals
-e $?= output of previous command
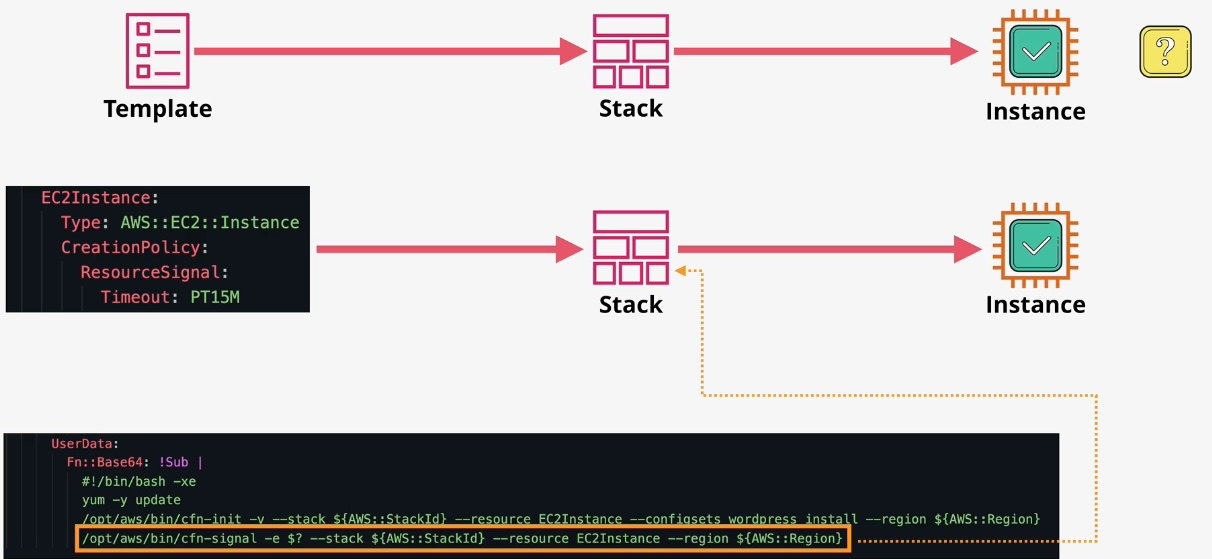
EC2 Instance Roles & Profile
EC2 Instance roles and Instance Profiles are how applications running on an EC2 instance can be given permissions to access AWS resources on your behalf.
Short Term Temporary credentials are available via the EC2 Instance Metadata and are renewed automatically by the EC2 and STS Services.
Starts with an IAM role with a permissions policy. EC2 instance role allows the EC2 service to assume that role.
The instance profile is the item that allows the permissions to get inside the instance. When you create an instance role in the console, an instance profile is created with the same name.
When IAM roles are assumed, you are provided temporary roles based on the permission assigned to that role. These credentials are passed through instance meta-data.
EC2 and the secure token service ensure the credentials never expire.
EC2 Instance Roles
- Credentials are inside meta-data
- iam/security-credentials/role-name
- Automatically rotated - Always valid
- Should always be used rather than adding access keys into instance
- CLI tools will use ROLE credentials automatically
AWS Systems Manager Parameter Store
The SSM Parameter store is a service which is part of Systems Manager which allows the storage and retrieval of parameters - string, stringlist or secure string.
The service supports encryption which integrates with KMS, versioning and can be secured using IAM.
The service integrates natively with many AWS services - and can be accessed using the CLI/APIs from anywhere with access to the AWS Public Spare Endpoints.
aws ssm get-parameters --names /my-app/dbstring # return JSON object
aws ssm get-parameters-by-path --path /my-app/ # return three parameters - three JSON objects
aws ssm get-parameters-by-path --path /my-app/ --with-decryption # decrypt encrypted parameters. require permissions to both interact with SSM and KMS
SSM Parameter Store
- Storage for configuration & secrets
- String, StringList & SecureString
- License codes, Database Strings, Full Configs & Passwords
- Hierarchies & Versioning
- Plaintext and Ciphertext
- Public Parameters - Latest AMIs per region

System and Application Logging on EC2
CloudWatch and CloudWatch Logs cannot natively capture data inside an instance.
Logging on EC2
- CloudWatch is for metrics
- CloudWatch Logs is for logging
- Neither capture data inside an instance
- CloudWatch Agent is required - runs inside the instance
- Needs configuration and permissions
EC2 Placement Groups
Allows you to influence placement, having instances physically closer to each other
Cluster Placement Groups
Pack Instances close together. PERFORMANCE!
- Absolute highest performance possible within EC2
- In a single AZ
- Same Rack
- Sometime same host
- All members have direct connections to each other
- Up to 10Gbps per stream
- 5Gbps normally
- Lowest latency and max PPS possible
- Tradeoff: Little to no resilience
- Can’t span AZs - one AZ only - locked when launching first instance
- Can span VPC peers - but impacts performance
- Requires a supported instance type
- Use the same type of instance (not mandatory)
- Launch at the same time (not mandatory, very recommended)
- 10Gbps single stream performance
- Use cases:
- Performance
- Fast speeds
- Low latency
Spread Placement Groups
Keep instances separated
- Can span multiple AZs
- Distinct racks - if a single rack fail, fault is isolated to rack
- 7 instances per AZ - HARD LIMIT - Isolated infrastructure limit
- Provides infrastructure isolation
- Each rack has its own network and power source
- Not supported for Dedicated Instances or Hosts
- Use case
- Small number of critical instances that need to be kept separated from each other
Partition Placement Groups
Groups of instances spread apart
- Across multiple AZs
- Divided into “partitions”
- MAX 7 per AZ
- Each partition has its own racks - no sharing between partitions
- Instances can be placed in a specific partition
- or auto placed
- Great for topology aware applications
- HDFS, HBase and Cassandra
- Contain the impact of failure to part of an application
EC2 Dedicated Hosts
Dedicated hosts are EC2 Hosts which support a certain type of instance which are dedicated to your account.
You can pay an on-demand or reserved price for the hosts and then you have no EC2 instance pricing to pay for instances running on these dedicated hosts.
Generally dedicated hosts are used for applications which use physical core/socket licensing
- EC2 Host dedicated to you
- Specific family, e.g. a1, c5, m5
- No instance charges - you pay for the host
- On-demand & Reserved options available
- Host hardware has physical sockets and cores

Limitations & Features
- AMI Limits - RHEL, SUSE Linux, and Windows AMIs aren’t supported
- Amazon RDS instances are not supported
- Placement groups are not supported for dedicated hosts
- Hosts can be shared with other ORG Account… RAM
Enhanced Networking & EBS Optimized
Enhanced networking is the AWS implementation of SR-IOV, a standard allowing a physical host network card to present many logical devices which can be directly utilized by instances.
This means lower host CPU usage, better throughput, lower and consistent latency
EBS optimization on instances means dedicated bandwidth for storage networking - separate from data networking.
Enhanced Networking
- Uses SR-IOV - NIC (Network Interface Card) is virtualization aware
- The host has multiple logical cards per physical card, which interacts with the instance
- Higher I/O & Lower Host CPU Usage
- More bandwidth
- Higher packets-per-second (PPS)
- Consistent lower latency
- Either enabled by default or available free of charge (for most instances)
EBS Optimized
- EBS = Block storage over the network
- Historically network was shared
- Data and EBS
- EBS Optimized means dedicated capacity for EBS
- Most instances support and have enabled by default
- Some support, but enabling costs extra
🛣️ Route 53 - Global DNS
R53 Public Hosted Zones
A public hosted zone is a container that holds information about how you want to route traffic on the internet for a specific domain which is accessible from the public internet
💡 Two types of zones in R53: Public and Private
R53 Hosted Zones
- A R53 Hosted Zone is a DNS DB for a domain, e.g. a4l.org
- Globally resilient (multiple DNS Servers)
- Created with domain registration via R53 - can be created separately
- Host DNS Records (A, AAAA, MX, NS, TXT,…)
- Hosted Zones are what the DNS system references - Authoritative for a domain e.g. a4l.org
- DNS Database
R53 Public Hosted Zones
- DNS Database (Zone file) hosted by R53 (Public Name Servers)
- Accessible from the public internet & VPCs
- Hosted on “4” R53 Name Servers (NS) specific for the zone
- use “NS records” to point at these NS (connect to global DNS)
- Resource Records (RR) created within the Hosted Zone
- Externally registered domains can point at R53 Public Zone
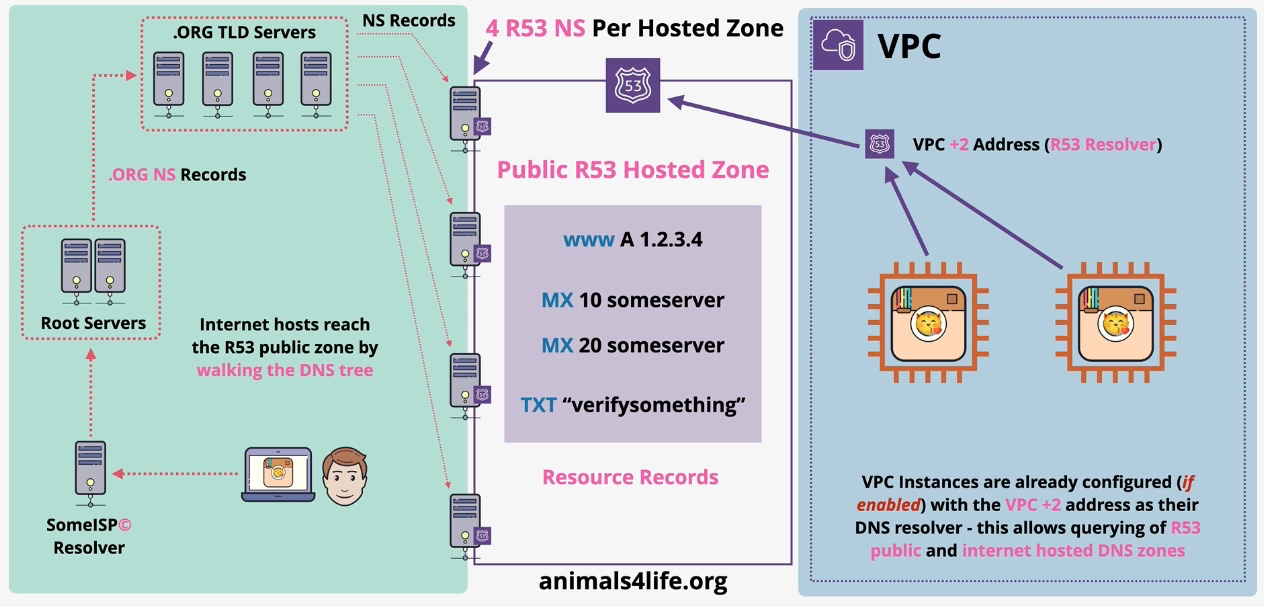
R53 Private Hosted Zones
A private hosted zone is a container that holds information about how you want Amazon Route 53 to respond to DNS queries for a domain and its subdomains within one or more VPCs that you create with the Amazon VPC service
- A public hosted zone, which isn’t public
- Associated with VPCs
- Only accessible in those VPCs
- Using different accounts is supported via CLI/API
- Split-view (overlapping public & private) for PUBLIC and INTERNAL use with the same zone name
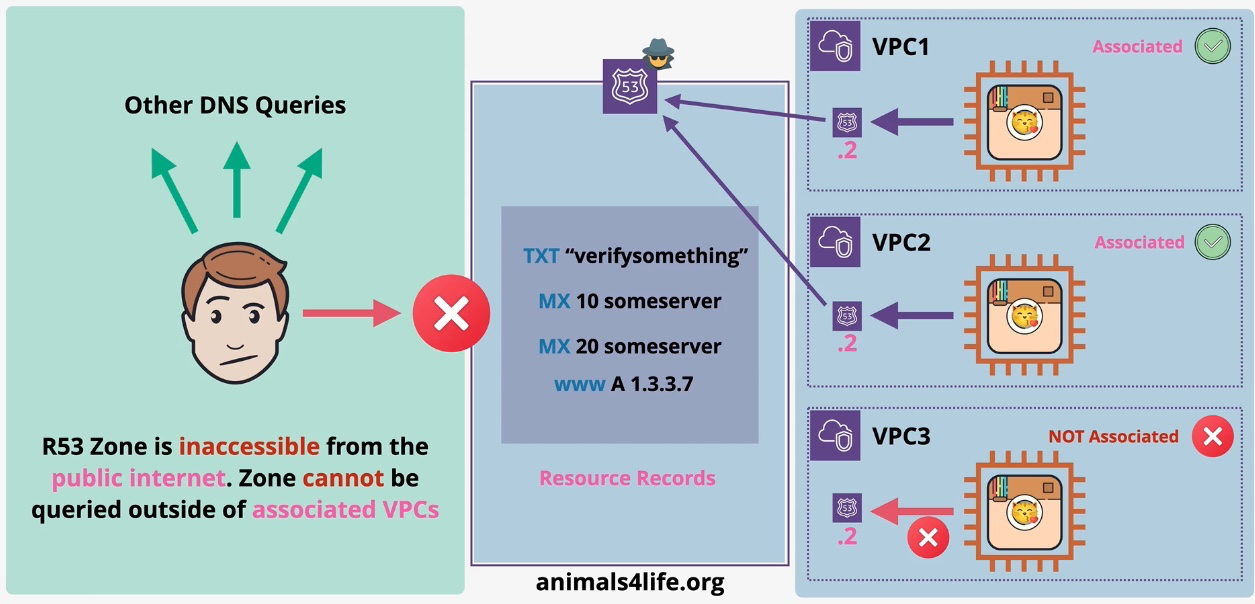
R53 Split View Hosted Zones
- Public zone is a subset of the private zone, limiting access to some resources
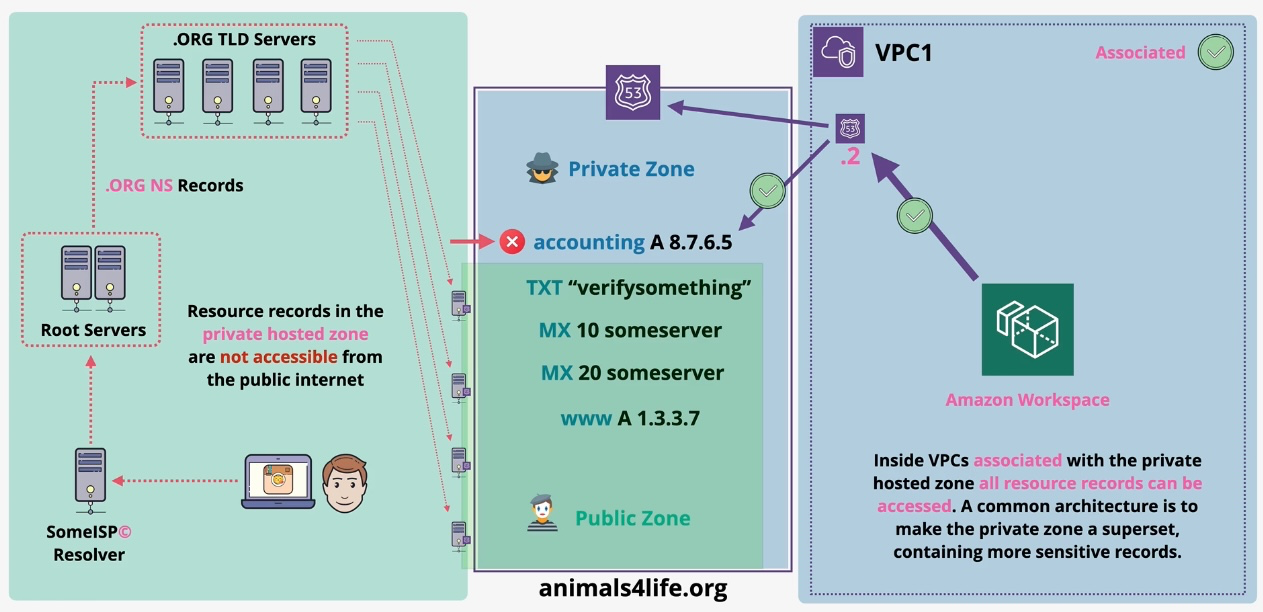
CNAME vs R53 Alias
This lesson steps through the shortcomings of the CNAME record type, the differences between CNAME and ALIAS and when to use one v's the other.
R53 CNAME vs Alias (the problem)
- “A” Maps a NAME to an IP Address
- catagram.io → 1.3.3.7
- CNAME maps a NAME to another NAME
- www.catagram.io → catagram.io
- CNAME is invalid for naked/apex (catagram.io)
- Many AWS services us a DNS Name (ELBs)
- With just CNAME - catagram.io → ELB would be invalid
Alias
- ALIAS records map a NAME to an AWS resource
- Can be used both for naked/apex and normal records
- For non apex/naked - functions like CNAME
- There is no charge for ALIAS requests pointing at AWS resources
- For AWS services - default to picking ALIAS
- Should be the same “type” as what the records is pointing at
- Use ALIAS when pointing at:
- API Gateway
- CloudFront
- Elastic Beanstalk
- ELB
- Global Accelerator
- S3
R53 Health Checks
Amazon Route 53 health checks monitor the health and performance of your web applications, web servers, and other resources. Each health check that you create can monitor one of the following:
- The health of a specified resource, such as a web server
- The status of other health checks
- The status of an Amazon CloudWatch alarm
-
Health check are separate from, but are used by records
-
Health checkers located globally
-
Health checker check every 30s (every 10s costs extra)
-
TCP, HTTP/HTTPS, HTTP/HTTPS with String Matching
-
Healthy or Unhealthy
-
Endpoint, CloudWatch Alarm, Check of Checks (Calculated)
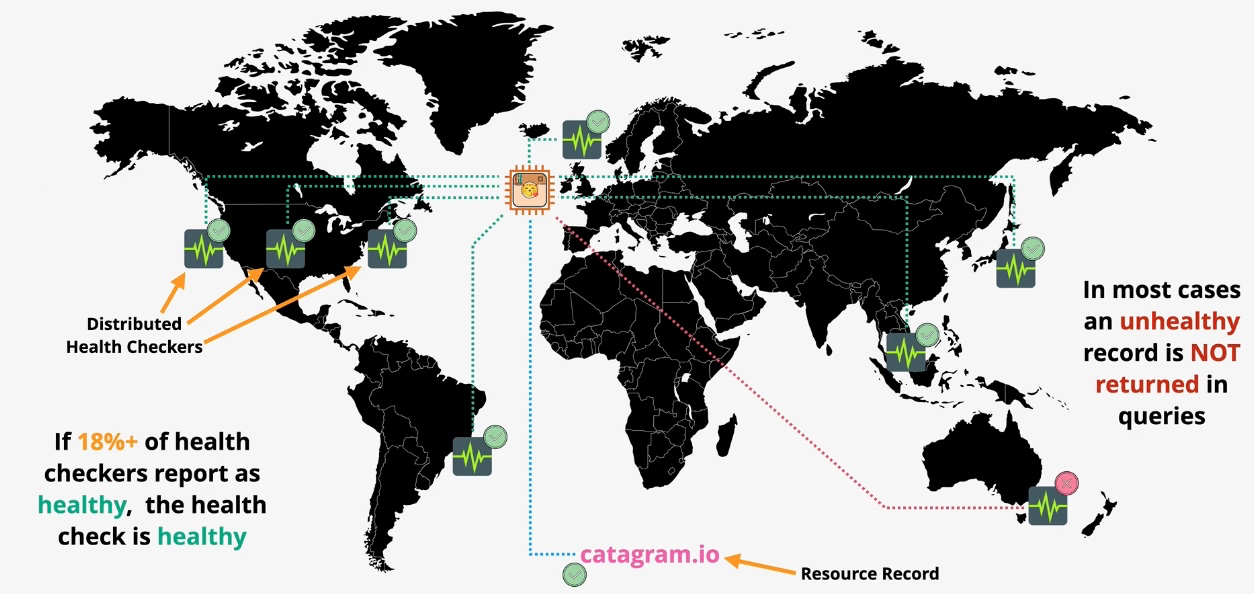
❗Failover: Active/Passive ❗
Active-Active Failover
Use this failover configuration when you want all of your resources to be available the majority of the time. When a resource becomes unavailable, Route 53 can detect that it’s unhealthy and stop including it when responding to queries.
In active-active failover, all the records that have the same name, the same type (such as A or AAAA), and the same routing policy (such as weighted or latency) are active unless Route 53 considers them unhealthy. Route 53 can respond to a DNS query using any healthy record.
Active-Passive Failover
Use an active-passive failover configuration when you want a primary resource or group of resources to be available the majority of the time and you want a secondary resource or group of resources to be on standby in case all the primary resources become unavailable. When responding to queries, Route 53 includes only the healthy primary resources. If all the primary resources are unhealthy, Route 53 begins to include only the healthy secondary resources in response to DNS queries.
Configuring an Active-Passive Failover with Weighted Records and configuring an Active-Passive Failover with Multiple Primary and Secondary Resources are incorrect because an Active-Passive Failover is mainly used when you want a primary resource or group of resources to be available most of the time and you want a secondary resource or group of resources to be on standby in case all the primary resources become unavailable. In this scenario, all of your resources should be available all the time as much as possible which is why you have to use an Active-Active Failover instead.
Configuring an Active-Active Failover with One Primary and One Secondary Resource is incorrect because you cannot set up an Active-Active Failover with One Primary and One Secondary Resource. Remember that an Active-Active Failover uses all available resources all the time without a primary nor a secondary resource.
Routing Policy 1: Simple Routing
Simple routing lets you configure standard DNS records, with no special Route 53 routing such as weighted or latency. With simple routing, you typically route traffic to a single resource, for example, to a web server for your website.
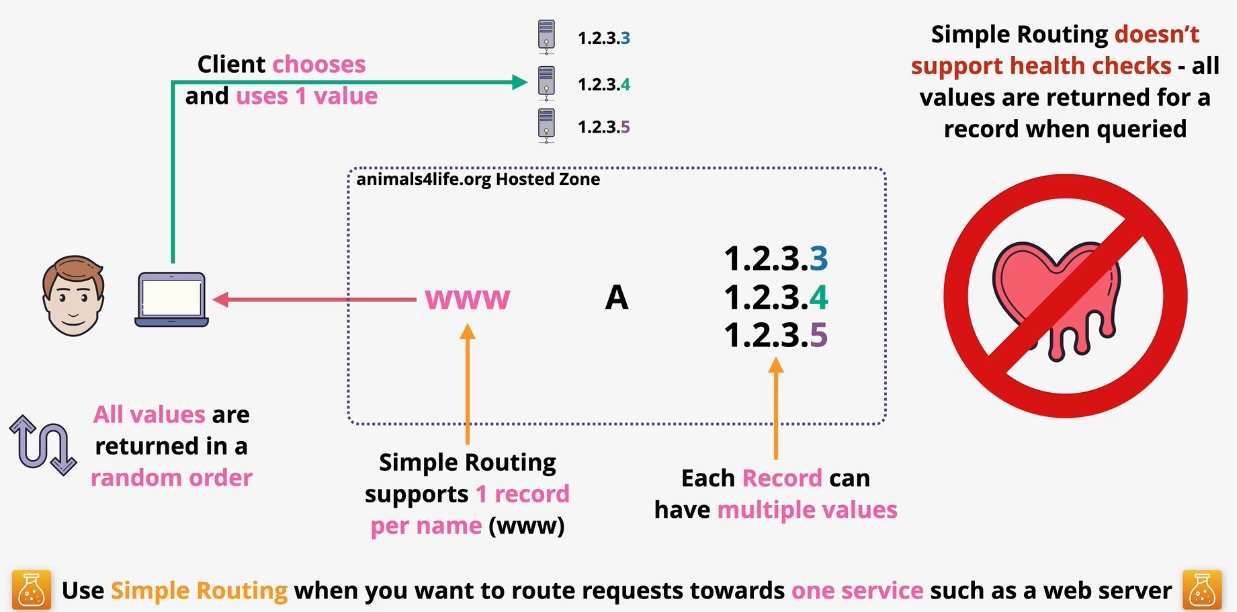
Routing Policy 2: Failover Routing
Failover routing lets you route traffic to a resource when the resource is healthy or to a different resource when the first resource is unhealthy 1st of four routing policies
💡 Create two records of the same name and the same type. One is set to be the primary and the other is the secondary. This is the same as the simple policy except for the response. Route 53 knows the health of both instances. As long as the primary is healthy, it will respond with this one. If the health check with the primary fails, the backup will be returned instead. This is set to implement active - passive failover.
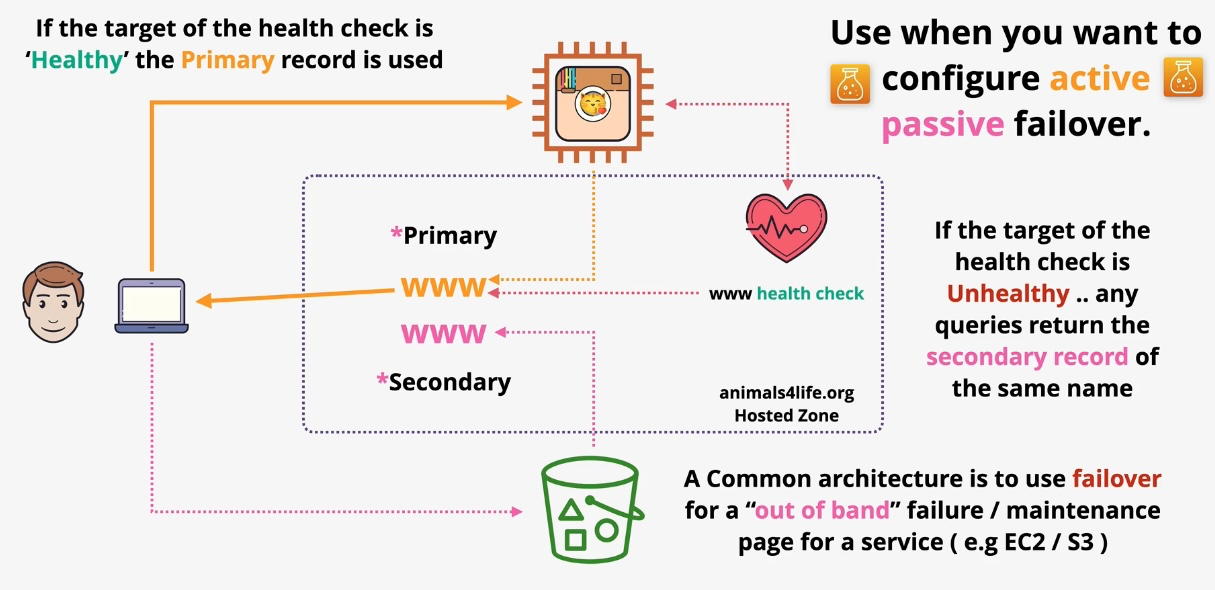
Routing Policy 3: Multi Value Routing
Multivalue answer routing lets you configure Amazon Route 53 to return multiple values, such as IP addresses for your web servers, in response to DNS queries. You can specify multiple values for almost any record, but multivalue answer routing also lets you check the health of each resource, so Route 53 returns only values for healthy resources
💡 Simple records use one name and multiple values in this record. These will be health checked and the unhealthy responses will automatically be removed. With multi-value, you can have multiple records with the same name and each of these records can have a health check. R53 using this method will respond to queries with any and all healthy records, but it removes any records that are marked as unhealthy from those responses. This removes the problem with simple routing where a single unhealthy record can make it through to your customers. Great alternative to simple routing when you need to improve the reliability, and it's an alternative to failover when you have more than two records to respond with, but don't want the complexity or the overhead of weighted routing.
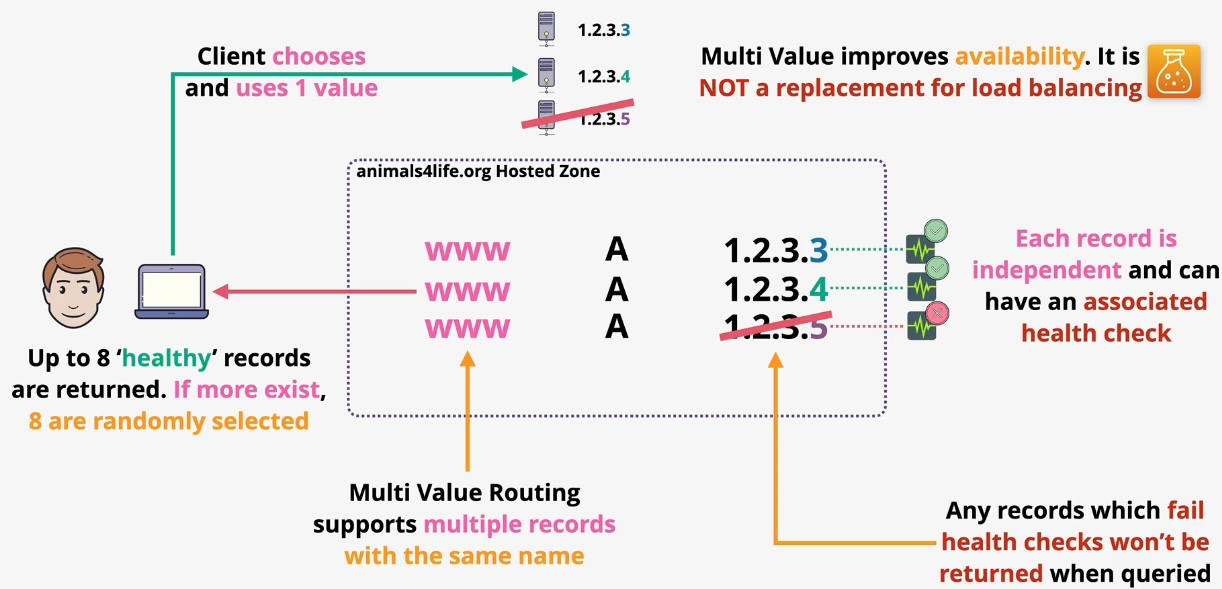
Routing Policy 4: Weighted Routing
Weighted routing lets you associate multiple resources with a single domain name (catagram.io) and choose how much traffic is routed to each resource. This can be useful for a variety of purposes, including load balancing and testing new versions of software.
💡 Create multiple records of the same name within the hosted zone. For each of those records, you provide a weighted value. The total weight is the same as the weight of all the records of the same name. If all of the parts of the same name are healthy, it will distribute the load based on the weight. If one of them fails its health check, it will be skipped over and over again until a good one gets hit. This can be used for migration to separate servers.
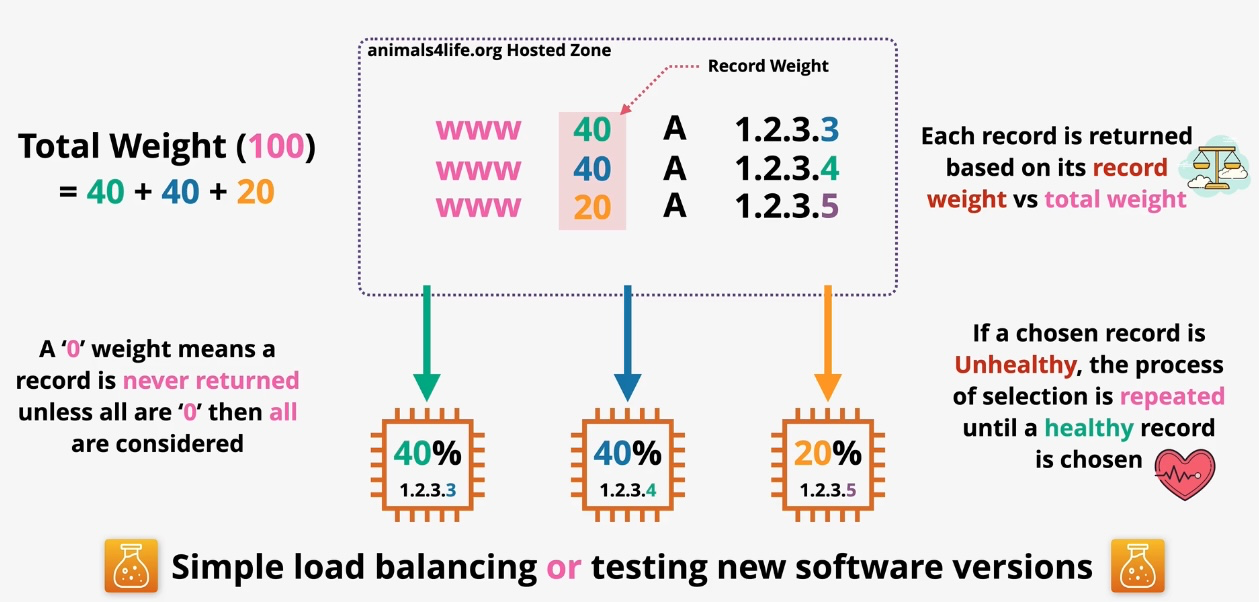
Routing Policy 5: Latency Routing
If your application is hosted in multiple AWS Regions, you can improve performance for your users by serving their requests from the AWS Region that provides the lowest latency.
💡 Multiple records in a hosted zone can be created with the same name and same type. When a client request arrives, it knows which region the request comes from. It knows the lowest latency and will respond with the lowest latency.
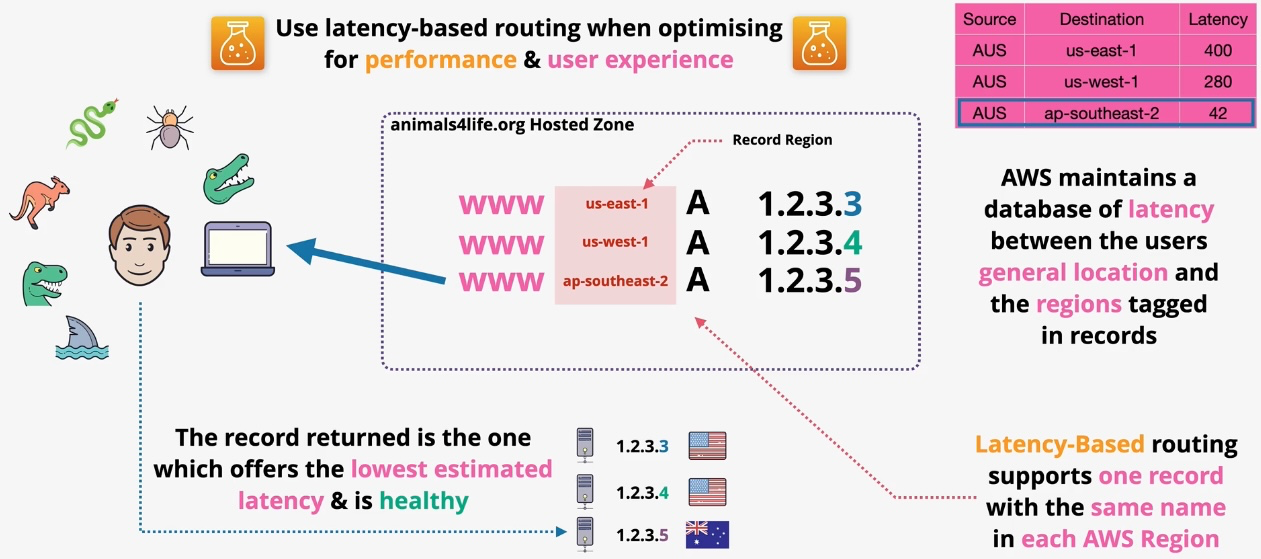
Routing Policy 6: Geolocation Routing
Geolocation routing lets you choose the resources that serve your traffic based on the geographic location of your users, meaning the location that DNS queries originate from.
💡 Focused to delivering results matching the query of your customers. The record will first be matched based on the country if possible. If this does not happen, the record will be checked based on the continent. Finally, if nothing matches again it will respond with the default response. This can be used for licensing rights. If overlapping regions occur, the priority will always go to the most specific or smallest region. The US will be chosen over the North America record.
- Good for restricting content to a certain location
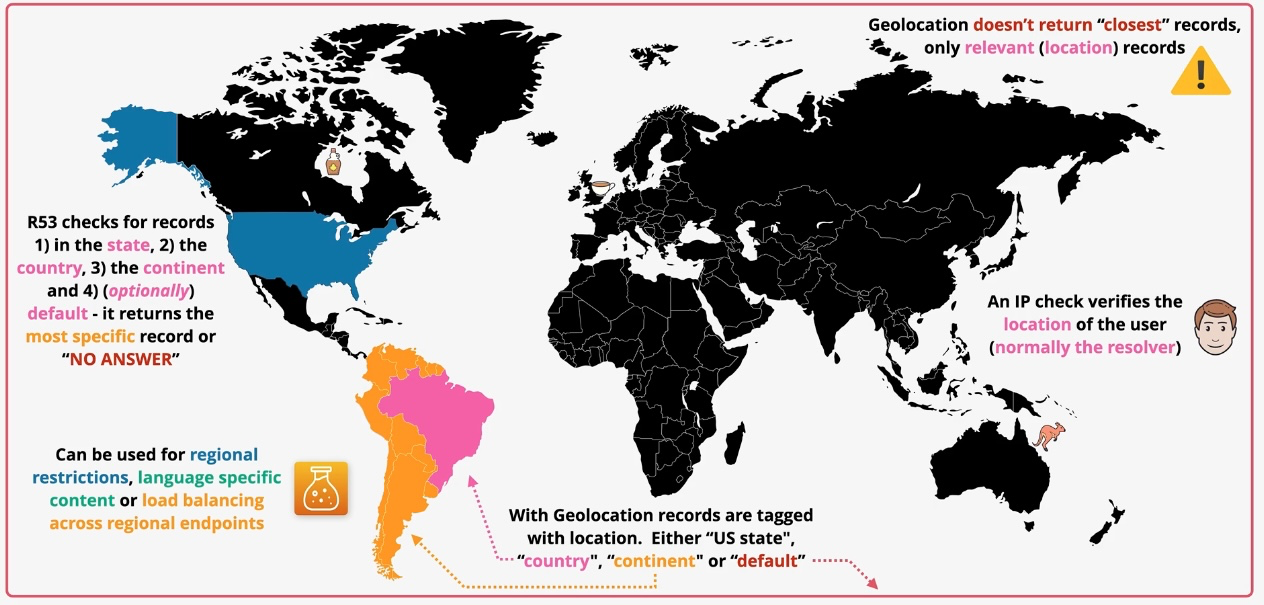
Routing Policy 7: Geoproximity Routing
Geoproximity routing lets Amazon Route 53 route traffic to your resources based on the geographic location of your users and your resources. You can also optionally choose to route more traffic or less to a given resource by specifying a value, known as a bias. A bias expands or shrinks the size of the geographic region from which traffic is routed to a resource.
- As close to customers as possible
- Calculate distance between customer and records
- Define rules and a bias
- Bias: + or - bias can be added to rules
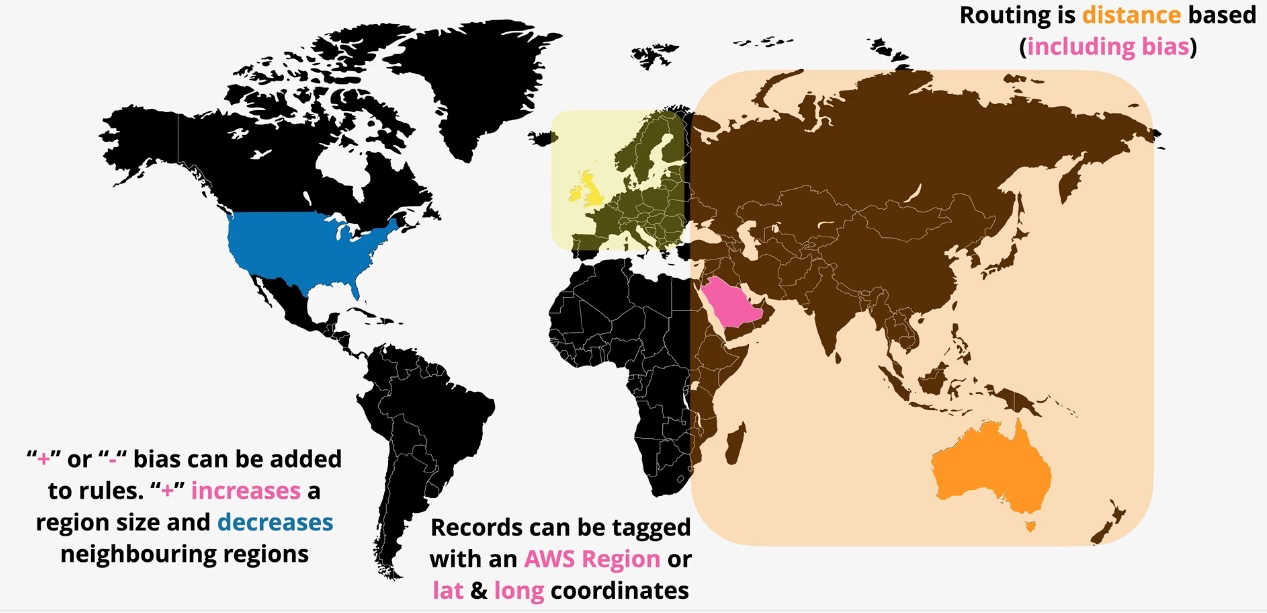
R53 Interoperability
This lesson details how Route53 provides Registrar and DNS Hosting features and steps through architectures where it is used for BOTH, or only one of those functions - and how it integrates with other registrars or DNS hosting.
- R53 normally has two jobs - Domain registrar and Domain Hosting
- R53 can do BOTH, or either registrar or hosting
- R53 Accepts your money (domain registration fee)
- R53 allocates 4 Names Servers (NS) (Domain hosting)
- R53 Creates a zone file (domain hosting) on the above NS
- R53 communicates with the registry of the TLD (Domain Registrar)
- sets the NS records for the domain to point at the 4 NS above
R53: Both Roles
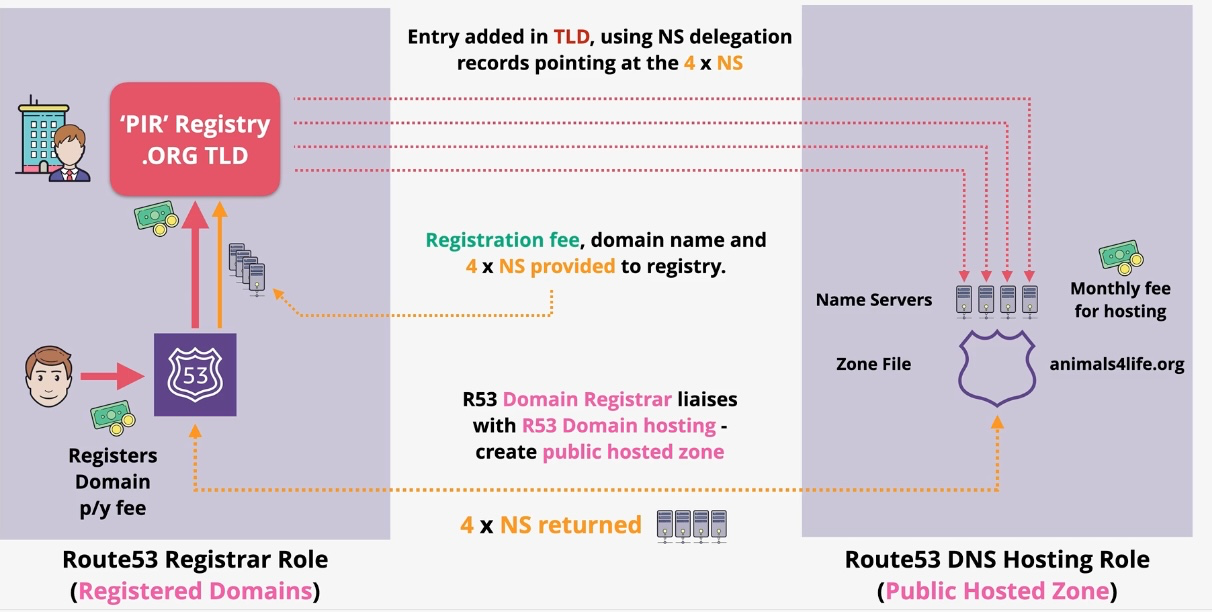
R53: Registrar Only
“Worst way to manage domains”
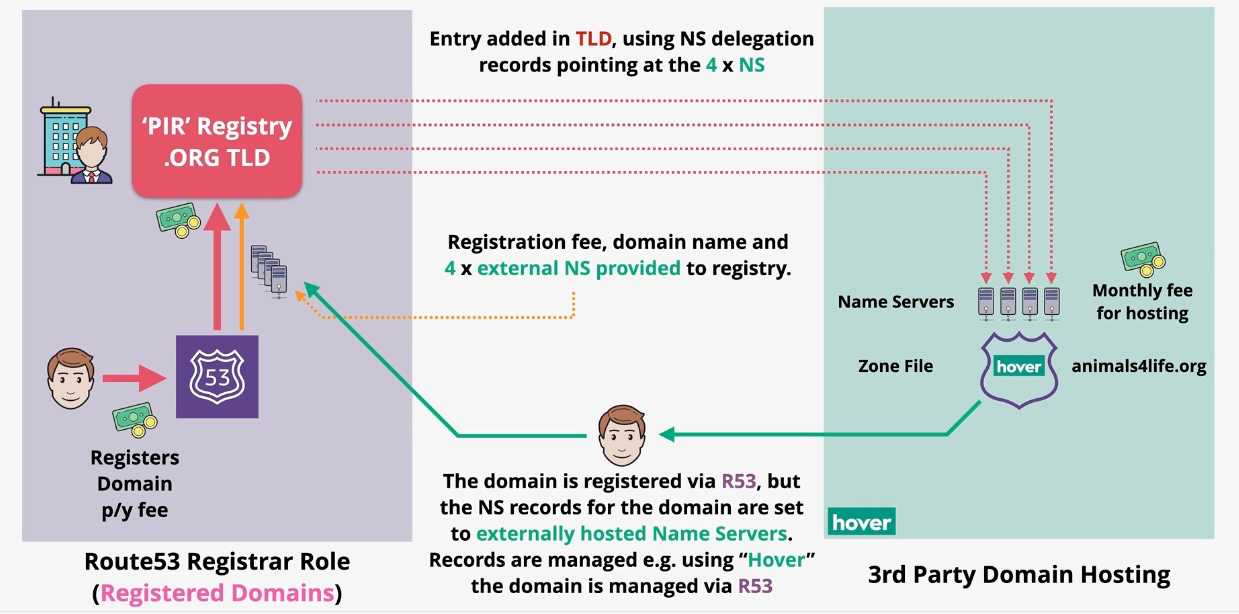
R53: Hosting Only
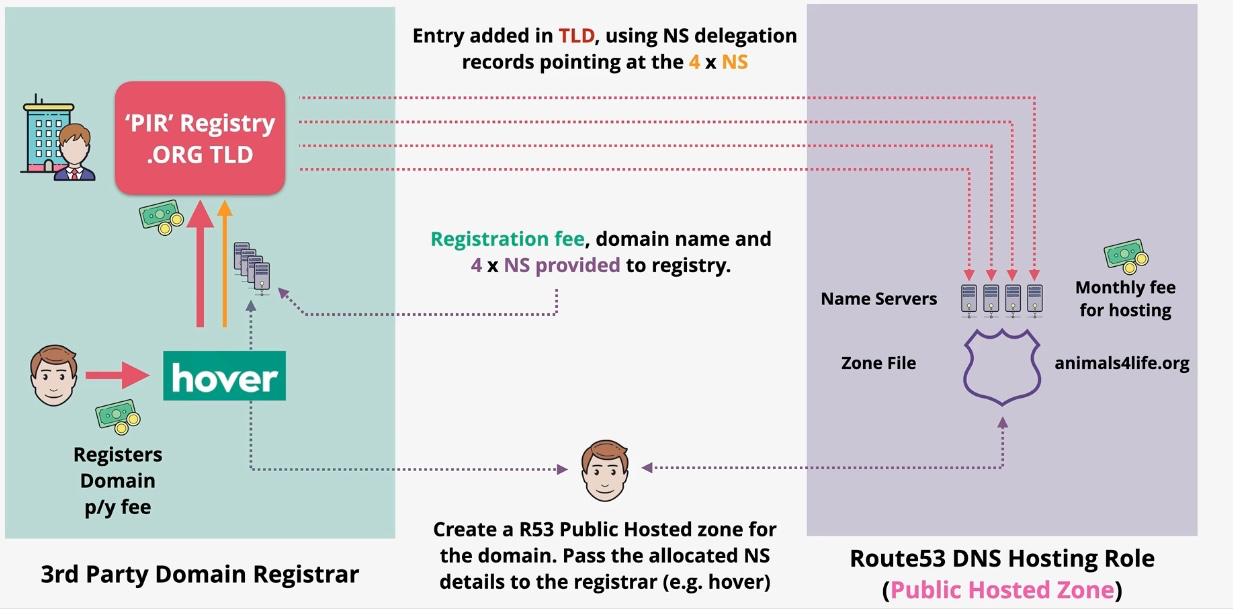
💽 Relational Database Service (RDS)
ACID vs BASE
💡 CAP Theorem: Consistency, Availability, Partition Tolerant - Choose two
**ACID:
- Atomic:** All or nothing - Consistent: From one valid state to another - Isolated: Transactions don’t interfere with each other - Durable: Stored on non-volatile memory. Resilient to crash.
**BASE:
-
Basicly Available:** Read and write available as much as possible without consistency guarantees - Soft State: Db doesn’t enforce consistency. Offload onto app/user - Eventually: Eventually consistent (wait long enough)
-
DynamoDB is BASE
Database on EC2
- Splitting DB and App into different AZs introduce dependencies between AZs
Reasons to host DB on EC2:
- Access to the DB instance OS
- Advanced DB Option tuning (DBROOT)
- Vendor demands
- DB or DB version AWS don’t provide
- Specific OS/DB Combination AWS don’t provide
- Architecture AWS don’t provide (replication/resilience)
- Decision makers who just want it
Reasons to NOT host DB on EC2:
- Admin overhead - managing EC2 and DBHost
- Backup / DR Management
- EC2 is single AZ
- Features - some of AWS DB products are amazing
- EC2 is ON or OFF - no serverless, no easy scaling
- Replication - skills, setup time, monitoring & effectiveness
- Performance - AWS invest time into optimization and features
Relational Database Service (RDS)
The Relational Database Service (RDS) is a Database(server) as a service product from AWS which allows the creation of managed databases instances.
- ❌ “Database as a Service” (DBaaS)
- Not completely true
- ✅ DatabaseServer-as-a-Service!
- Managed Database Instance (1+ Databases)
- Multiple engines MySQL, MariaDB, PostgresSQL, Oracle, Microsoft SQL Server
- Amazon Aurora
- Different from the other engines
RDS Architecture
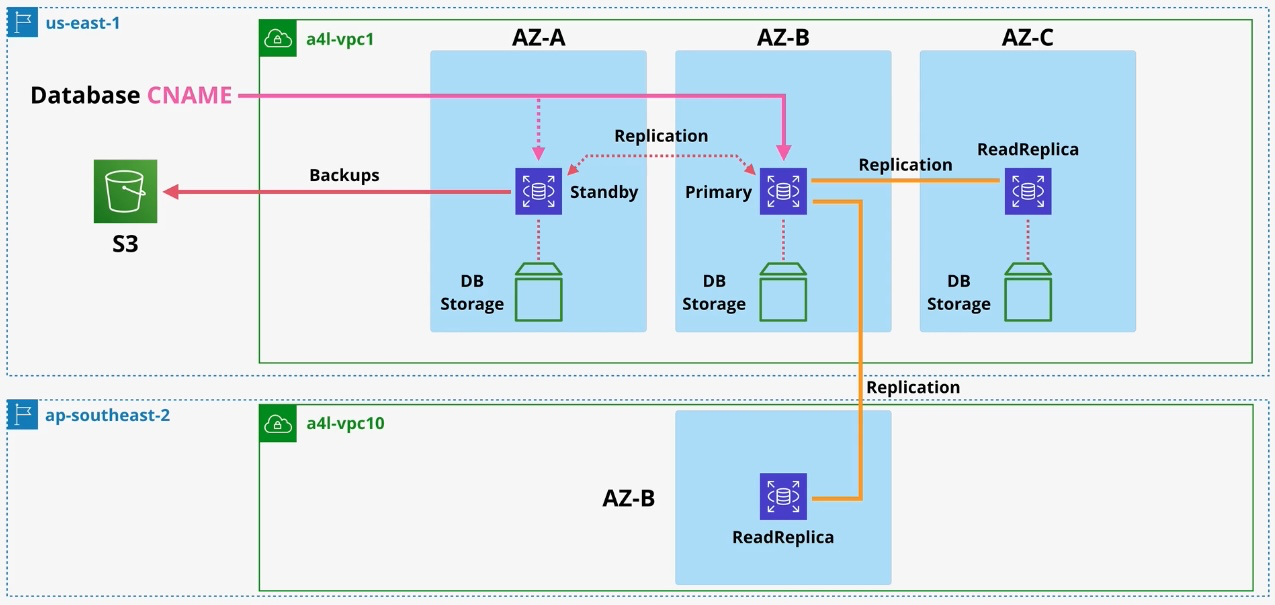
RDS Database Instance
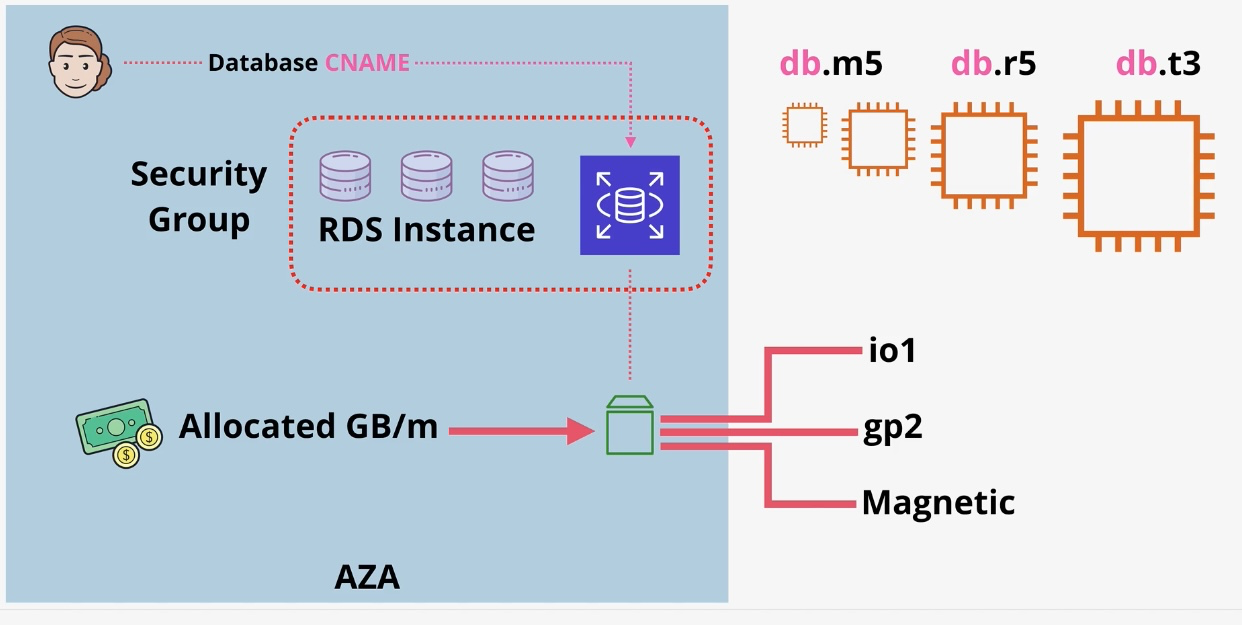
RDS Multi AZ
MultiAZ is a feature of RDS which provisions a standby replica which is kept in sync Synchronously with the primary instance.
The standby replica cannot be used for any performance scaling ... only availability.
Backups, software updates and restarts can take advantage of MultiAZ to reduce user disruption.
In case of failure of the primary DB, the CNAME points to the standby DB
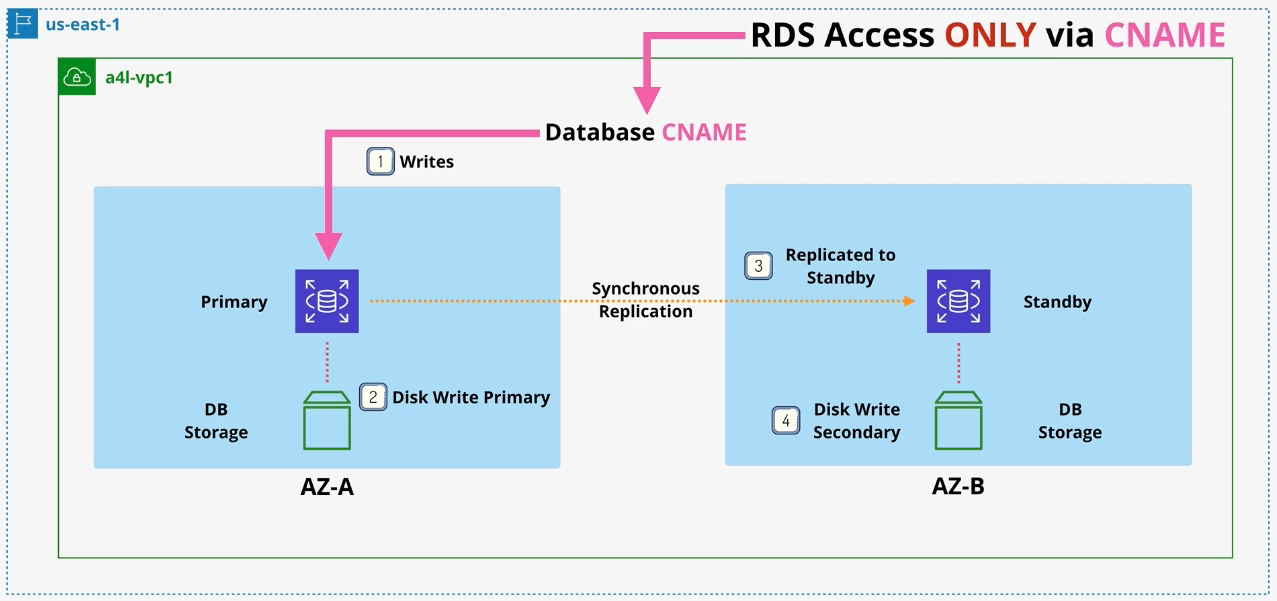
- No Free-tier! Extra cost for standby replica
- Standby can’t be directly used
- 60-120 seconds failover
- Same region only (other AZs in the VPC)
- Backups taken from Standby (removes performance impact)
- AZ Outage, Primary Failure, Manual failover, Instance type change and software patching
RBD Backups and Restores
RDS is capable of performing Manual Snapshots and Automatic backups
Manual snapshots are performed manually and live past the termination of an RDS instance
Automatic backups can be taken of an RDS instance with a 0 (Disabled) to 35 Day retention.
Automatic backups also use S3 for storing transaction logs every 5 minutes - allowing for point in time recovery.
Snapshots can be restored .. but create a new RDS instance
RTO vs RPO
RTO: Recovery Time Objective
- Time between DR event and full recovery
- Influenced by process, staff, tech and documentation
- Generally lower values cost more
RPO: Recovery Point Objective
- Time between last backup and the incident
- Amount of maximum data loss
- Influences technical solution and cost
- Generally lower values cost more
RDS Backups
Automatic Backups
- Delete after 0 to 35 days
- Restore to any point in time in this window
Manual Snapshots
- Don’t expire - manual deletion
AWS Managed S3 Bucket → Region Resilient
First snap is FULL → Next incremental (only diff is size)
RDS Backups are snapshots of the entire RDS - not only one database
Every 5 minutes Transaction Logs is written to S3
RDS Restores
- Creates a NEW RDS Instance - new address
- Snapshots = single point in time, creation time
- Automated = any 5 minute point in time
- Backup is restores and transaction logs are replayed to bring DB to desired point in time
- Restores aren’t fast - Think about RTO
RDS Read-Replicas
RDS Read Replicas can be added to an RDS Instance - 5 direct per primary instance.
They can be in the same region, or cross-region replicas.
They provide read performance scaling for the instance, but also offer low RTO recovery for any instance failure issues
N.B they don't help with data corruption as the corruption will be replicated to the RR.
Read-Replica Architecture
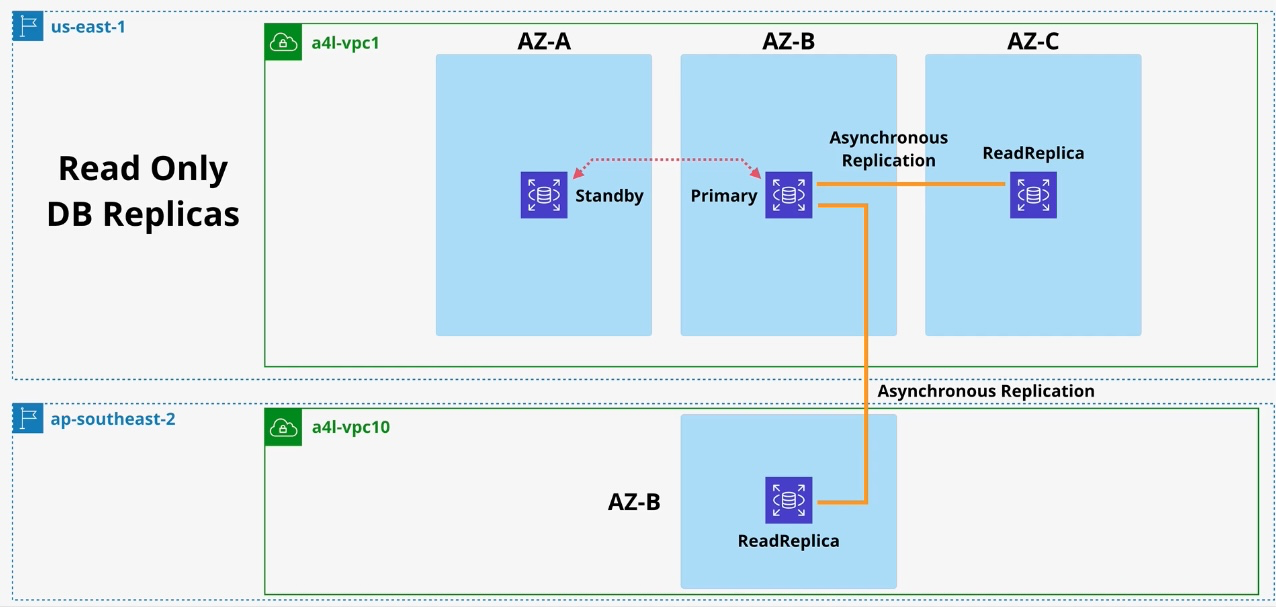
Writes to replica after primary write is complete. Can be accessed for read operation, unlike Standby Replica.
(read) Performance Improvements
- 5x direct read-replicas per DB instance
- Each providing an additional instance of read performance
- Read-replicas can have read-replicas - but lag starts to be a problem
- Global performance improvements
Availability Improvements
- Snapshots & Backups Improve RPO
- RTO’s are a problem
- RR’s offer nr. 0 RPO
- RR’s can be promoted quickly - low RTO
- Failure only - watch for data corruption
- Read only - until promoted
- Not reversible - delete and create new RR
- Global availability improvements → Global resilience
- Scale READS, NOT WRITES
Amazon RDS Security
- SSL/TLS (in transit) is available for RDS, can be mandatory
- RDS supports EBS volume encryption - KMS
- Handled by HOST/EBS
- AWS or Customer Managed CMK generates data keys
- Data keys used for encryption operations
- Storage, logs, snapshots and replicas are encrypted with the same master key
- encryption can’t be removed
- RDS MSSQL and RDS Oracle Support TDE
- TDE: Transparent Data Encryption
- Encryption handled within the DB engine
- RDS Oracle supports integration with CloudHSM
- Much stronger key controls (even from AWS)
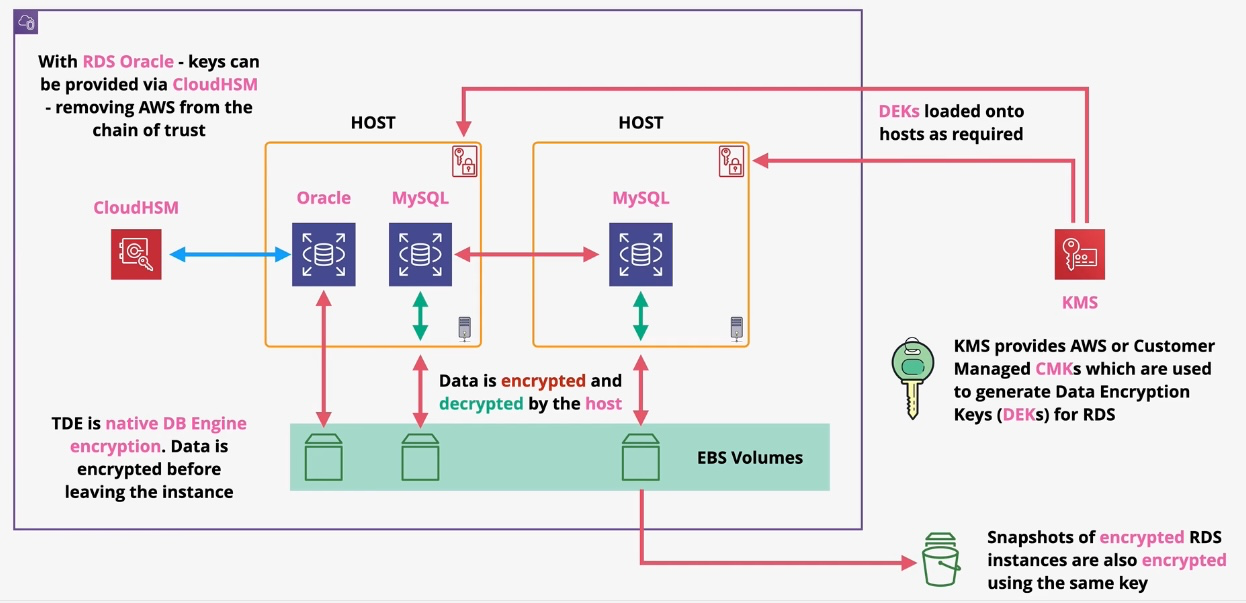
Amazon RDS IAM Authentication
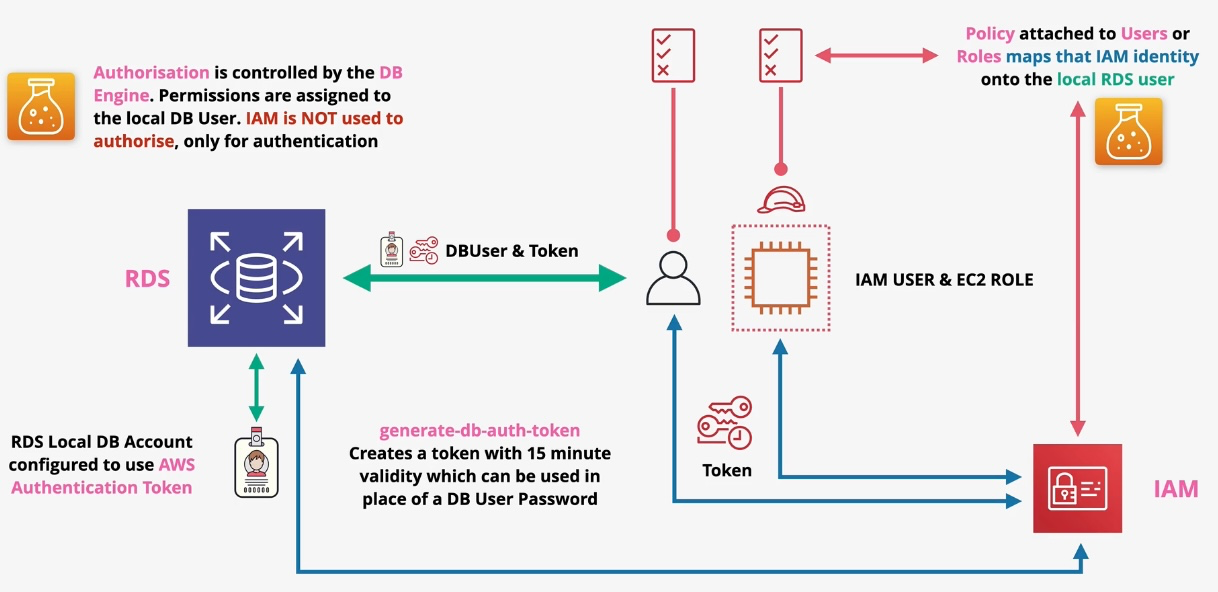
Amazon Aurora Architecture
Aurora is a AWS designed database engine officially part of RDS
Aurora implements a number of radical design changes which offer significant performance and feature improvements over other RDS database engines.
Aurora Key Differences
- Aurora architecture is VERY different from RDS
- Uses a Cluster
- A single primary instance + 0 or more replicas
- Replicas can read and be standby
- No local storage - uses cluster volume
- Faster provisioning and improved availability and performance
Aurora Storage Architecture
- Replication happens at storage level
- Primary is the only allowed to write to storage - other nodes can read
- In case of damage or error, data is immediately repaired
- More resilient than normal RDS
- Up to 15 different replicas to failover to
- Quicker failover
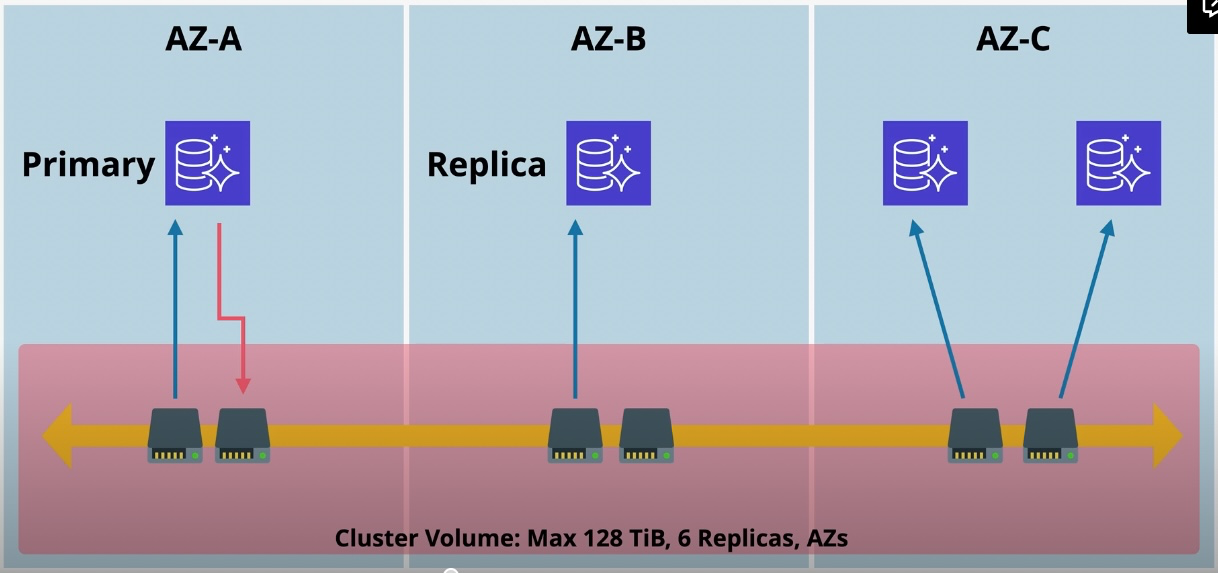
- All SSD Based - high IOPS, low latency
- Storage is billed based on what’s used
- High water mark - billed for the most used
- Being changed
- Storage which is freed up can be re-used
- Replicas can be added and removed without requiring storage provisioning
- Multiple endpoints
- Cluster endpoint
- Reader endpoint
- Load balance across replicas
- Custom endpoints
Cost
- No free-tier
- Aurora doesn’t support Micro Instances
- Beyond RDS singleAZ (micro) Aurora offers better value
- Compute - hourly charge, per second, 10 minute minimum
- Storage - GB-month consumed, IO cost per request
- 100% DB size in backups are included
Aurora Restore, Clone and Backtrack
- Backups in Aurora work in the same way as RDS
- Restores create a new cluster
- Backtrack can be used which allow in-place rewinds to a previous point in time
- Fast clones make a new database MUCH faster than copying all the data - copy-on-write
- Uses a tiny amount of storage - only stores the data changed since the clone was created
Aurora Serverless
Is to Aurora what Fargate is to EC2
Aurora Serverless Concepts
- Scalable - ACU : Aurora Capacity Units
- Aurora Serverless cluster has a MIN and MAX ACU
- Cluster adjusts based on load
- Can go to 0 and be paused
- Consumption billing per-second basis
- Same resilience as Aurora (6 copies across AZs)
Aurora Serverless Architecture
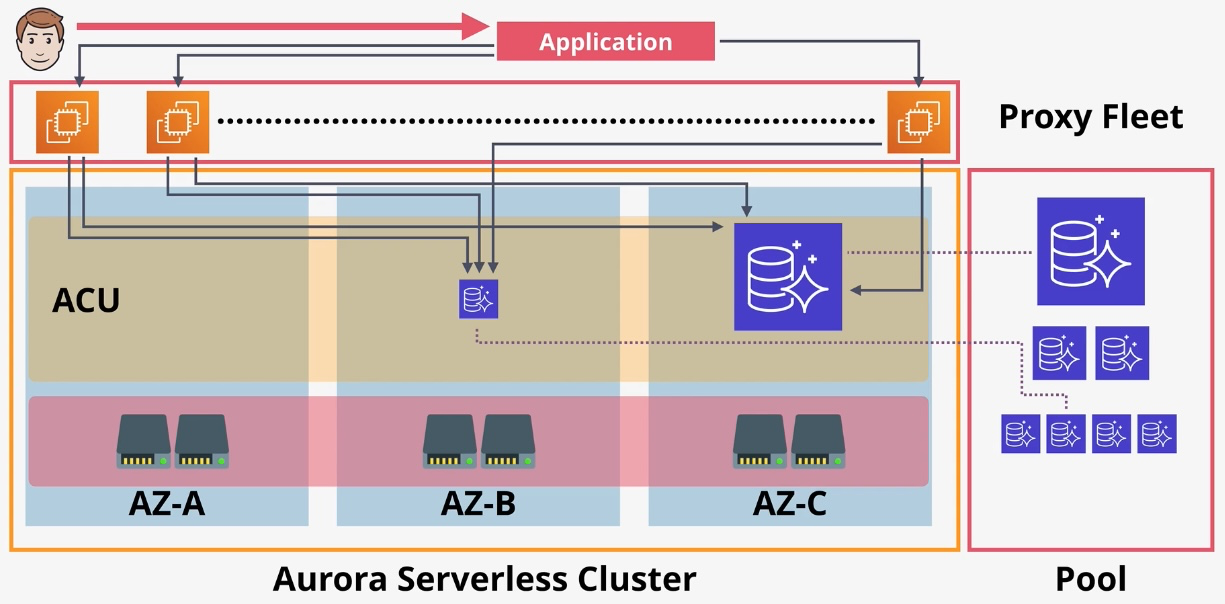
Aurora Serverless: Use Cases
- Infrequently used application
- New applications
- Variable workloads
- Unpredictable workloads
- Development and test databases
- Multi-tenant applications
Aurora Global Database
Aurora global databases are a feature of Aurora Provisioned clusters which allow data to be replicated globally providing significant RPO and RTO improvements for BC and DR planning. Additionally global databases can provide performance improvements for customers .. with data being located closer to them, in a read-only form.
Replication occurs at the storage layer and is generally ~1second between all AWS regions.
Aurora Global DB Architecture
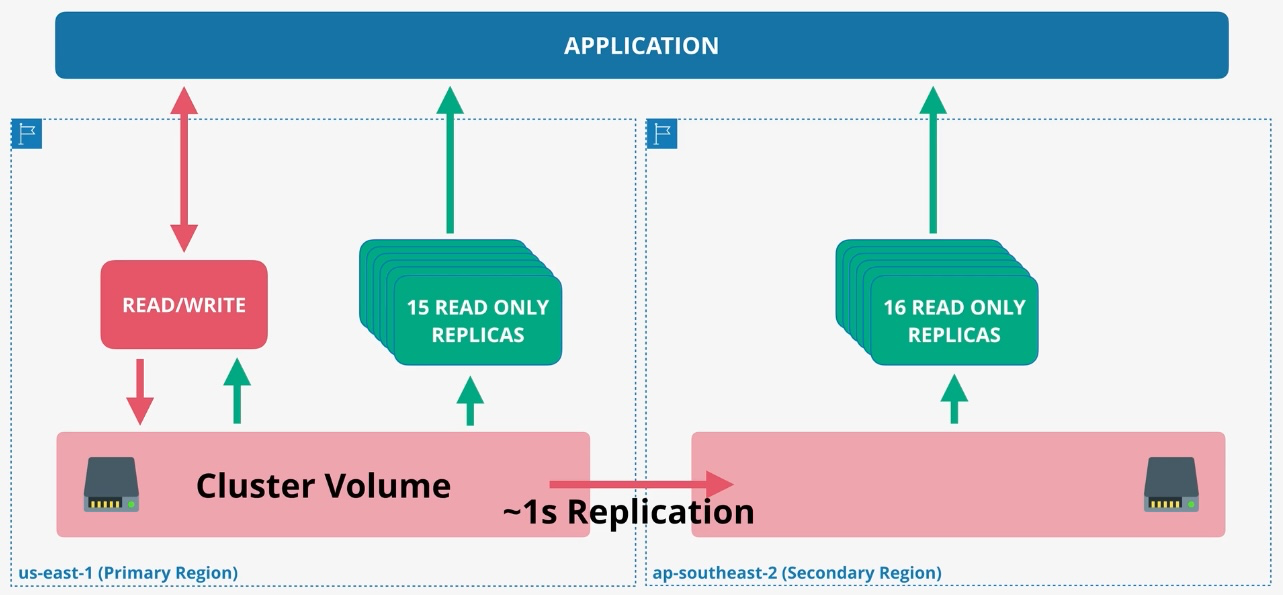
Key Concepts
- Cross-Region DR and BC (Business Continuity)
- RPO and RTO low
- Global Read Scaling - low latency performance improvements
- ~1s or less replication between regions
- No impact on DB performance
- Secondary regions can have 16 replicas
- Currently MAX 5 secondary regions
Aurora Multi-Master Writes
Multi-master write is a mode of Aurora Provisioned Clusters which allows multiple instances to perform reads and writes at the same time - rather than only one primary instance having write capability in a single-master cluster. This lesson steps through the architecture and explains how the conflict resolution works.
- Default Aurora mode is single-master
- One R/W and 0+ Read Only Replicas
- Cluster Endpoint is used to write, read endpoint is used for load balanced reads
- Failover takes time - replica promoted to R/W
- In Multi-Master mode all instances are R/W
- Almost fault-tolerant
- Faster and much better availability
- Immediately send writes to other instance in case of crash
Architecture
- Seems like single-master, but no load balanced endpoint
- App can initiate connection to one or both replicas
- Changes are committed to the other replica in addition to storage
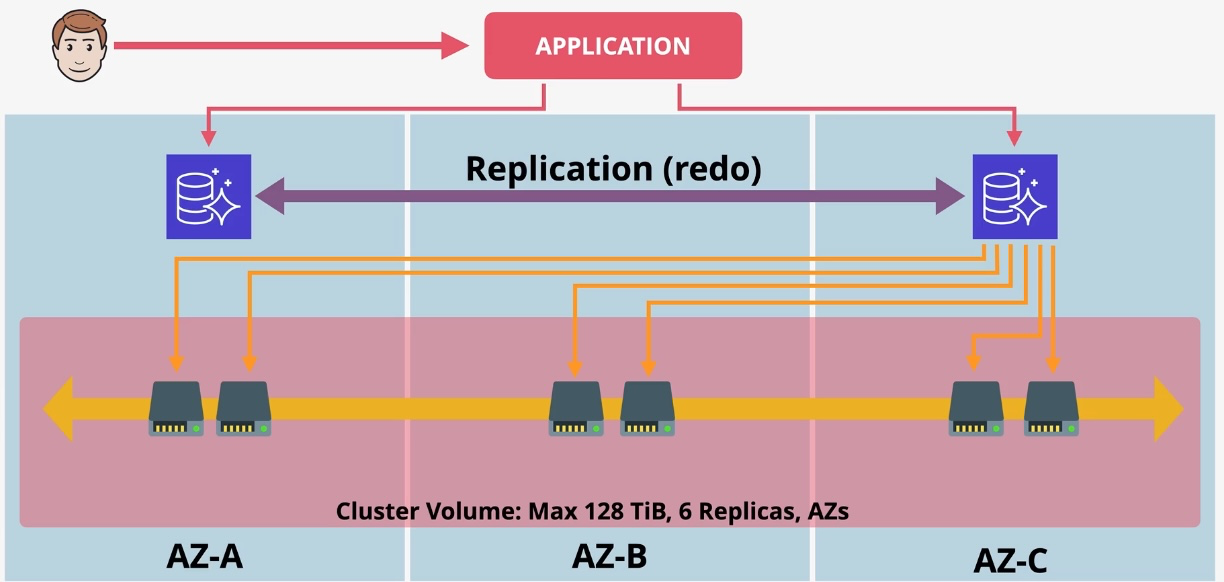
Database Migration Service (DMS)
The Database Migration Service (DMS) is a managed service which allows for 0 data loss, low or 0 downtime migrations between 2 database endpoints.
The service is capable of moving databases INTO or OUT of AWS.
- A managed database migration service
- Runs using a replication instance
- Source and destination endpoints point at source and target databases
- One endpoint MUST be on AWS!
- Safe default option in exam
Architecture
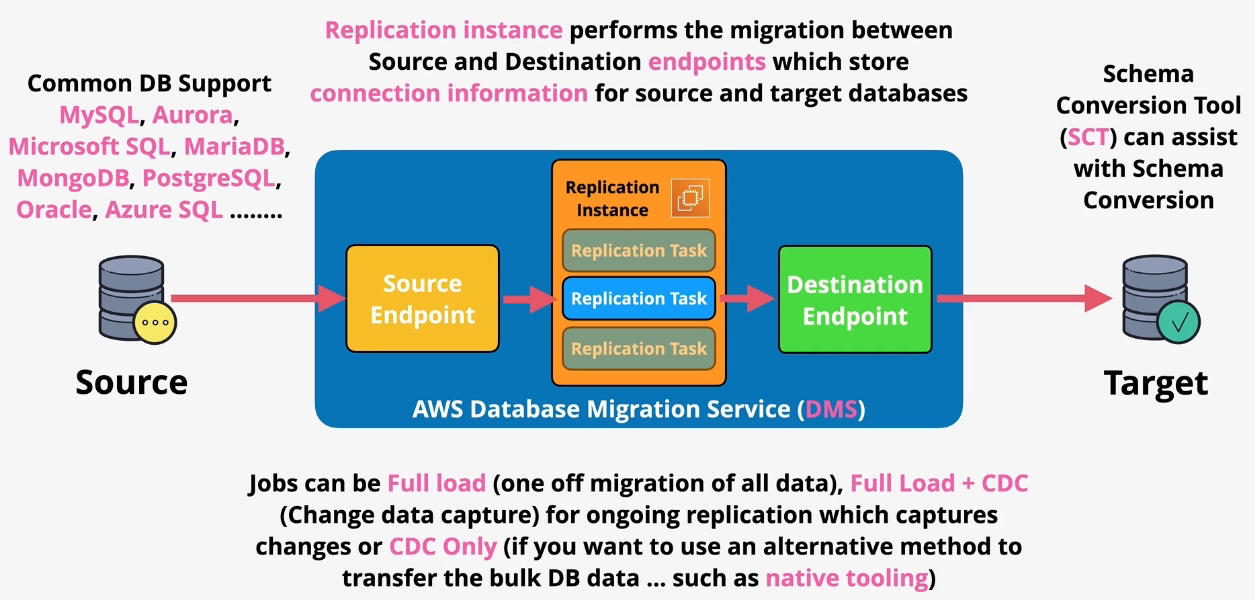
Schema Conversion Tool (SCT)
- SCT is used when converting one database engine to another
- Including DB → S3 (Migrations using SNS)
- SCT is not used when migrating between DB’s of the same type
- On-premises MySQL → RDS MySQL
- Works with OLTP DB Types (MySQL, MSSQL, Oracle)
- And OLAP (Teradata, Oracle, Vertica, Greenplum)
- E.g. On-premises MSSQL → RDS MySQL
- E.g. On-premises Oracle → Aurora
(DMS) & Snowball
- Larger migrations might be multi-TB in size
- moving data over networks takes time and consumes capacity
- DMS can utilize snowball
- Use SCT to extract data locally and move to a snowball device
- Ship the device back to AWS. They load onto an S3 bucket.
- DMS migrates from S3 into the target store
- Change Data Capture (CDC) can capture changes, and via S3 intermediary they are also written to the target database
🧬 Network Storage & Data Lifecycle
Elastic File System (EFS) Architecture
The Elastic File System (EFS) is an AWS managed implementation of NFS which allows for the creation of shared 'filesystems' which can be mounted within multi EC2 instances.
EFS can play an essential part in building scalable and resilient systems.
Elastic File System
- EFS is an implementation of NFSv4
- EFS Filesystems can be mounted in Linux
- Use POSIX permissions
- Shared between many EC2 instances
- Exist separate from EC2 instances
- Private service, via mount targets inside a VPC
- Can be accessed from on-premises - VPN or DX
- LINUX ONLY
- General Purpose and Max I/O performance modes
- General Purpose = default for 99,9% of uses
- Bursting and Provisioned Throughput Modes
- Standard and Infrequent Access (IA) Classes
- Like S3
- Lifecycle policies can be used with classes
AWS Backup
Use AWS Backup to centralize and automate data protection across AWS services and hybrid workloads. AWS Backup offers a cost-effective, fully managed, policy-based service that further simplifies data protection at scale. AWS Backup also helps you support your regulatory compliance or business policies for data protection. Together with AWS Organizations, you can use AWS Backup to centrally deploy data protection policies to configure, manage, and govern your backup activity across your company’s AWS accounts and resources.
- Fully managed data-protection (backup/restore) service
- Consolidate management into one place across accounts and across regions
- Supports a wide range of AWS products
- Backup Plans - frequency, window, lifecycle, vault, region copy
- Resources - What resources are backed up
- Vaults - Backup destination (container) - assign KMS key for encryption
- Vault Lock - write-once, read-many (WORM), 72 hour cool off, then even AWS can’t delete
- On-demand - manual backups created
- PITR - Point in time recovery
⚖️ High Availability (HA) & Scaling
Regional and Global AWS Architecture
- Global Service Location & Discovery
- Content Delivery (CDN) and optimization
- Global health checks and Failover
- Regional entry point
- Scaling & Resilience
- Application services and components
Tiers
- Web Tier
- Compute Tier
- Storage
- Caching
- DB Tier
- App Services
Evolution of Elastic Load Balancers (ELB)
The Elastic Load Balancer (ELB) was introduced in 2009 with the 'now called' Classic Load Balancer
Two new versions the v2 Application and v2 Network load balancers are now the recommended solutions.
- Three types of load balancers (ELB) available within AWS
- Split between v1 (avoid/migrate) and v2 (prefer)
- Classic Load Balancer (CLB) - v1 - Introduced in 2009
- Not really layer 7, lacking features, 1 SSL per CLB
- Application Load Balancer (ALB) - v2 - HTTP/S/WebSocket
- Network Load Balancer (NLB) - v2 - TCP, TLS, UDP
- V2 = faster, cheaper, support target groups and rules
Elastic Load Balancer Architecture (ELB)
Elastic Load Balancers are a core part of any scaling architecture within AWS. Accept and distribute connections.
ELB Architecture
- IPv4 only or dual-stack (include IPv6)
- Pick AZ load balancer will use
- Subnets in two or more AZs
- Pick only one subnet in each AZ
- Subnets in two or more AZs
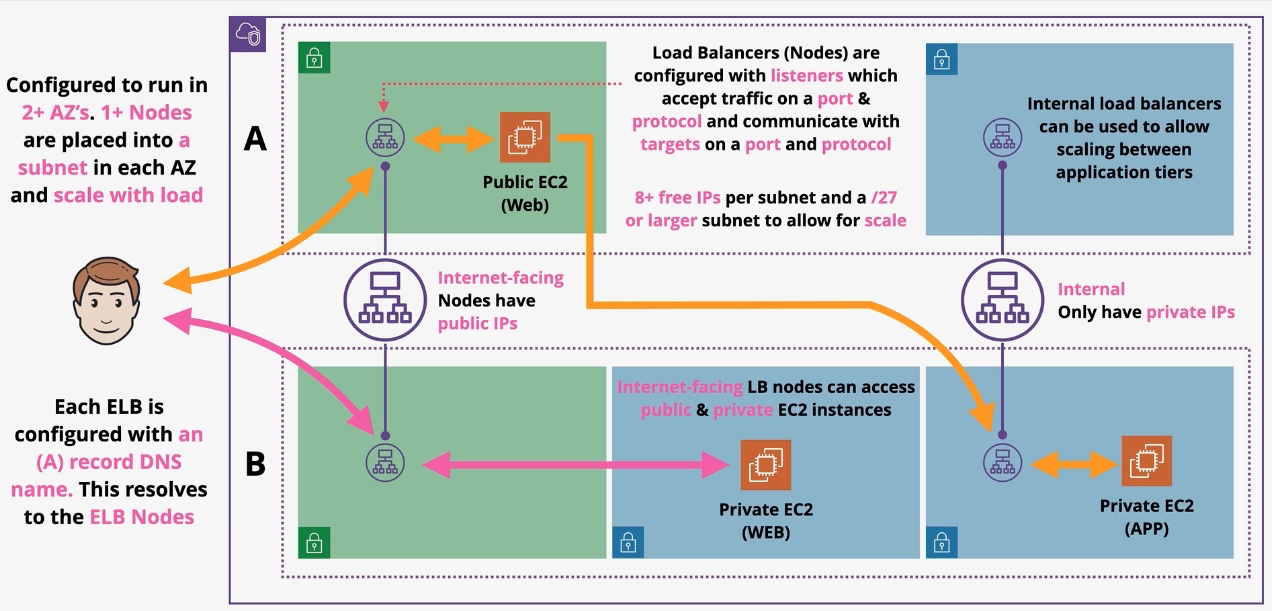
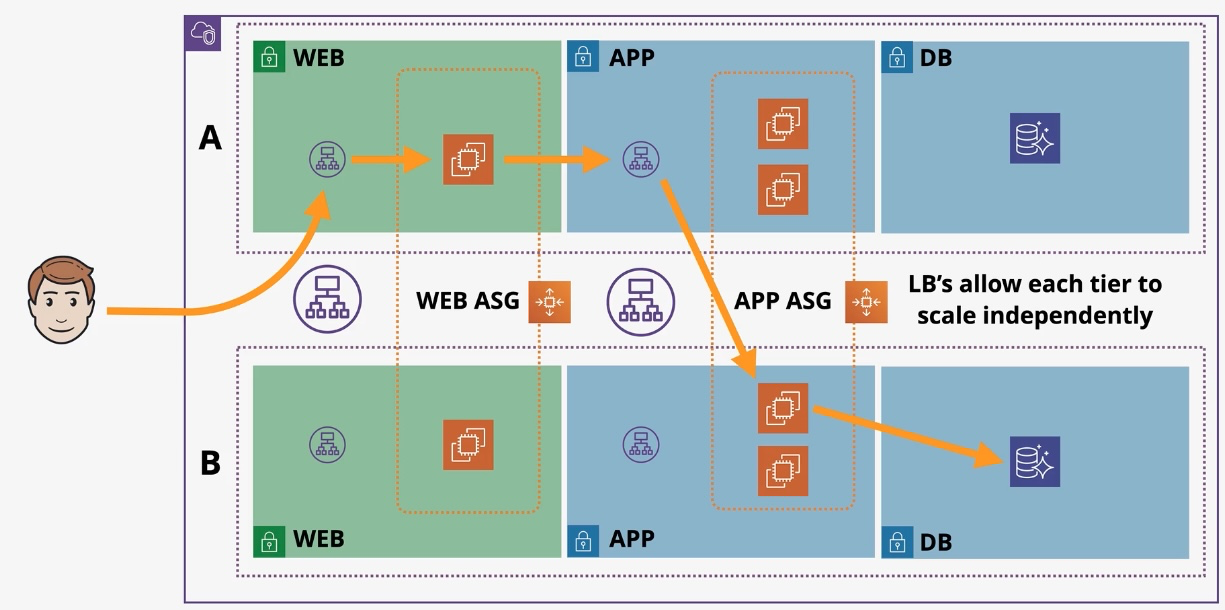
Cross-Zone LB
Equally distribute load to instances across AZs
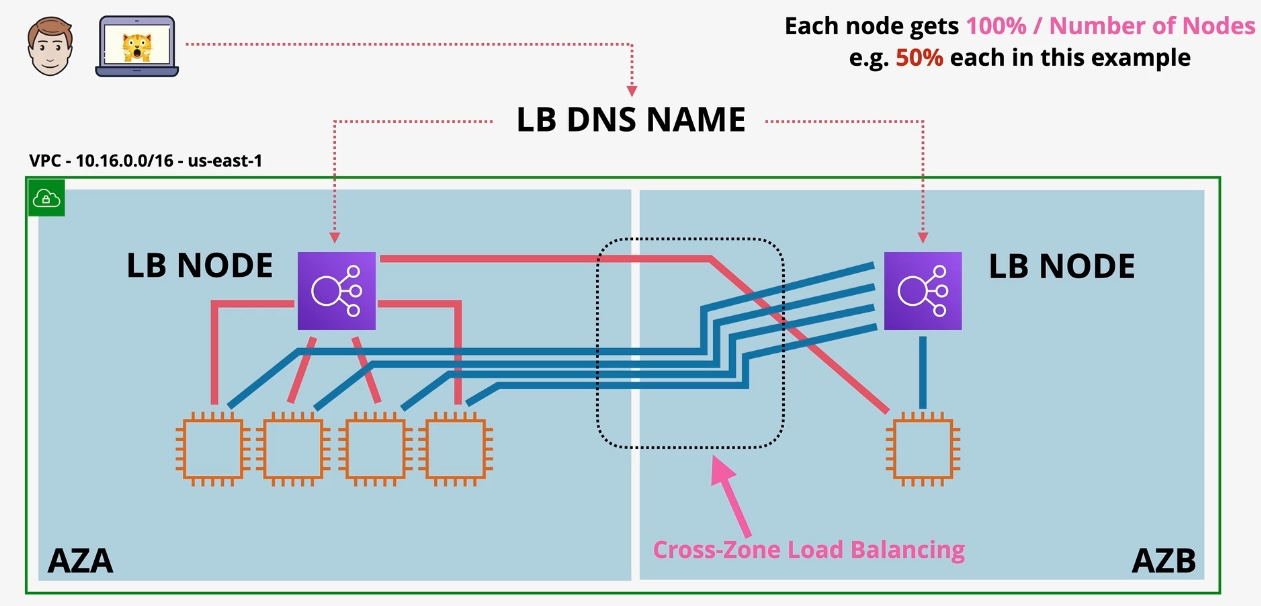
Key Points
- ELB is a DNS A Records pointing at 1+ Nodes per AZ
- Nodes (in one subnet per AZ) can scale
- Internet-facing means nodes have public IPv4 IPs
- Internal is private only IPs
- EC2 doesn’t need to be public to work with a LB
- Listener configuration controls WHAT the LB does
- 8+ free IPs per subnet, and /27 subnet to allow scaling
Application Load Balancing (ALB) vs Network Load Balancing (NLB)
Load Balancer Consolidation
CLBs bad
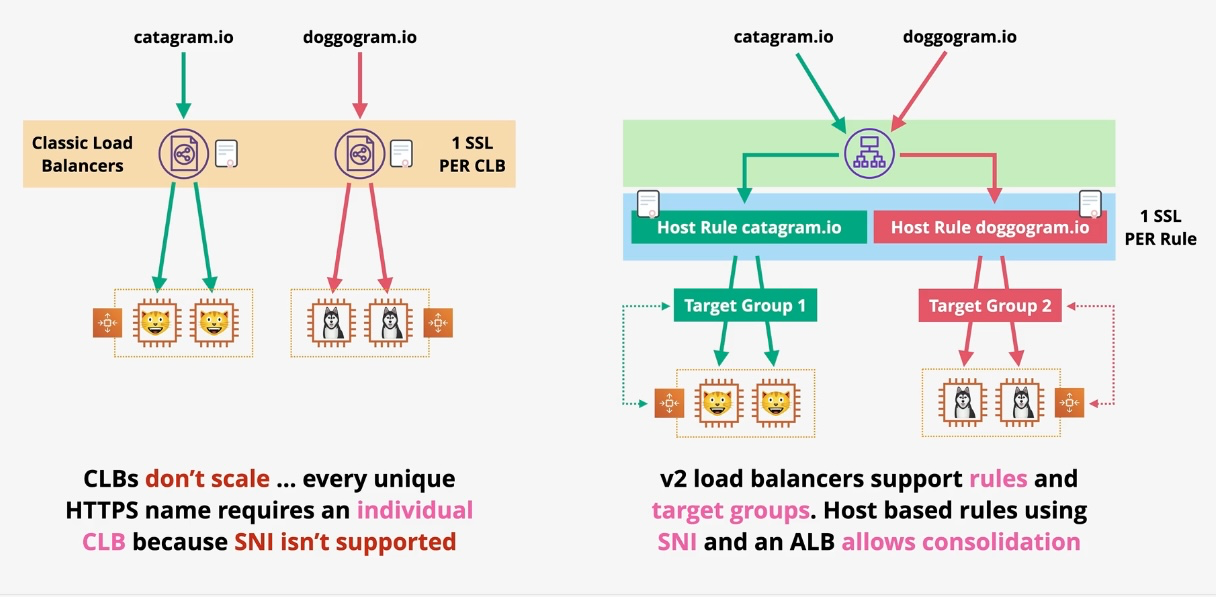
Application Load Balancer (ALB)
- Layer 7 load balancer
- Listens on HTTP/HTTPS
- **No other Layer 7 protocols (**SMTP, SSH, Gaming)
- And NO TCP/UDP/TLS Listeners
- L7 content type, cookies, custom headers, user location and app behaviour
- HTTP HTTPS (SSL/TLS) always terminated on the ALB - no unbroken SSL (security teams!)
- A new connection is made to the application
- ALBs MUST have SSL certs if HTTPS is used
- ALBs are slower than NLB. More levels of the networks stack to process
- Health checks evaluate application health
- Layer 7
ALB Rules
- Rules direct connections which arrive at a listener
- Processed in priority order
- Default rule = catchall
- Rule Conditions: host-header, http-header, http-request-method, path-pattern, query-string and source-ip
- Actions: forwards, redirects, fixed-response, authenticate-oids & authenticate-cognito
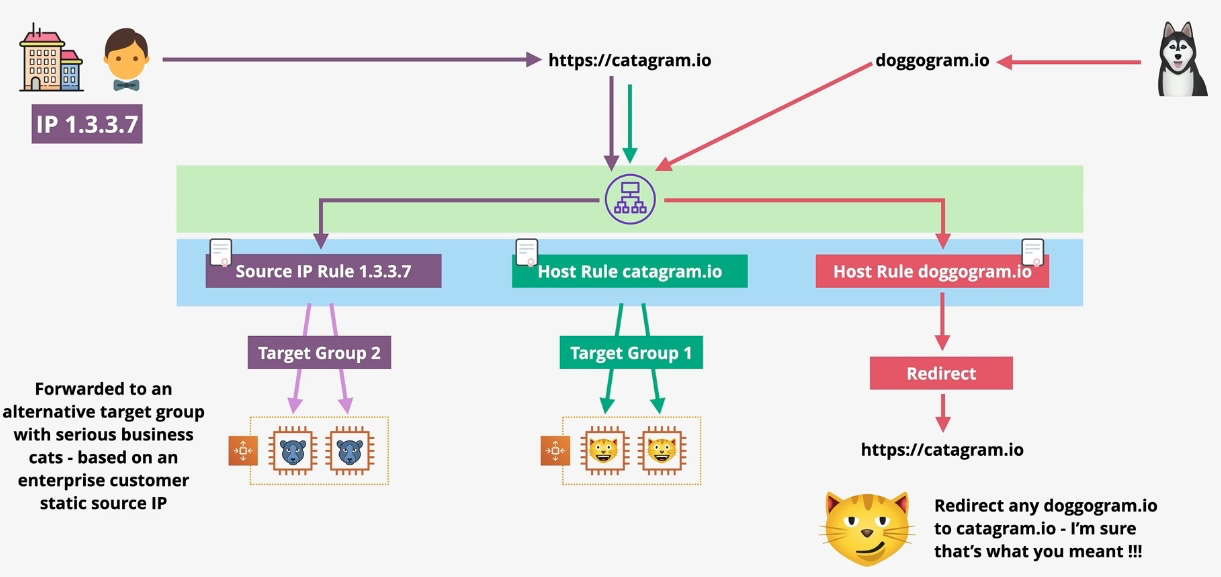
Network Load Balancer (NLB)
- Layer 4 load balancer
- TCP, TLS, UDP, TCP_UDP
- No visibility or understanding of HTTP/HTTPS
- No headers, no cookies, no sessions stickiness
- Really really really fast (millions of rps, 25% of ALB latency)
- SMTP, SSH, Game Servers, financial apps (not http/s)
- Health checks JUST check ICMP / TCP Handshake
- Not app aware
- NLBs can have static IPs useful for whitelisting
- Forward TCP to instances
- Unbroken encryption
- Used with private link to provide services to other VPCs
ALB vs NLB
- Default to ALB
- Unbroken encryption? NLB
- Static IP for whitelisting? NLB
- The fastest performance? NLB
- Protocols not HTTP or HTTPS? NLB
- Private link? NLB
- Otherwise? ALB!
Launch Configuration and Templates
Launch Configurations and Launch Templates provide the WHAT to Auto scaling groups.
They define WHAT gets provisioned
The AMI, the Instance Type, the networking & security, the key pair to use, the user data to inject and IAM Role to attach.
LC and LT Key Concepts
- Allow you to define the configuration of an EC2 instance in advance
- AMI, Instance Type, Storage & Key pair
- Networking and Security Groups
- User data & IA Role
- Both are NOT editable - defined once. LT has versions.
- Must create a new one
- LT provide newer features - including T2/T3 Unlimited, Placement Groups, Capacity Reservations, Elastic Graphics
LC and LT Architecture

Auto Scaling Groups
An Auto Scaling group contains a collection of Amazon EC2 instances that are treated as a logical grouping for the purposes of automatic scaling and management. An Auto Scaling group also enables you to use Amazon EC2 Auto Scaling features such as health check replacements and scaling policies. Both maintaining the number of instances in an Auto Scaling group and automatic scaling are the core functionality of the Amazon EC2 Auto Scaling service.
- Automatic Scaling and Self-Healing for EC2
- Uses Launch Templates or Launch Configurations
- Has a Minimum, Desired and Maximum Size ( e.g. 1:2:4)
- Keep running instances at the Desired capacity by provisioning or terminating instances
- Scaling Policies automate based on metrics
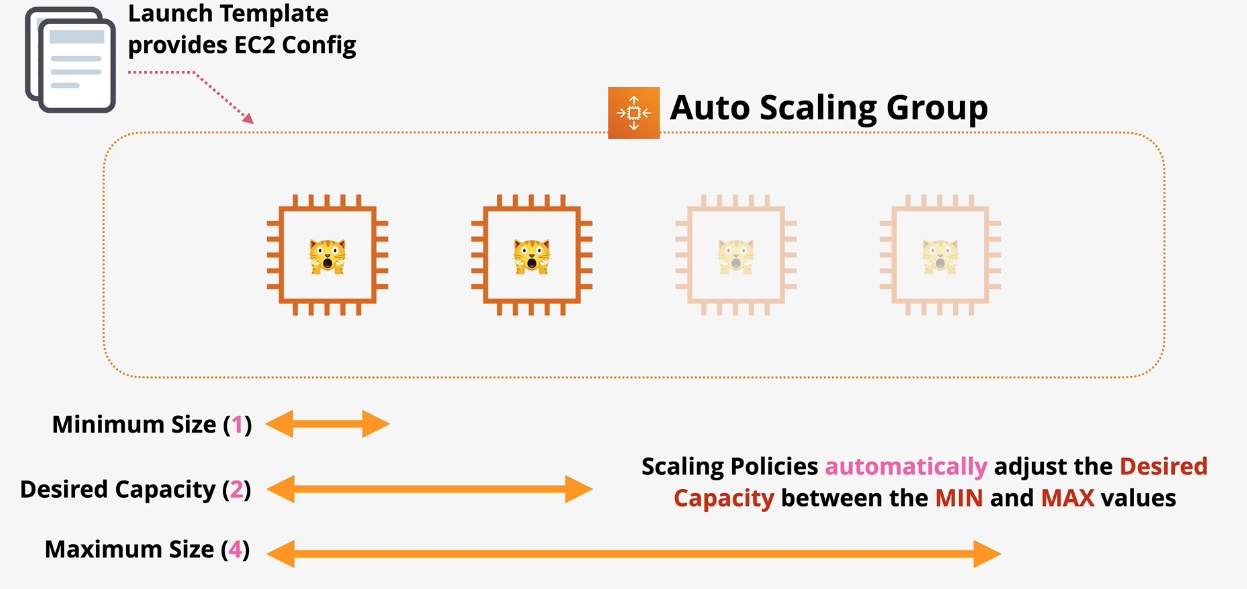
ASG Architecture
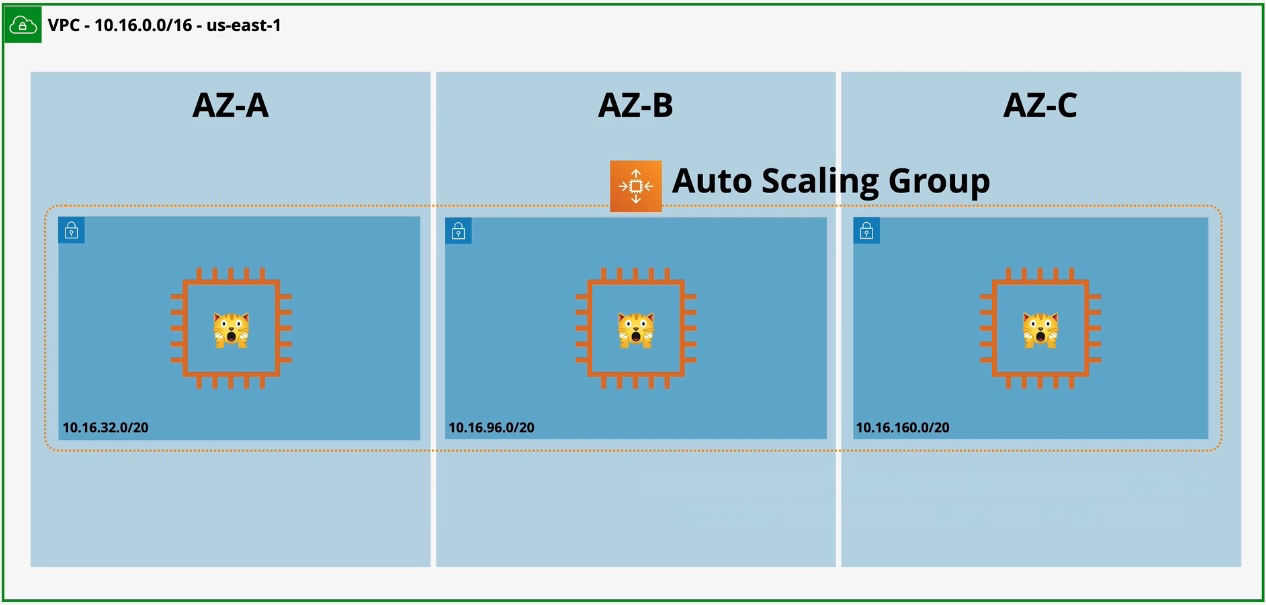
Scaling Policies
- Manual Scaling - Manually adjust the desired capacity
- Scheduled Scaling - Time based adjustment - e.g. Sales
- Dynamic Scaling
- Simple: “CPU above 50% +1”, “CPU Below 50 -1”
- Memory, Disk, I/O etc. metrics also available
- Stepped Scaling: Bigger +/- based on difference
- Target Tracking: Desired Aggregate CPU = 40% - ASG handle it
- Simple: “CPU above 50% +1”, “CPU Below 50 -1”
- Cooldown Periods: How long to wait before provisioning
ASG + Load Balancers
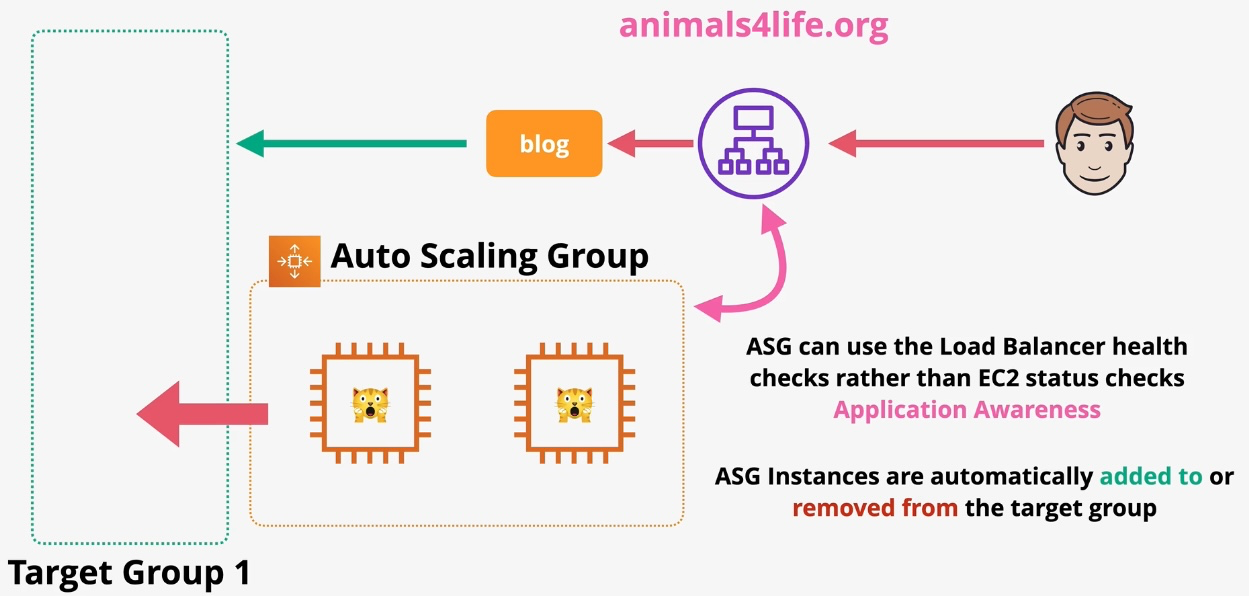
Scaling Processes
- Launch and Terminate: SUSPEND and RESUME
- AddToLoadBalancer: Add to LB on launch
- AlarmNotification: Accept notification from CW
- AZRebalance: Balances instances evenly across all of the AZs
- HealthCheck: Instance health checks on/off
- ReplaceUnhealthy: Terminate unhealthy and replace
- ScheduledActions: Scheduled on/off
- Standby: Use this for instances ‘InService vs Standby’
Final Points
- Autoscaling Groups are free
- Only the resources created are billed
- Use cool downs to avoid rapid scaling
- Think about more, smaller instances - granularity
- Use with ALB’s for elasticity - abstraction
- ASG defines WHEN and WHERE. LT defines WHAT
- Auto Scaling Default Termination Policy: ❗
- AZ with the most running instances
- Instance that was launched from the oldest launch template
- Instance closest to the next billing hour and terminates
ASG Scaling Policies
With step scaling and simple scaling, you choose scaling metrics and threshold values for the CloudWatch alarms that trigger the scaling process. You also define how your Auto Scaling group should be scaled when a threshold is in breach for a specified number of evaluation periods.
Step scaling policies and simple scaling policies are two of the dynamic scaling options available for you to use. Both require you to create CloudWatch alarms for the scaling policies. Both require you to specify the high and low thresholds for the alarms. Both require you to define whether to add or remove instances, and how many, or set the group to an exact size.
The main difference between the policy types is the step adjustments that you get with step scaling policies. When step adjustments are applied, and they increase or decrease the current capacity of your Auto Scaling group, the adjustments vary based on the size of the alarm breach.
- ASGs don’t NEED scaling policies - they can have none
- Manual: Min, max & desired - Testing & Urgent
- Simple Scaling
- Add 1 if CPU is above X %
- Not that efficient
- Step scaling
- Upper and lower bounds of CPU level
- 50 < CPU < 60 - do nothing
- 60 < CPU < 70 - add 1
- Always better than simple - adjust better
- AWS recommends
- Target tracking
- Define ideal value, e.g. 50% CPU usage
- Add/remove to stay at ideal value
- Scaling based on SQS - ApprocimateNumberOfMessagesVisible
ASG - Simple Scaling
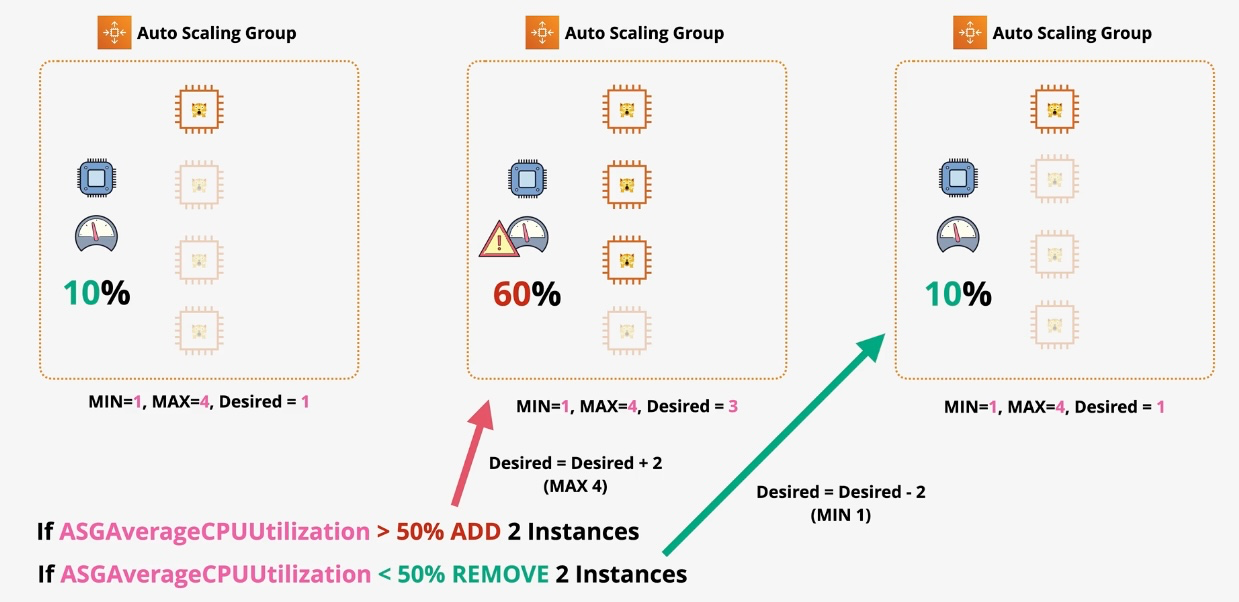
ASG - Step Scaling
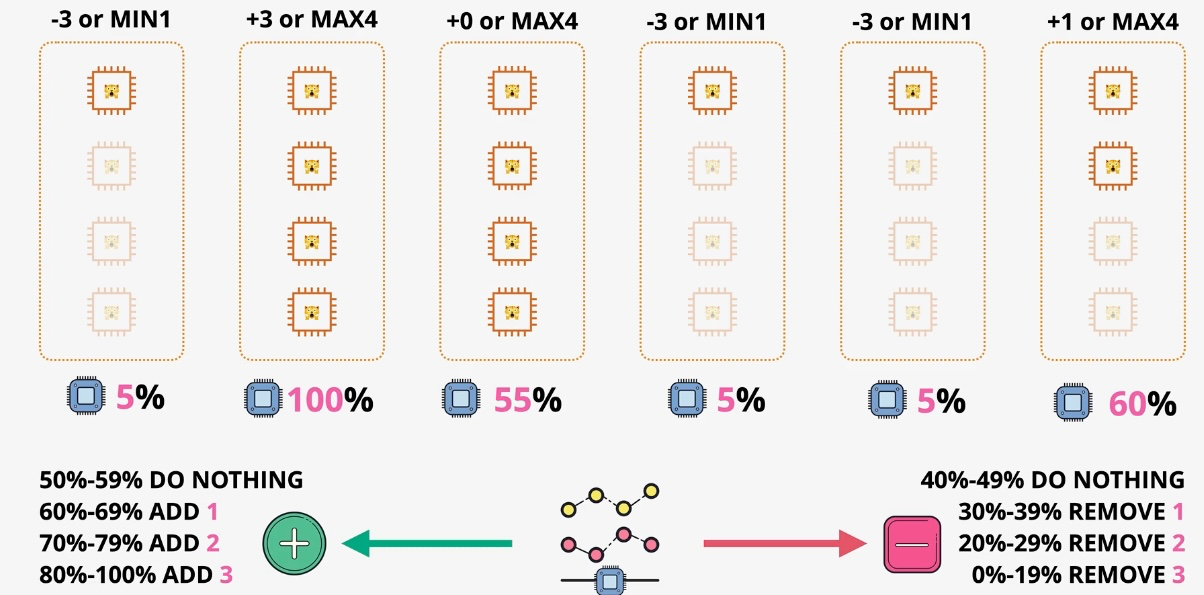
ASG Lifecycle Hooks
Lifecycle hooks enable you to perform custom actions by pausing instances as an Auto Scaling group launches or terminates them. When an instance is paused, it remains in a wait state either until you complete the lifecycle action using the complete-lifecycle-action command or the
CompleteLifecycleActionoperation, or until the timeout period ends (one hour by default).
- Custom Actions on instances during ASG actions
- Instance launch or instance terminate transitions
- Instances are paused within the flow - they wait
- until a time (then either CONTINUE or ABANDON)
- or you resume the ASG process CompleteLifeCycleAction
- EventBridge or SNS Notifications
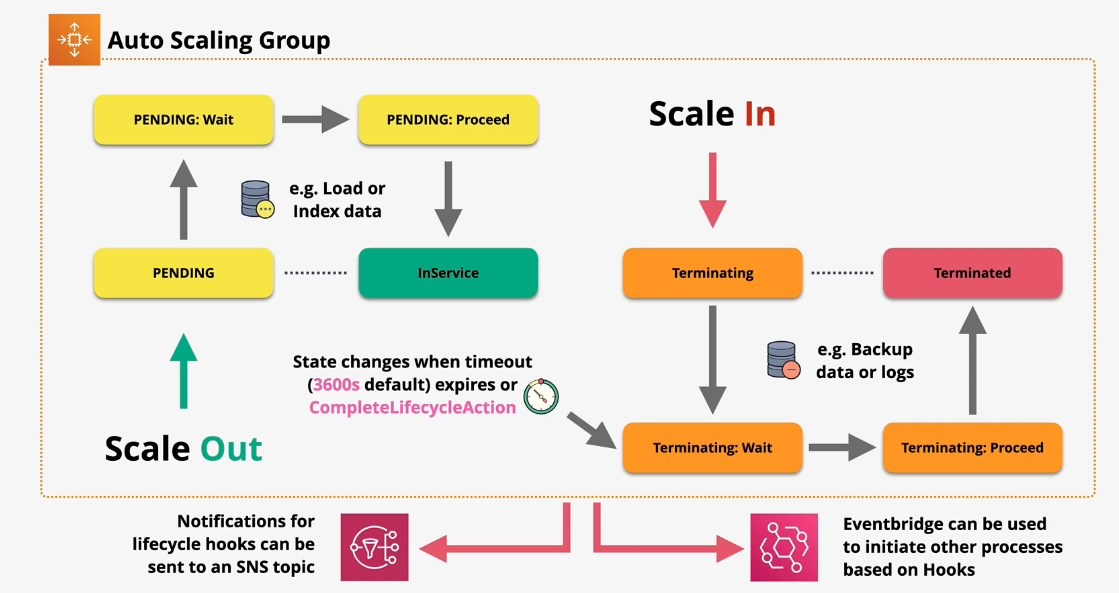
ASG Health Check Comparison - EC2 vs ELB
Amazon EC2 Auto Scaling can determine the health status of an instance using one or more of the following:
- Status checks provided by Amazon EC2 to identify hardware and software issues that may impair an instance. The default health checks for an Auto Scaling group are EC2 status checks only.
- Health checks provided by Elastic Load Balancing (ELB). These health checks are disabled by default but can be enabled.
- Your custom health checks.
- Three types of Health Checks:
- EC2 (Default)
- ELB (can be enabled)
- Custom
- EC2 - Stopping, Stopped, Terminated, Shutting Down or Impaired (not 2/2/ status) = UNHEALTHY
- ELB - HEALTHY = Running & passing ELB health check
- can be more application aware (layer 7)
- Custom - Instances marked healthy & unhealthy by external system
- Health check grace period (Default 300s) - Delay before starting checks
- allows system launch, bootstrapping and application start
SSL Offload & Session Stickiness
SSL Bridging, SSL Pass Through, SSL Offloading
SSL Offload
- Bridging
- Pass-through
- Offload
- HTTP from ELB to EC2 instances
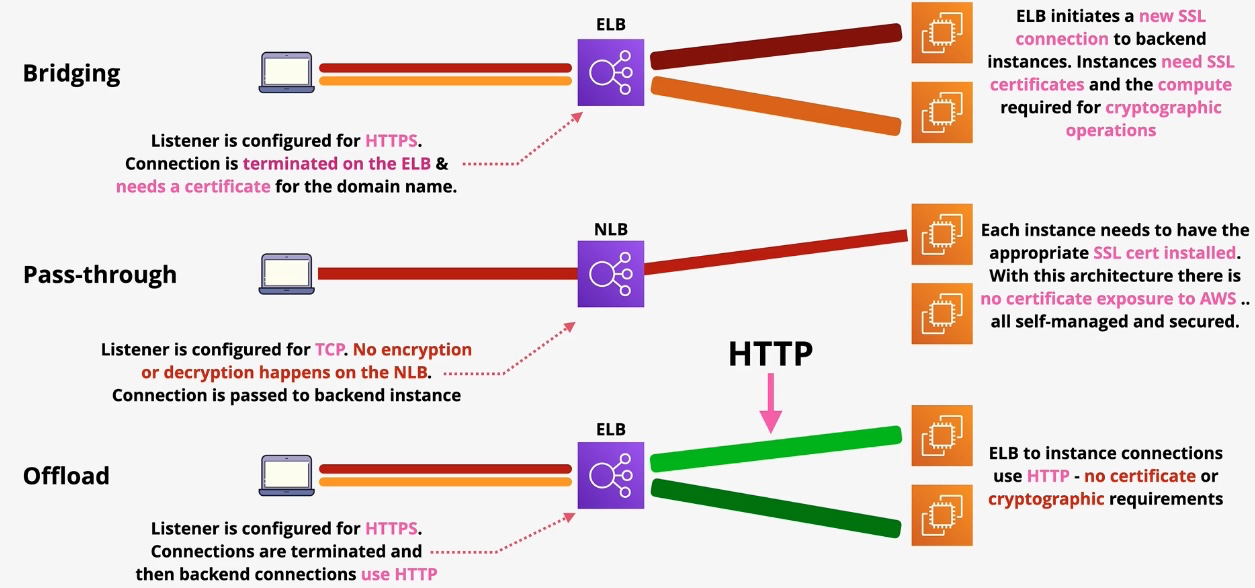
Connection Stickiness
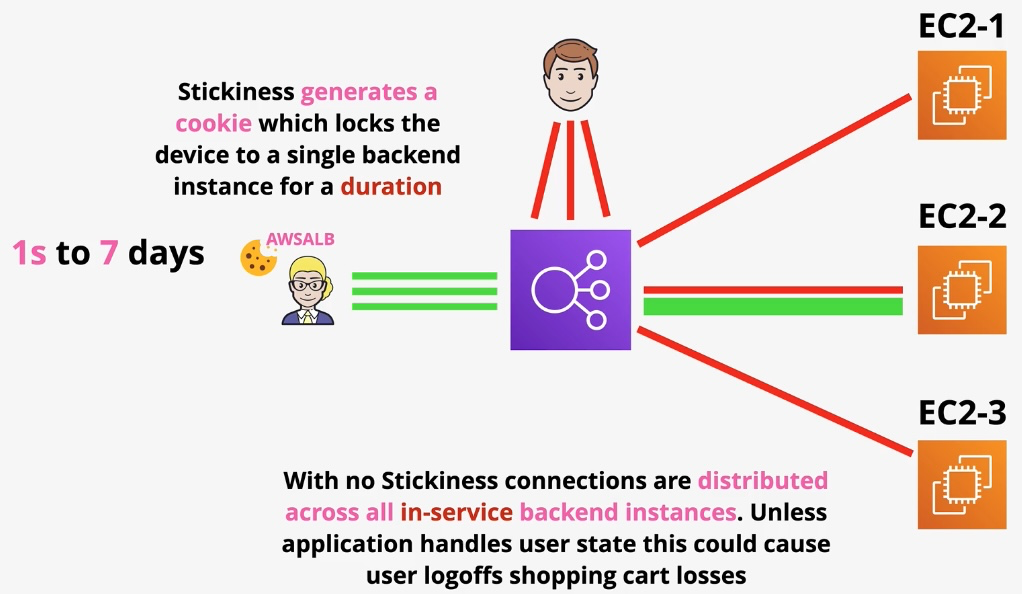
Gateway Load Balancers (GWLB)
Gateway Load Balancers enable you to deploy, scale, and manage virtual appliances, such as firewalls, intrusion detection and prevention systems, and deep packet inspection systems. It combines a transparent network gateway (that is, a single entry and exit point for all traffic) and distributes traffic while scaling your virtual appliances with the demand.
Why do we need GWLB?
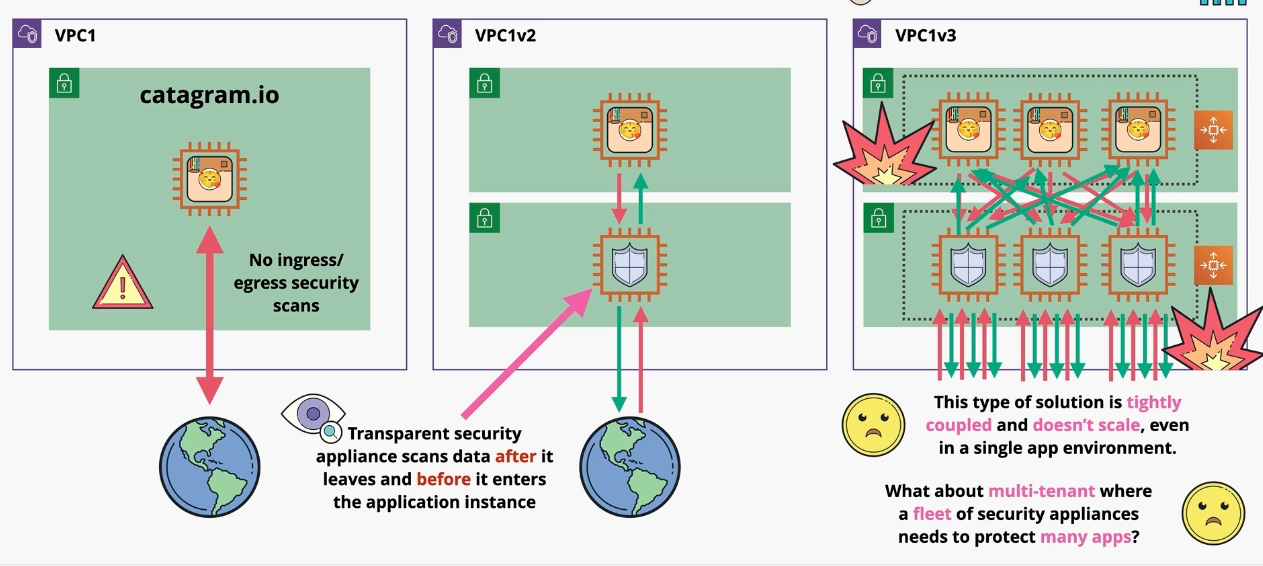
What is GWLB
- Help you run and scale 3rd party appliances
- things like firewalls, intrusion detection and prevention systems
- Inbound and Outbound traffic (transparent inspection and protection)
- GWLB endpoints: Traffic enters/leaves via these endpoints
- GWLB balances across multiple backend appliances
- Traffic and metadata is tunnelled using GENEVE
How it works
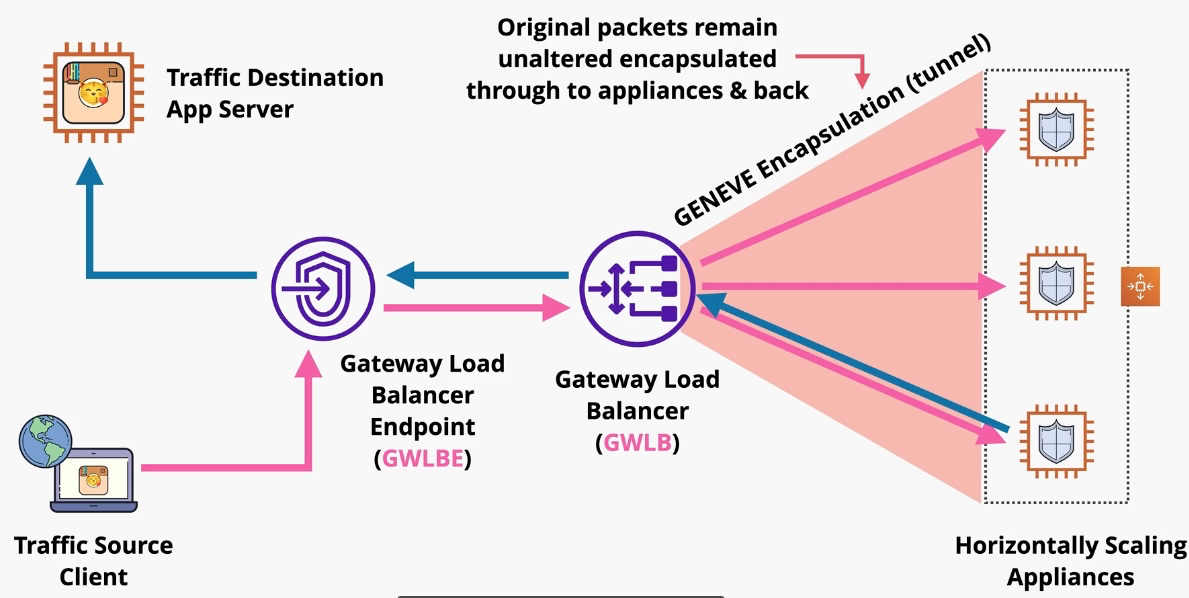
GWLB Architecture
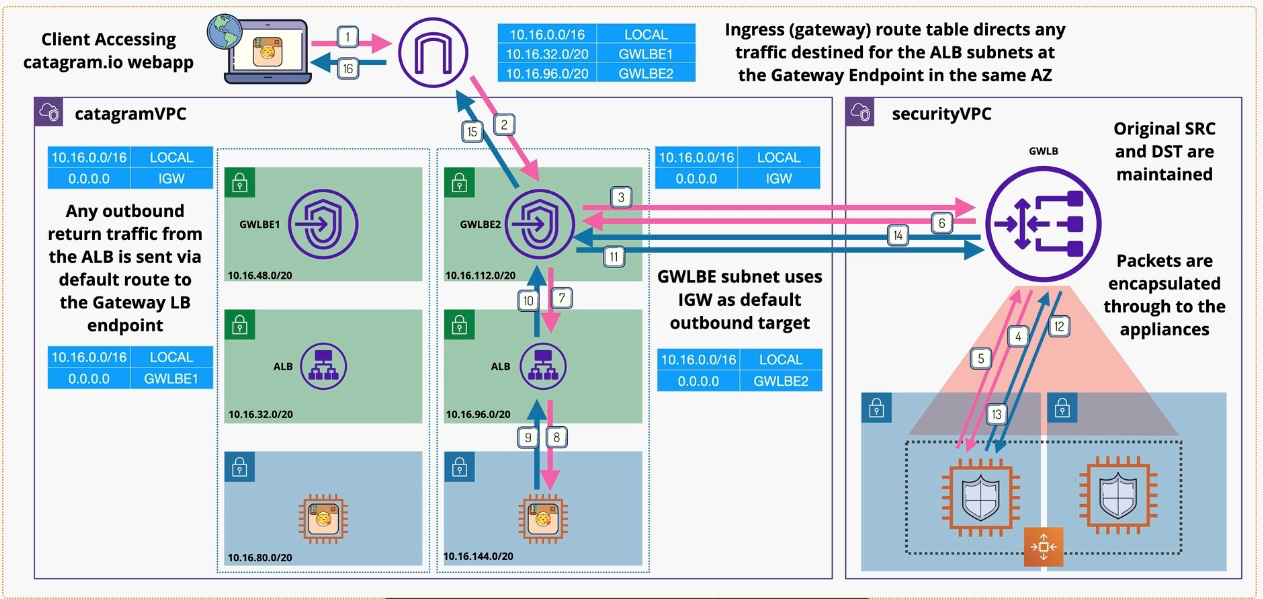
🌈 Serverless and Application Services
Architecture Deep Dive
Monolith
- All in one instance
- Bad
- Prone to error
Tiered Architecture
- Can be running on different HW, but still tightly coupled
- Can vertically scale individually
- Can have internal LB between them so we can scale each tier horizontally
- Bad because tiers are still coupled
- Each tier has to be running something for app to function
Evolving with Queues
System that accepts messages
- Queue-based decoupled architecture
- Queues decouple two tiers
- Async communication
- ASG based on Queue Length
- E.g. numbers of videos to process
Microservice Architecture
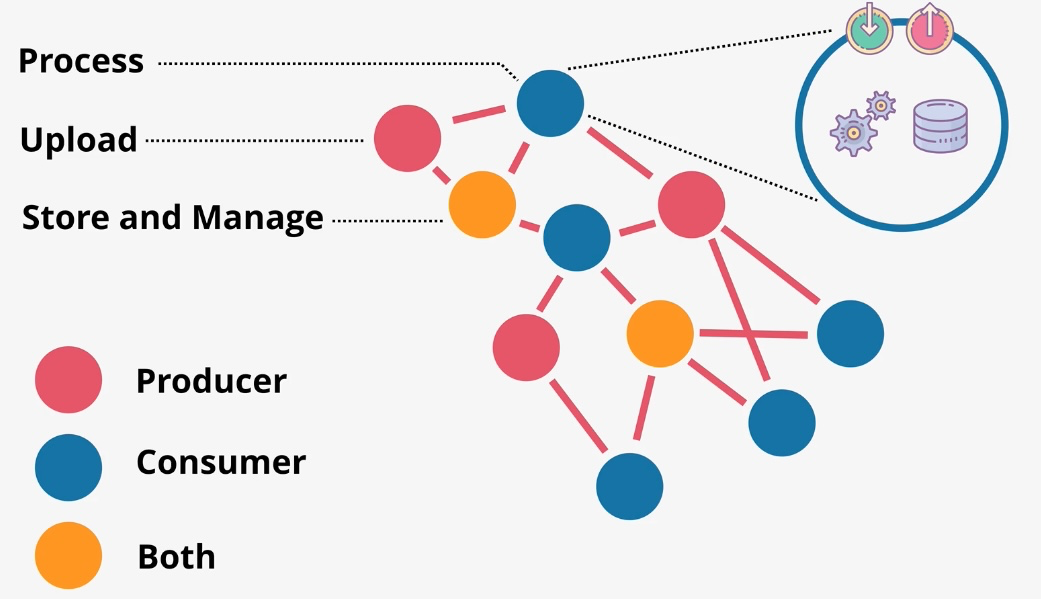
Event Driven Architecture
- No constant running or waiting for things
- Producers generate events when something happens
- clicks, error, criteria met, uploads, actions
- Events are delivered to consumers with event router
- actions are taken and the system returns to waiting
- Mature event-driven architecture only consumes resources while handling events (serverless)
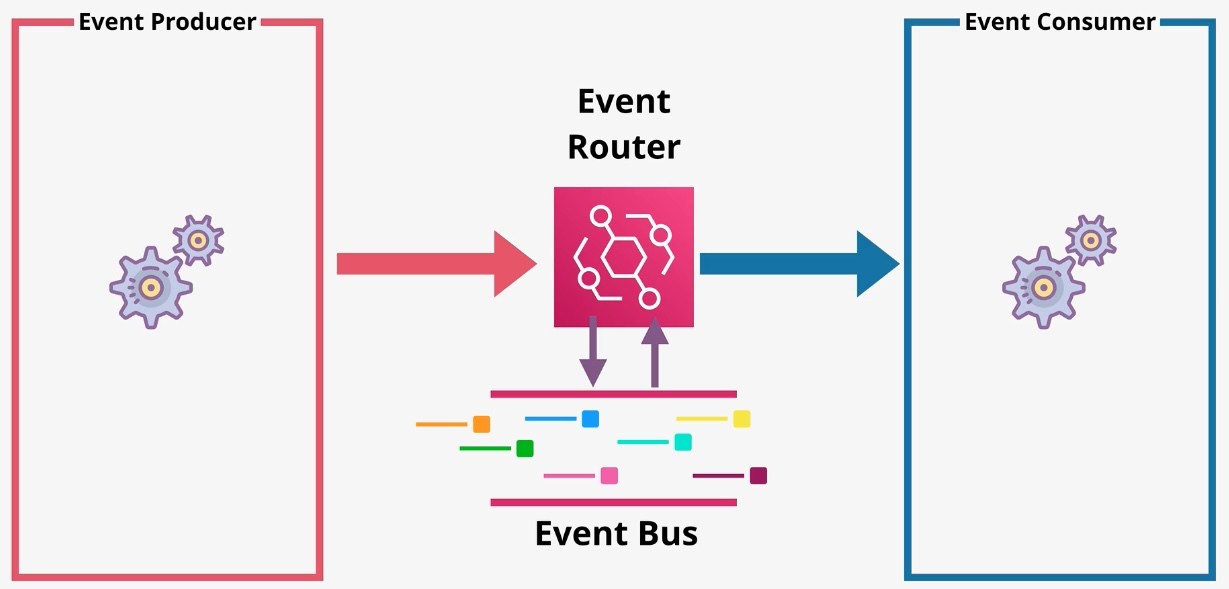
AWS Lambda
- Function-as-a-Service (FaaS) - short running & focused
- Lambda function - a piece of code lambda runs
- Functions use a runtime (e.g. Python 3.8)
- Functions are loaded and run in a runtime environment
- The environment has a direct memory (indirect CPU) allocation
- You are billed for the duration that a function runs
- A key part of serverless architectures
- Stateless - brand new env each time
- 900s (15 min) function timeout
Exam tip: Docker - not lambda
Common Uses
Common architectures
- Serverless applications (S3, API Gateway, Lambda)
- File processing (S3, S3 Events, Lambda)
- Database Triggers (DynamoDB, Streams, Lambda)
- Serverless CRON (EventBridge/CWEvents + Lambda)
- Realtime Stream data Processing (Kinesis + Lambda)
Public Lambda Architecture
- By default lambda function are given public networking. They can access public AWS services and the public internet
Private Lambda Architecture
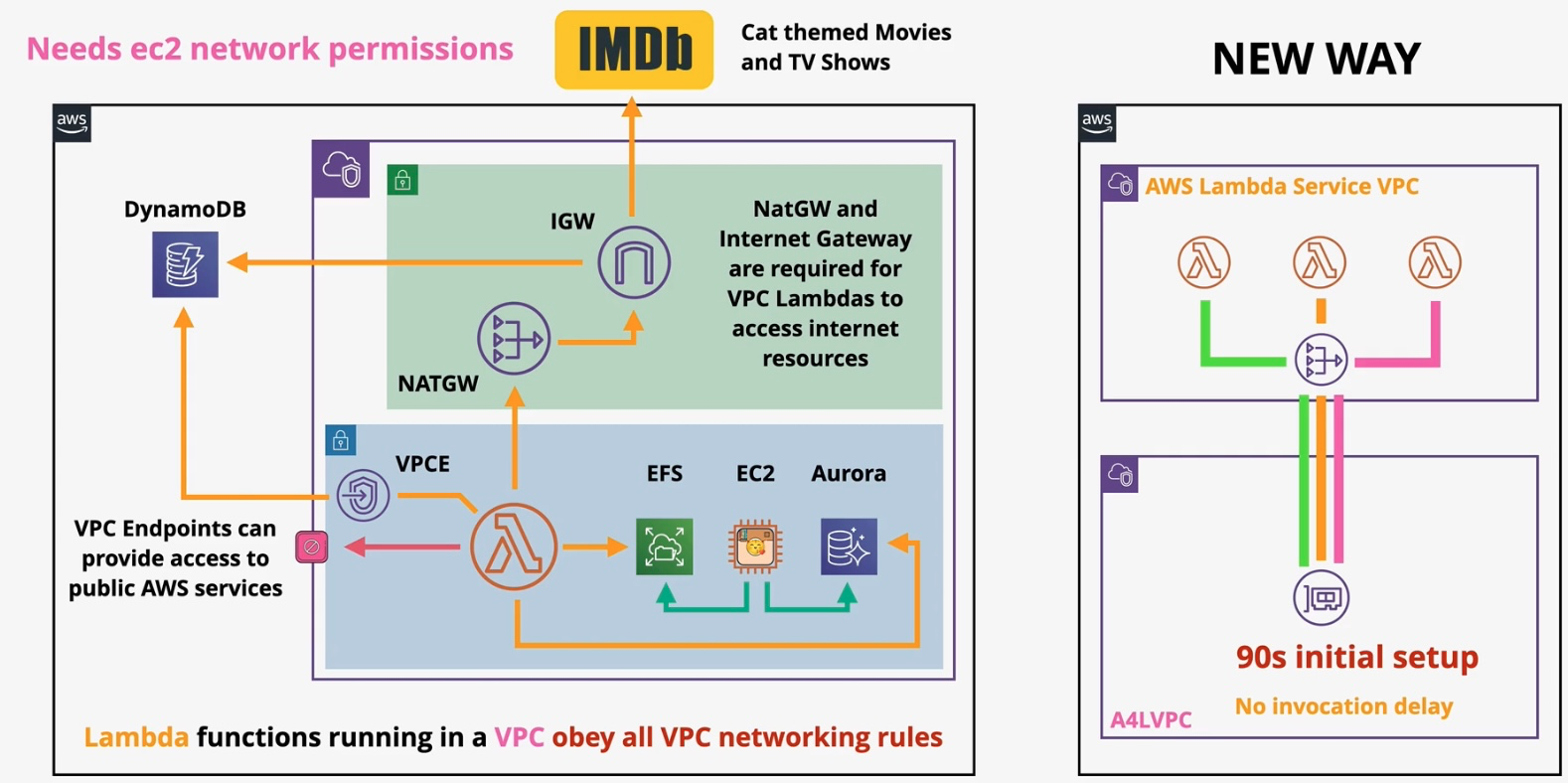
Security
- Resource policies can only be changed via CLI or API
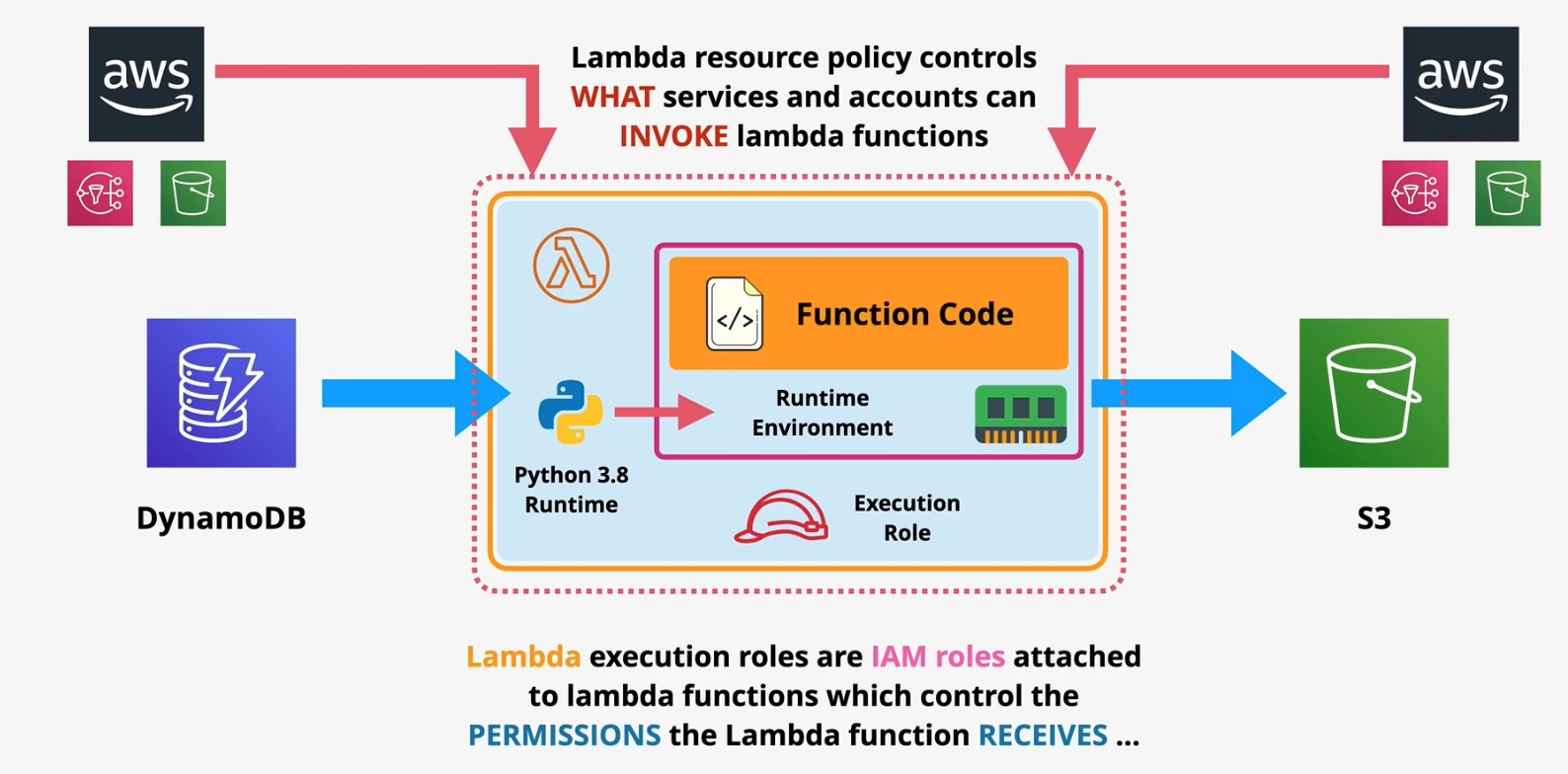
Logging
- Lambda uses CloudWatch, CloudWatch Logs & X-Ray
- Logs from Lambda executions - CloudWatchLogs
- Metrics - invocation success/failure, retries, latency… stored in CloudWatch
- Lambda can be integrated with X-Ray for distributed tracing
- CloudWatch Logs requires permissions via Execution Role
Invocation
Three types: Synchronous, asynchronous and Event Source mappings
Synchronous
- Handle errors or retries on client-side
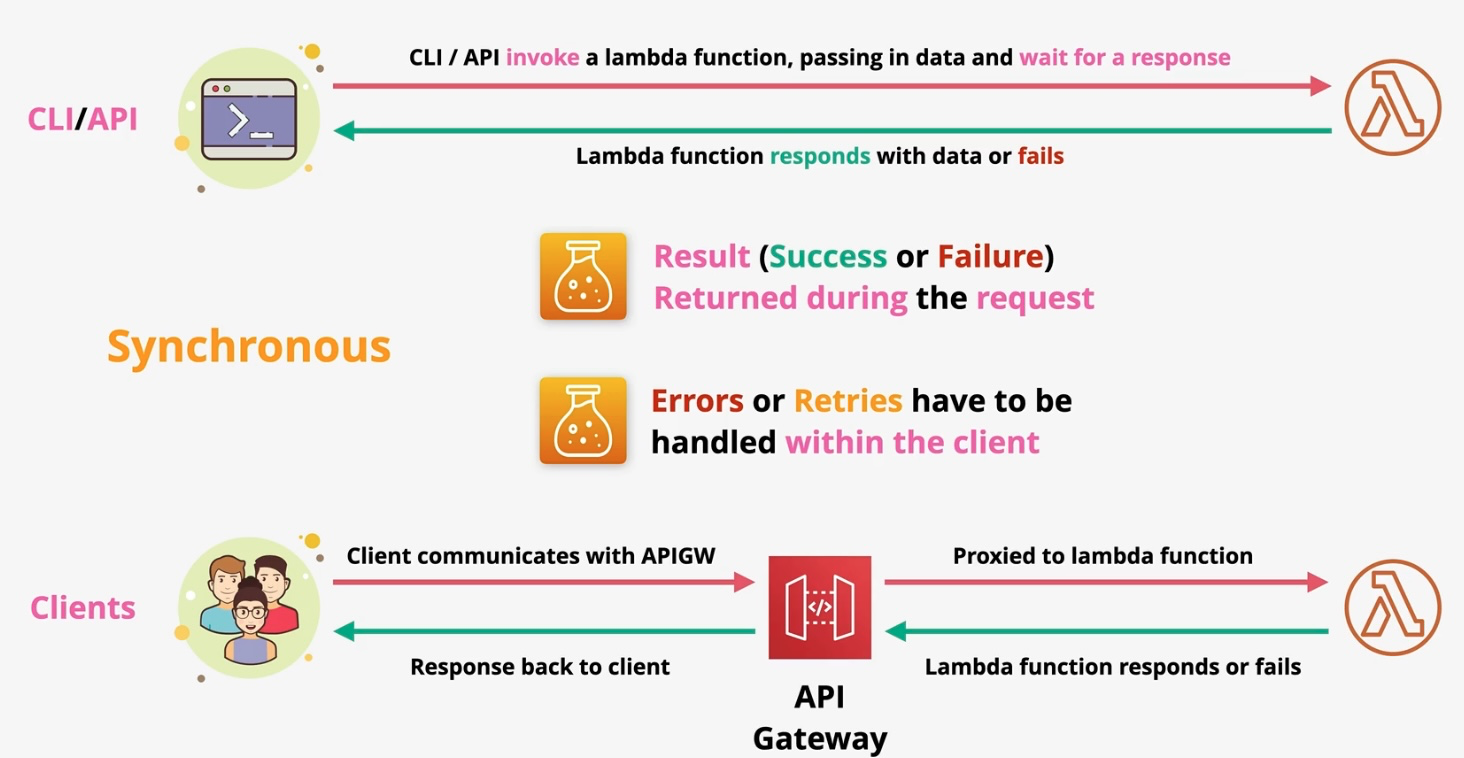
Asynchronous
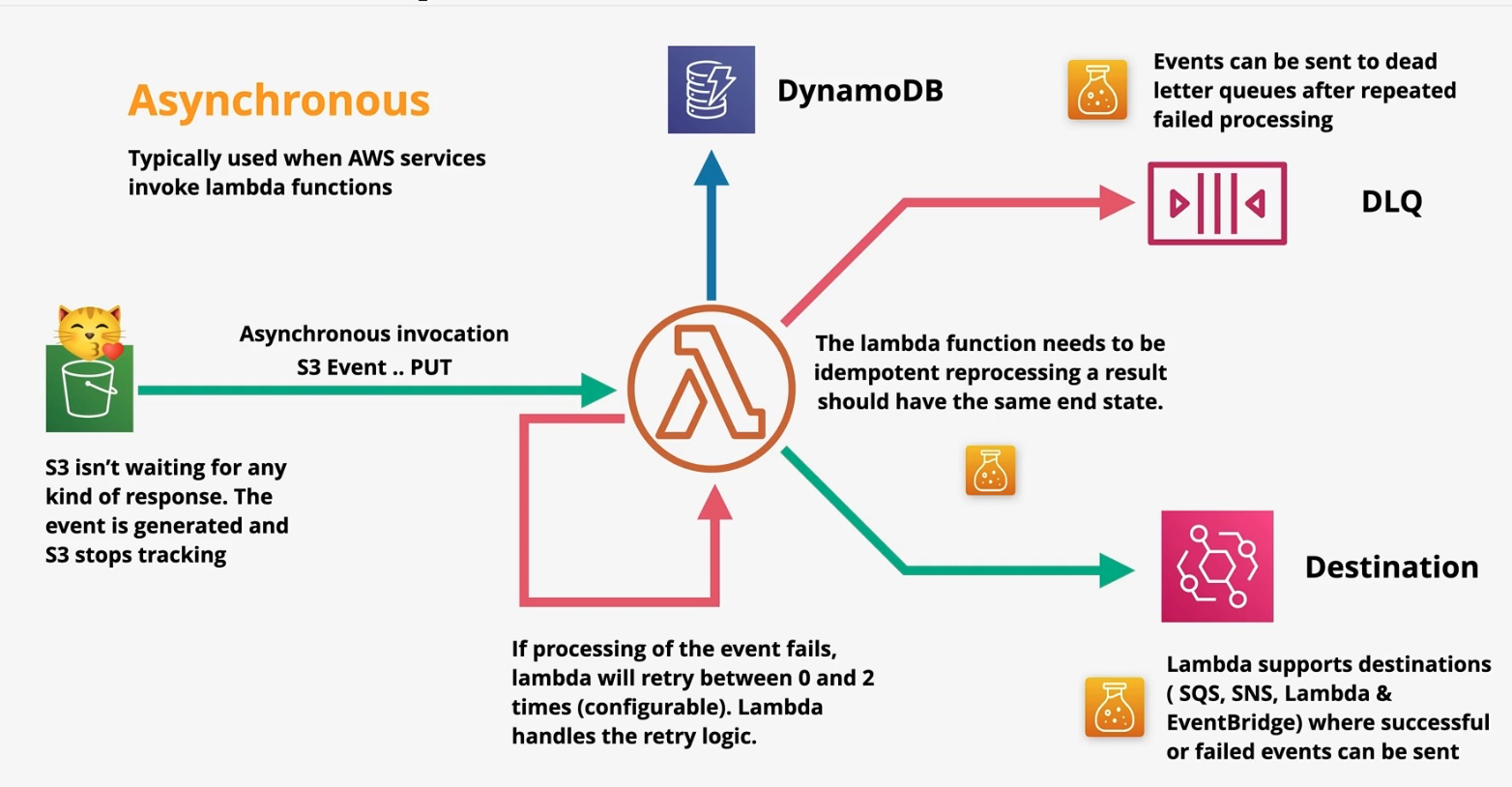
Event Source Mapping
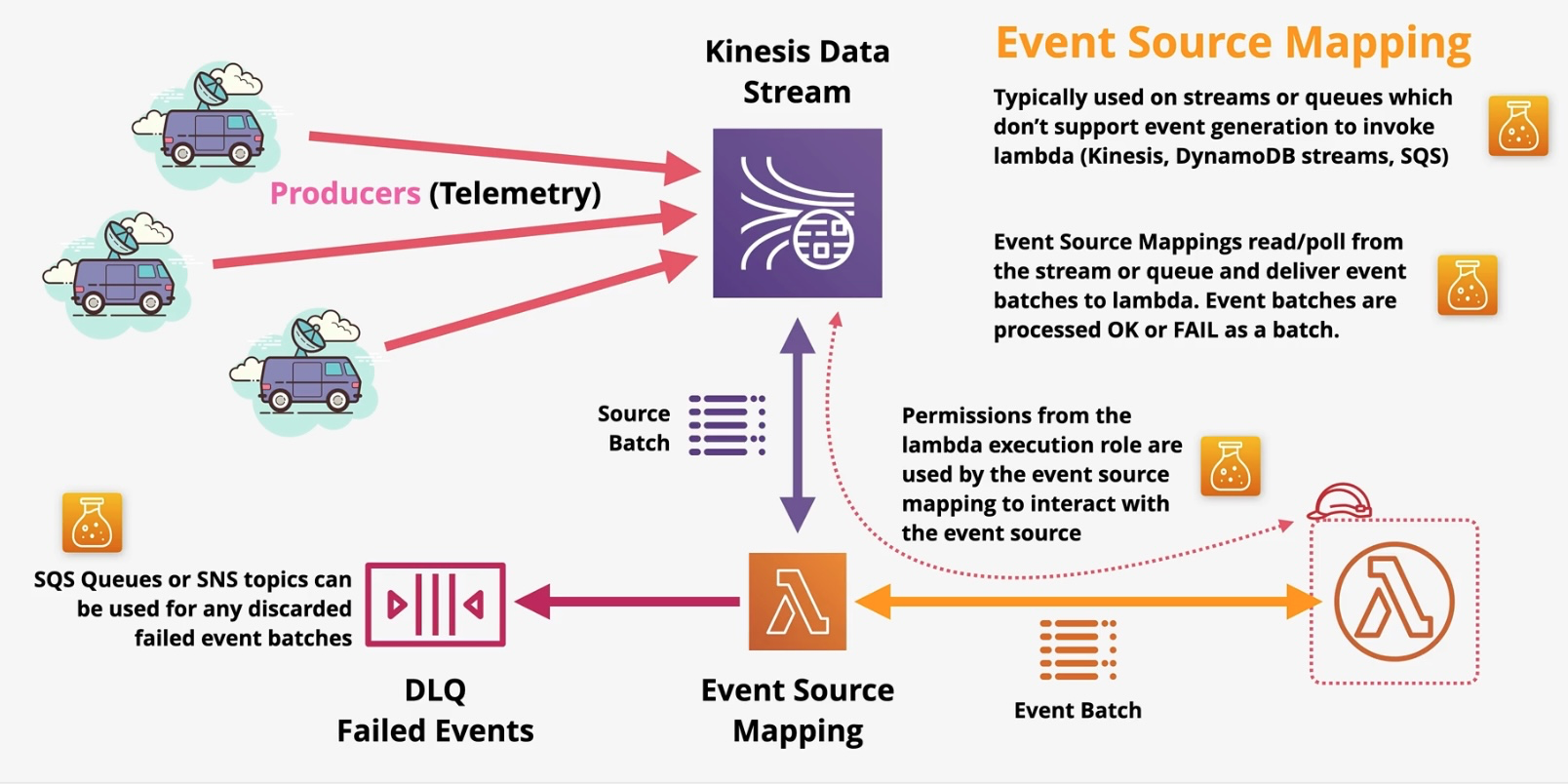
Versions
- Lambda have versions - v1, v2, v3
- A version is the code + the configuration of the lambda function
- Its immutable it never changes once published & has its own Amazon Resource Name (ARN)
- $Latest points at the latest version
- Aliases (DEV, STAGE, PROD) point at a version - can be changed
Startup Times
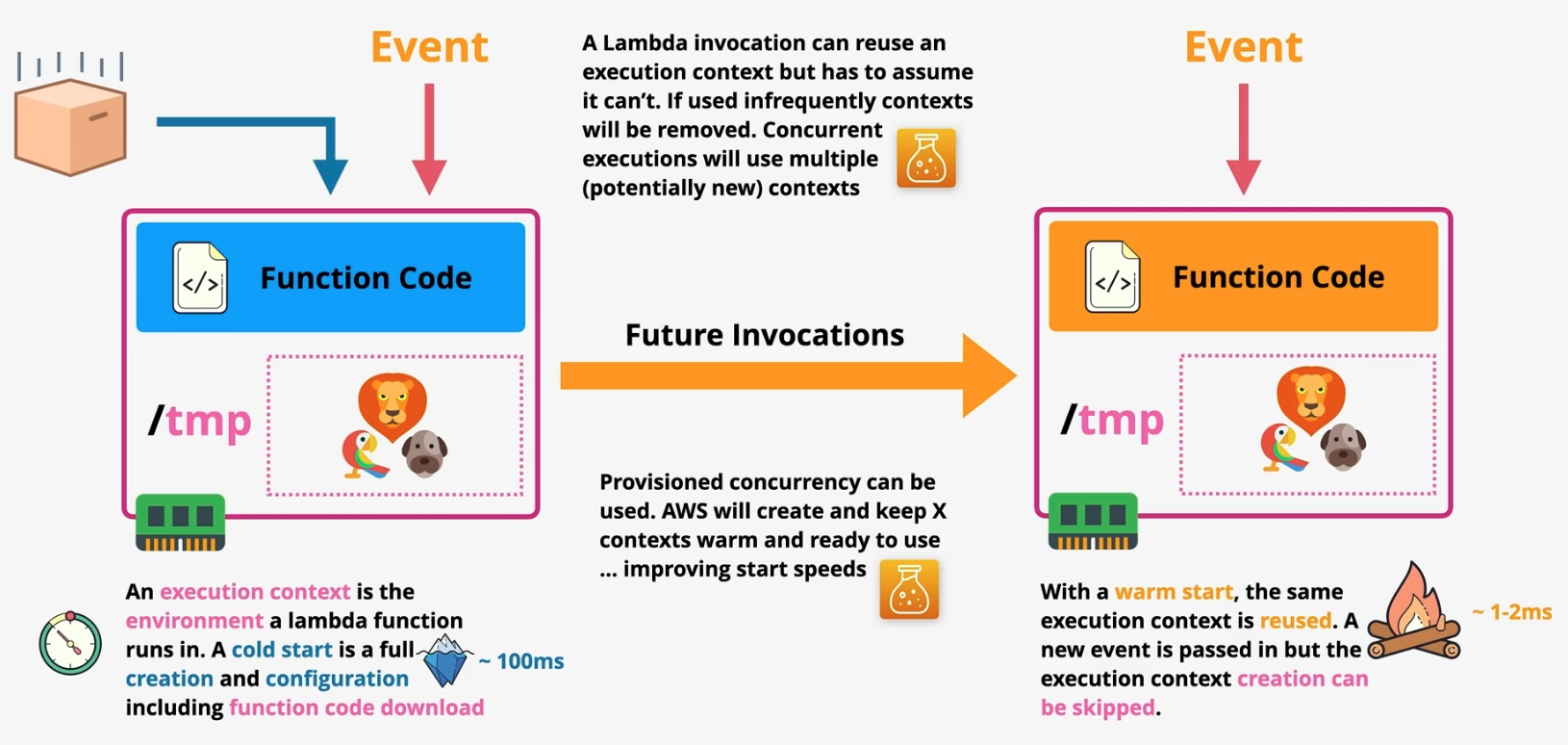
CloudWatchEvents and EventBridge
CloudWatch Events and EventBridge have visibility over events generated by supported AWS services within an account.
They can monitor the default account event bus - and pattern match events flowing through and deliver these events to multiple targets.
They are also the source of scheduled events which can perform certain actions at certain times of day, days of the week, or multiple combinations of both - using the Unix CRON time expression format. Both services are one way how event driven architectures can be implemented within AWS.
💡 EventBridge is replacing CloudWatchEvents
Key Concepts
- If X happens, or at Y time(s), do Z
- EventBridge is sort of CloudWatch Events v2
- Use EventBridge!
- A default Event bus for the account
- In CloudWatch Events this is the only bus (implicit)
- EventBridge can have additional busses
- Rules match incoming events (or schedules)
- Schedules sort of like CRON jobs
- Route the events to 1+ Targets, e.g. Lambda
EventBridge / CloudWatch Events
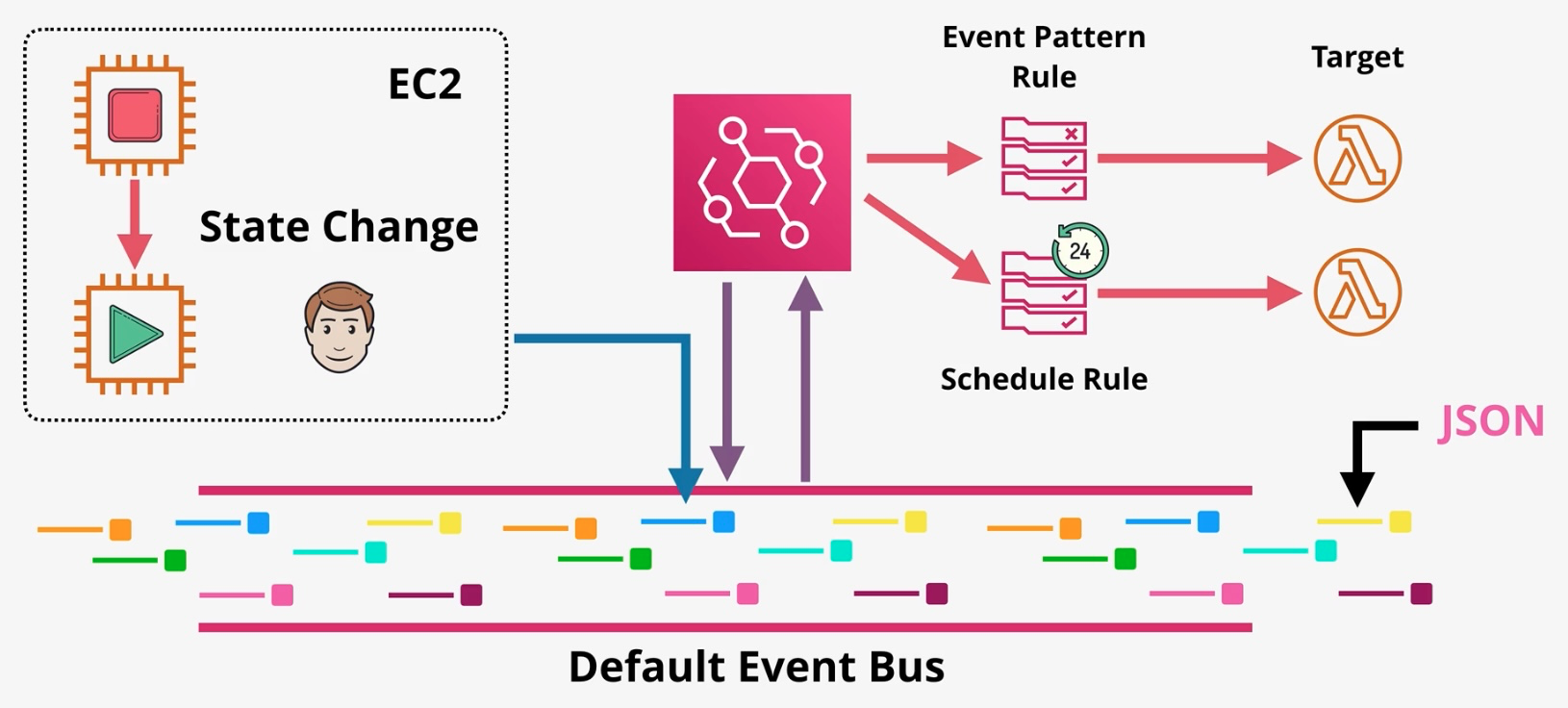
Serverless Architecture
The Serverless architecture is a evolution/combination of other popular architectures such as event-driven and microservices.
It aims to use 3rd party services where possible and FAAS products for any on-demand computing needs.
Using a serverless architecture means little to no base costs for an environment - and any cost incurred during operations scale in a way with matches the incoming load.
Serverless starts to feature more and more on the AWS exams - so its a critical architecture to understand.
What is serverless
- Serverless isn’t one single thing
- Software architecture
- You manage few, if any servers - low overhead
- Applications are a collection of small & specialized functions
- Stateless and Ephemeral environments - duration billing
- Event-driven - consumption only when being used
- FaaS is used where possible for compute functionality
- Managed services are used where possible
Serverless Architecture Example
Simple Notification Service (SNS)
The Simple Notification Service or SNS .. is a PUB SUB style notification system which is used within AWS products and services but can also form an essential part of serverless, event-driven and traditional application architectures.
Publishers send messages to TOPICS
Subscribers receive messages SENT to TOPICS.
SNS supports a wide variety of subscriber types including other AWS services such as LAMBDA and SQS.
- Public AWS Service - network connectivity with Public Endpoint
- Coordinates the sending and delivery of messages
- Messages are ≤ 256 KB payloads
- SNS Topics are the base entity of SNS - permissions and configuration
- A Publisher sends messages to a TOPIC
- TOPICS have Subscribers which receive messages
- e.g. HTTP(S), Emails(-JSON), SQS, Mobile Push, SMS Messages & Lambda
- SNS used across AWS for notifications - e.g. CloudWatch and CloudFormation
- Delivery Status (including HTTP, Lambda, SQS)
- Delivery Retries - Reliable Delivery
- HA and Scalable (Region)
- Server Side Encryption (SSE)
- Cross-Account via TOPIC Policy
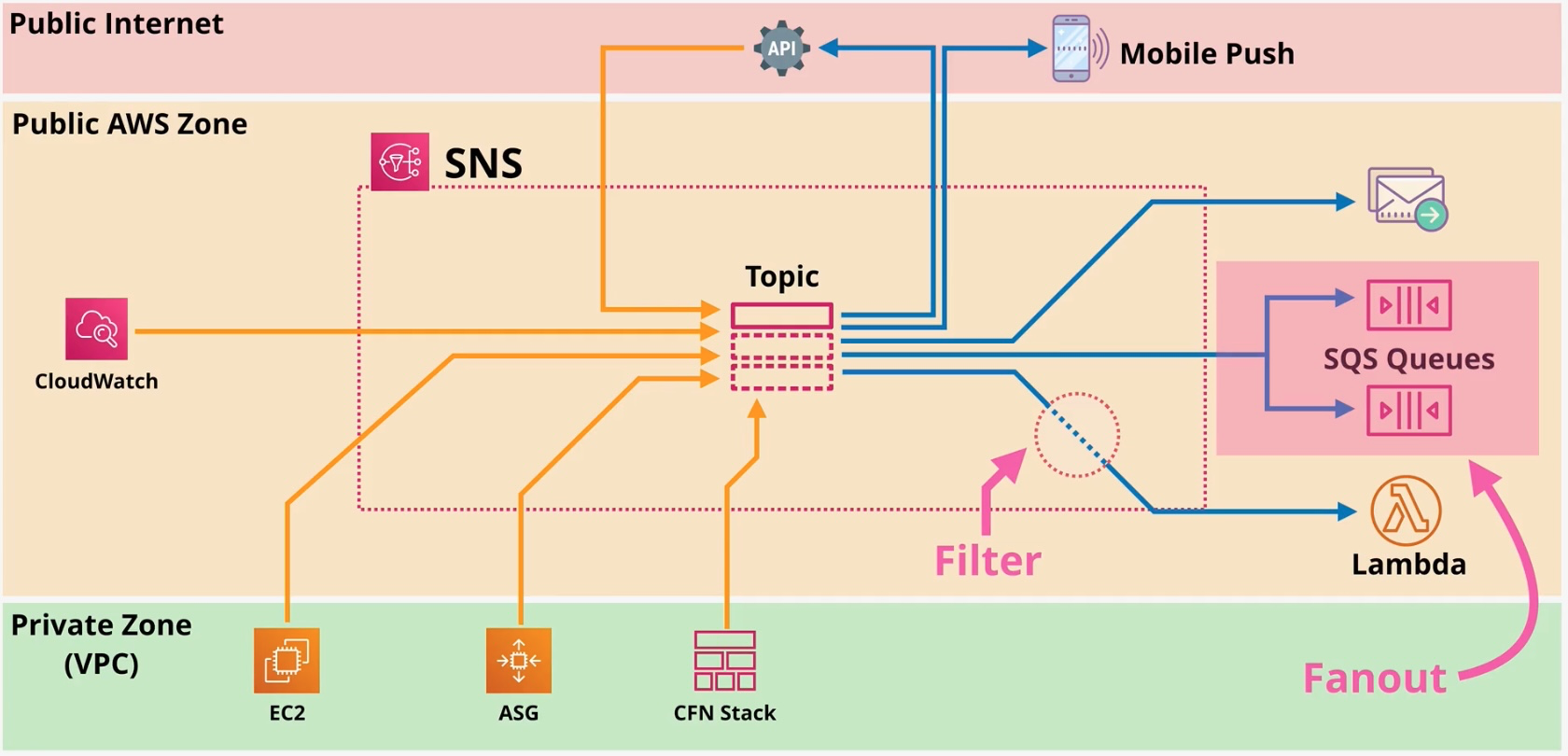
Step Functions
Step functions is a product which lets you build long running serverless workflow based applications within AWS which integrate with many AWS services.
Some problems with Lambda (Limitations)
- Lambda is FaaS
- Never put a full application inside lambda (15 min timeout)
- Lambda can be chained together - gets messy at scale
- Runtime Environments are stateless
State Machines
- Serverless workflow: Start → States → End
- States are THINGS which occur
- Maximum Duration 1 year
- Standard Workflow and Express Workflow
- Started via API Gateway, IOT Rules, EventBridge, Lambda …
- Amazon States Language (ASL) - JSON Template
- IAM Role is used for permissions
States
- SUCCED & FAIL
- WAIT
- Period of time or to specific time
- CHOICE
- PARALLEL
- MAP
- TASK (Lambda, Batch, DynamoDB, ECS, SNS, SQS, Glue, SageMaker, EMR, Step Functions)
API Gateway
API Gateway is a managed service from AWS which allows the creation of API Endpoints, Resources & Methods.
The API gateway integrates with other AWS services - and can even access some without the need for dedicated compute.
It serves as a core component of many serverless architectures using Lambda as event-driven and on-demand backing for methods.
It can also connect to legacy monolithic applications and act as a stable API endpoint during an evolution from a monolith to microservices and potentially through to serverless.
Refresher
- Create and manage APIs
- Endpoint/entry-point for applications
- Sits between applications & integrations (services)
- Highly available, scalable, handles authorization, throttling, caching, CORS, transformations, OpenAPI spec, direct integration and much more
- Can connect to services/endpoints in AWS or on-premises
- HTTP APIs, REST APIs and Websocket API
OVERVIEW
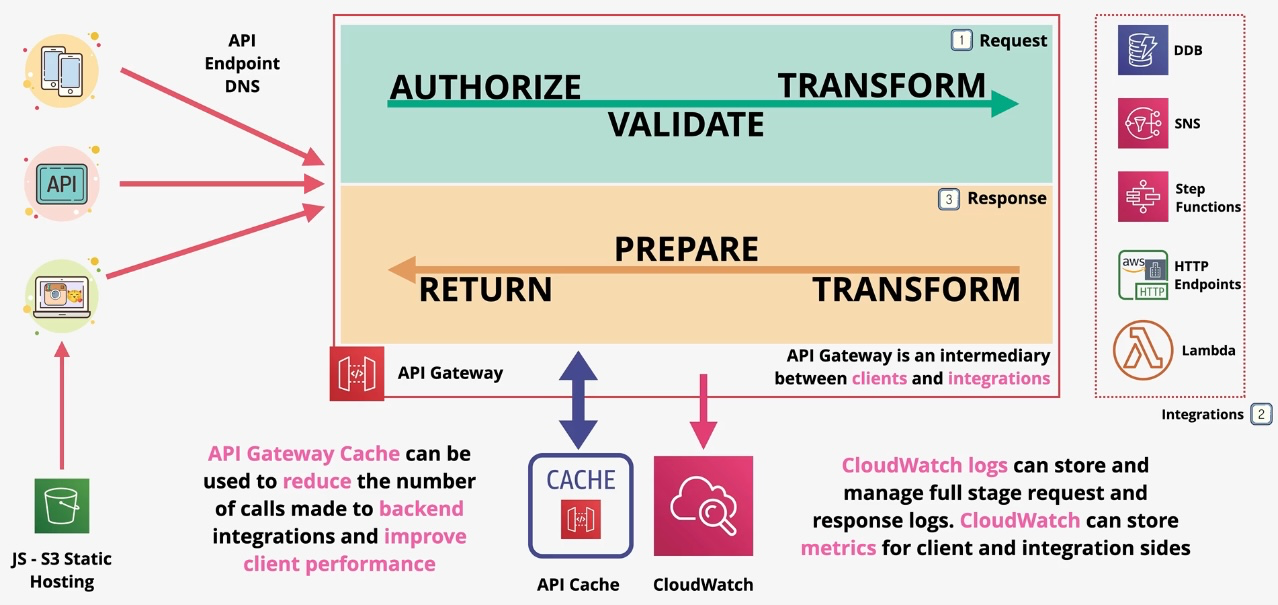
Authentication
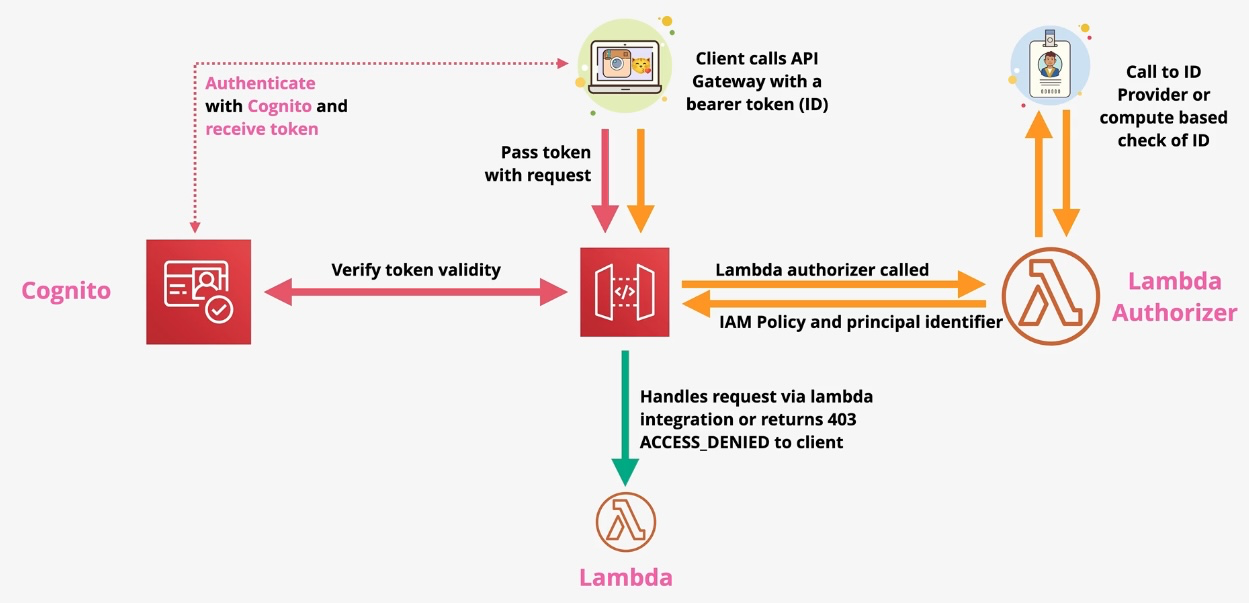
Endpoint Types
- Edge-Optimized: Routed to the nearest CloudFront POP
- Regional: Clients in the same region
- Private: Endpoint only accessible within a VPC via interface endpoint
Stages

Errors
💡 Remember these!
- 4XX - Client Error - Invalid request on client side
- 5XX - Server Error - Valid request, backend issue
- 400 - Bad Request - Generic
- 403 - Access Denied - Authrorizer denies… WAF Filtered
- 429 - API Gateway can throttle - this means you’ve exceeded that amount
- 502 - Bad Gateway Exception - bad output returned by lambda
- 503 - Service Unavailable - backing endpoint offline? Major service issues
- 504 - Integration Failure/Timeout - 29 s limit
https://docs.aws.amazon.com/apigateway/latest/api/CommonErrors.html
Caching
- TTL Default 300 seconds (min 0, max 3600)
- Can be encrypted
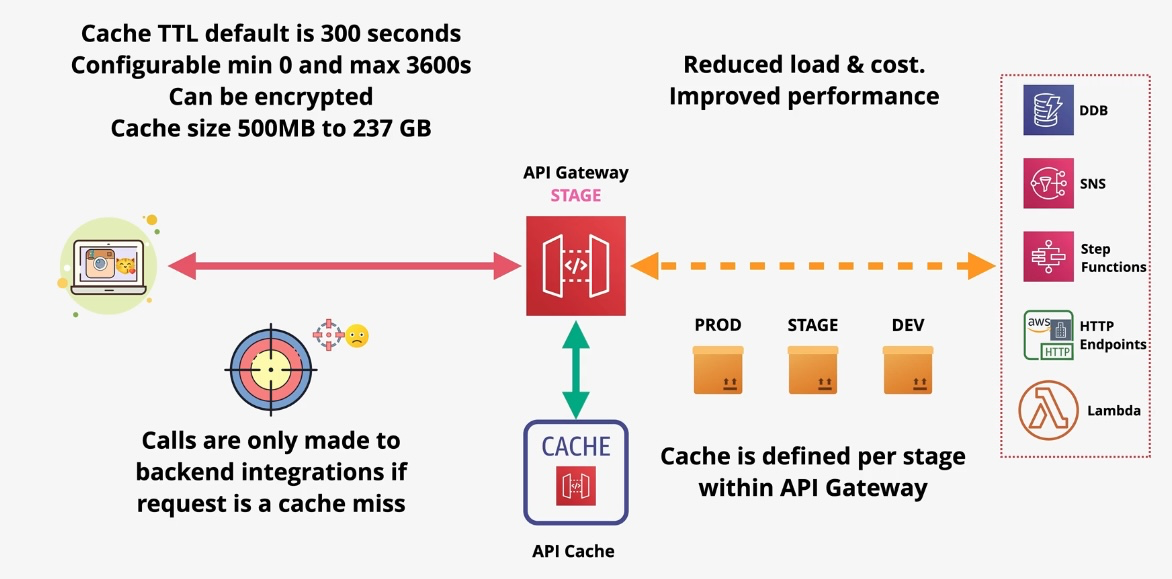
Simple Queue Service (SQS)
SQS queues are a managed message queue service in AWS which help to decouple application components, allow Asynchronous messaging or the implementation of worker pools.
- Public, fully managed, highly-available queues - Standard or FIFO
- Standard = at-least-one
- FIFO = exactly-once
- FIFO Performance: 3000 messages per second with batching, or up to 300 messages per seconds without
- Billed on “requests”
- 1 request = 1-10 messages up to 256KB total
- Short (immediate) vs Long (waitTimeSeconds) Polling
- Encryption at rest (KMS) & in-transit
- Messages up to 256KB in size - link to large data
- Received messages are hidden (VisibilityTimeout)
- then either reappear (retry) or are explicitly deleted
- Dead-Letter Queues can be used for problem messages
- ASGs can scale and Lambdas invoke based on queue length
- Queue policy
- Like resource policy
- ❗Default 4 days, max 14 days ❗
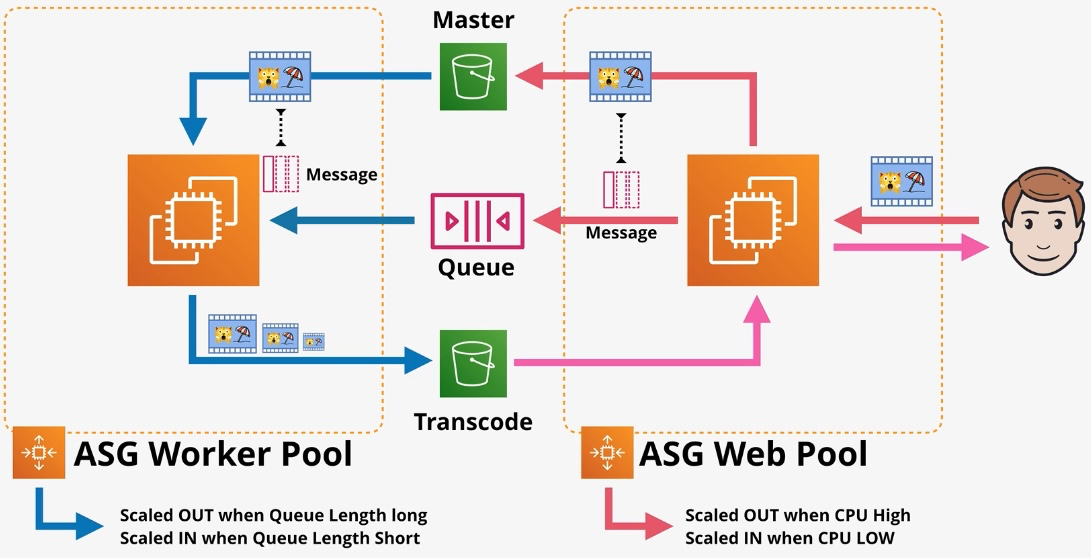
SQS Standard vs FIFO
FIFO
- Single Lane Highway
- 300 TPS w/o Batching
- 3000 TPS with batching
- Exactly once processing
- Duplicates are removed
- Message order is strictly preserved
Standard
- Multi Lane Highway
- Scalable, as wide as required
- Near unlimited TPS
- Best-effort ordering, no rigid preservation of message order
- At least once delivery, can be more than one copy of a message
- Decoupling, worker pools, batch for future processing
SQS Delay Queues
Delay queues provide an initial period of invisibility for messages. Predefine periods can ensure that processing of messages doesn't begin until this period has expired.
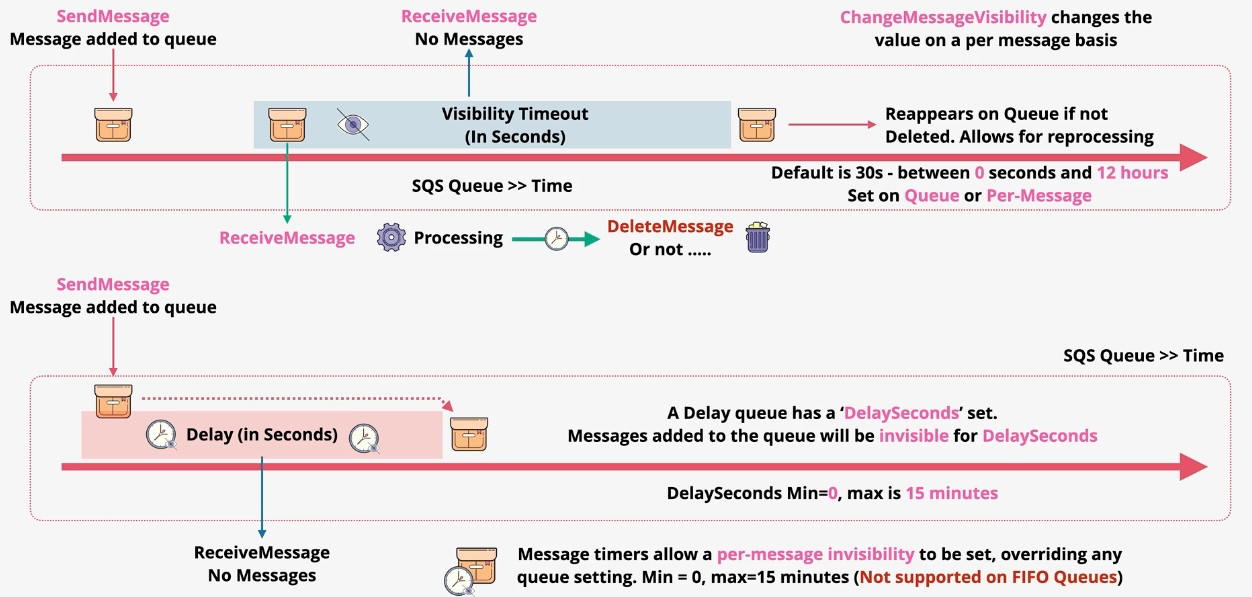
SQS Dead-Letter Queues
Dead letter queues allow for messages which are causing repeated processing errors to be moved into a dead letter queue in this queue, different processing methods, diagnostic methods or logging methods can be used to identity message faults
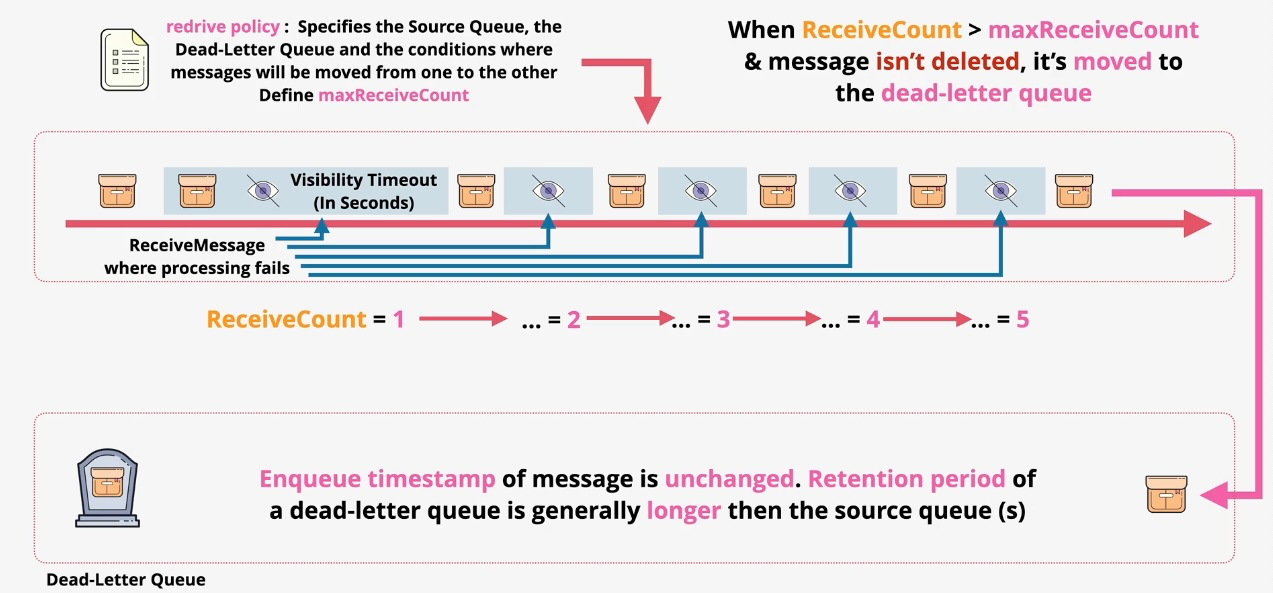
Amazon Kinesis Data Streams
Kinesis data streams are a streaming service within AWS designed to ingest large quantities of data and allow access to that data for consumers.
Kinesis is ideal for dashboards and large scale real time analytics needs.
Kinesis data firehose allows the long term persistent storage of kinesis data onto services like S3
-
Kinesis is a scalable streaming service
-
Producers send data into a kinesis stream
-
Streams can scale from low to near infinite data rates
-
Public service & highly available by design
-
Streams store a 24-hour moving window of data
- can be increased to a maximum of 365 days (additional cost)
-
Multiple consumers access data from that moving window
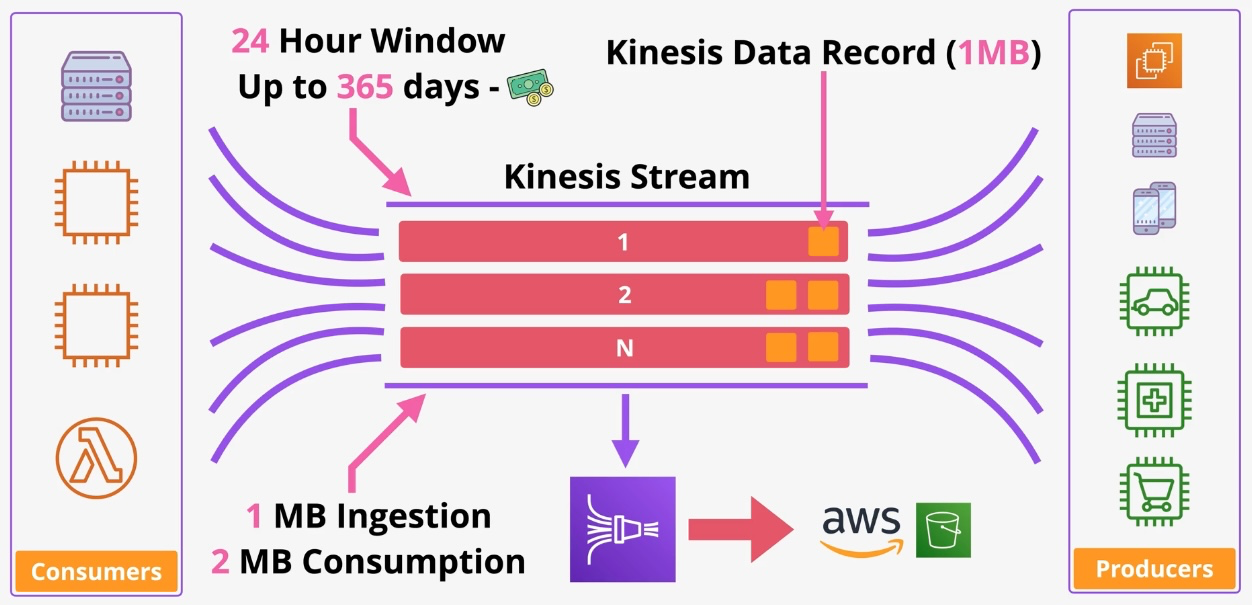
SQS vs Kinesis
- Ingestion of data - Kinesis
- Else: SQS
- SQS 1 production group, 1 consumption group
- SQS: Decoupling and Async communication
- SQS: No persistence of messages, no window
- Kinesis: Designed for huge scale ingestion, multiple consumers and rolling window
- Kinesis: Data ingestion, analytics, monitoring, app click
Amazon Kinesis Data Firehose
Kinesis Data Firehose is a stream based delivery service capable of delivering high throughput streaming data to supported destinations in near realtime.
Its a member of the kinesis family and for the PRO level exam it's critical to have a good understanding of how it functions in isolation and how it integrates with AWS products and services.
- Fully managed service to load data for data lakes, data stores and analytics services
- Automatic scaling - fully serverless, resilient
- Near Real Time delivery (~60 seconds)
- Supports transformation of data on the fly (Lambda)
- Billing - volume through firehose
- Can deliver data to: Redshift, ElasticSearch, Destination Bucket, Splunk
- Can be integrated with Kinesis Data Stream
- When? E.g. when you want to store data from a data stream past the rolling window
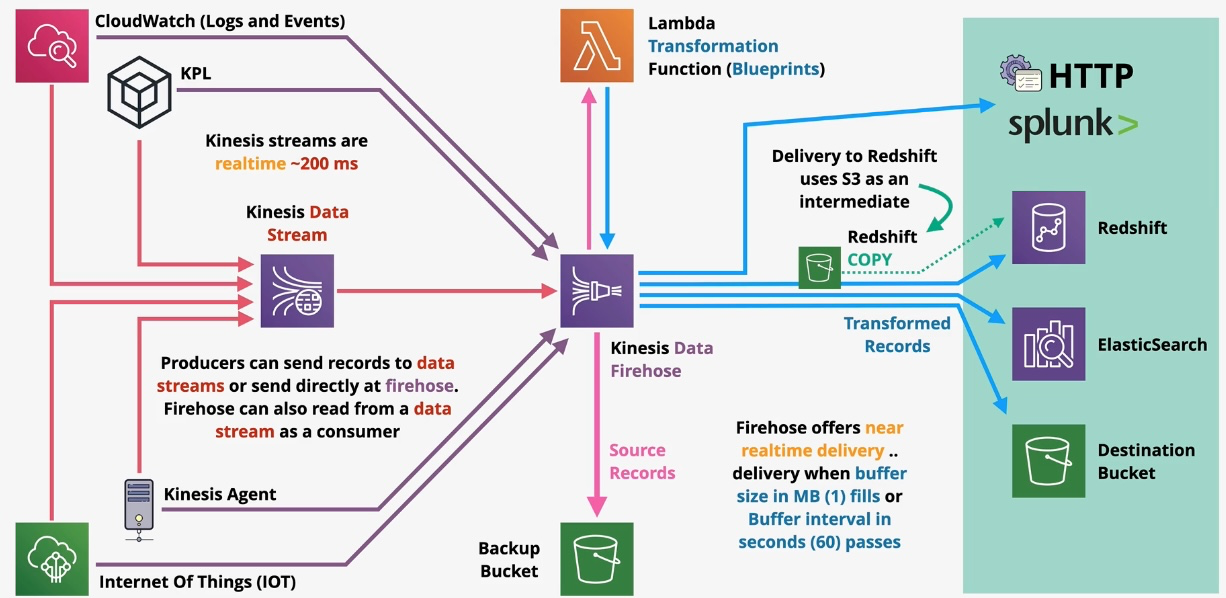
Amazon Kinesis Data Analytics
Amazon Kinesis Data Analytics is the easiest way to analyze streaming data, gain actionable insights, and respond to your business and customer needs in real time.
it is part of the kinesis family of products and is capable of operating in realtime on high throughput streaming data.
- Real time processing of data
- Using SQL
- Ingests from Kinesis Data Streams or Firehose
- Destinations
- Firehose (S3, Redshift, ElasticSearch & Splunk)
- AWS Lambda
- Kinesis Data Streams
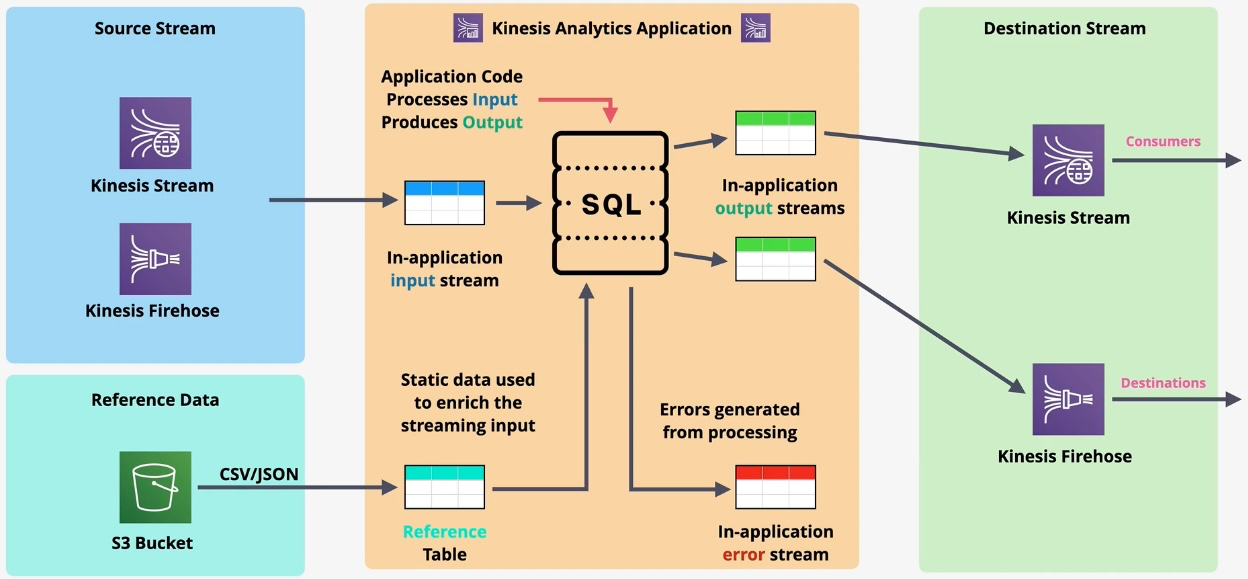
When and Where
- Streaming data needling real-time SQL processing
- Time-series analytics
- Elections / e-sports
- Real-time dashboards - leaderboards for games
- Real-time metrics - Security and Response teams
Amazon Kinesis Video Streams
Amazon Kinesis Video Streams makes it easy to securely stream video from connected devices to AWS for analytics, machine learning (ML), playback, and other processing. Kinesis Video Streams automatically provisions and elastically scales all the infrastructure needed to ingest streaming video data from millions of devices
- Ingest live video data from producers
- Security cameras, smartphones, cars, drones, time-serialized audio, thermal, depth and RADAR
- Consumers can access data frame-by-frame or as need
- Can persist and encrypt (in-transit and at rest) data
- Can’t access directly via storage - only via APIs
- Integrates with other AWS services e.e.g Rekognition and Connect
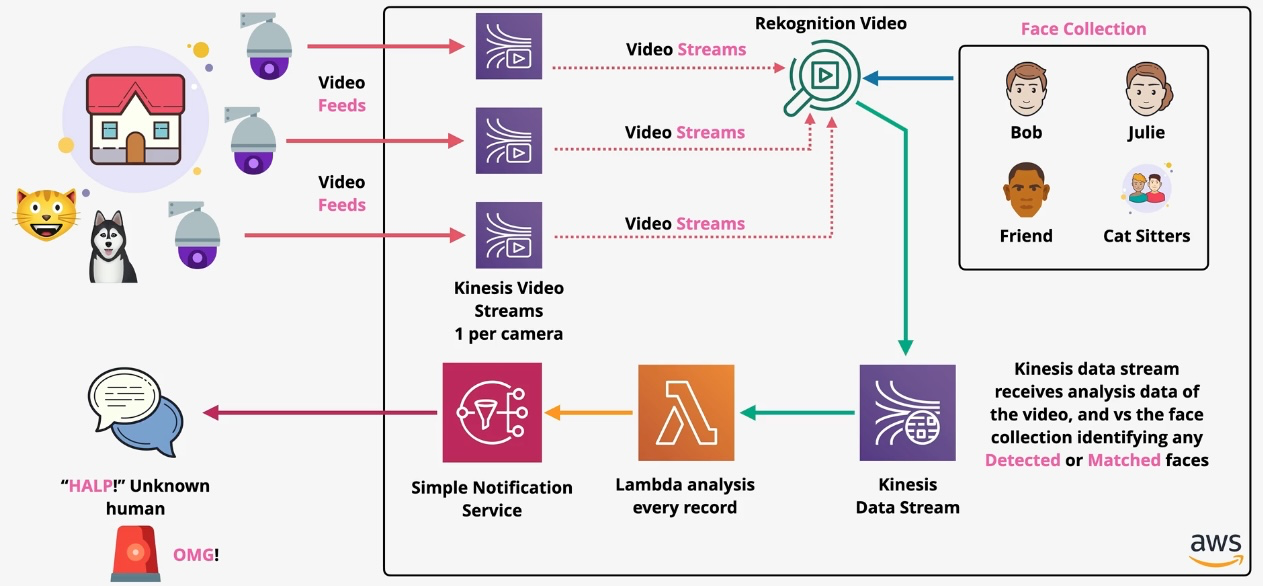
Amazon Cognito - User and Identity Pools
A user pool is a user directory in Amazon Cognito. With a user pool, your users can sign in to your web or mobile app through Amazon Cognito. Your users can also sign in through social identity providers like Google, Facebook, Amazon, or Apple, and through SAML identity providers. Whether your users sign in directly or through a third party, all members of the user pool have a directory profile that you can access through a Software Development Kit (SDK).
Amazon Cognito identity pools (federated identities) enable you to create unique identities for your users and federate them with identity providers. With an identity pool, you can obtain temporary, limited-privilege AWS credentials to access other AWS services.
- Cognito has terrible naming
- Authentication, authorization and user management for web/mobile apps
- Two parts of Cognito: User Pools an identity pools
- USER POOLS: Sign-in and get a JSON Web Token (JWT)
- User directory management and profiles, sign-up and sign-in (customizable web UI), MFA and other security features
- IDENTITY POOLS: Allow you to offer access to Temporary AWS Credentials
- Unauthenticated Identities: Guest Users
- Federated Identities: SWAP - Google, Facebook, Twitter, SAML2.0 & User Pool for short term AWS Credentials to access AWS Resources
- Identity pools assume an IAM role
Architecture: User Pools
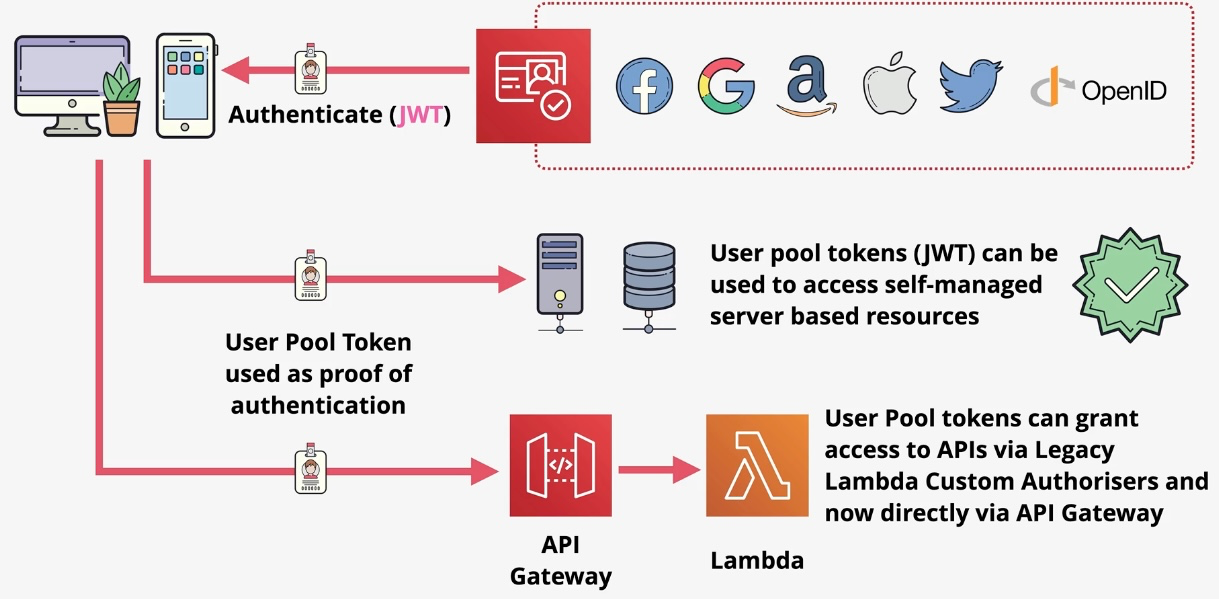
Architecture: Identity Pools
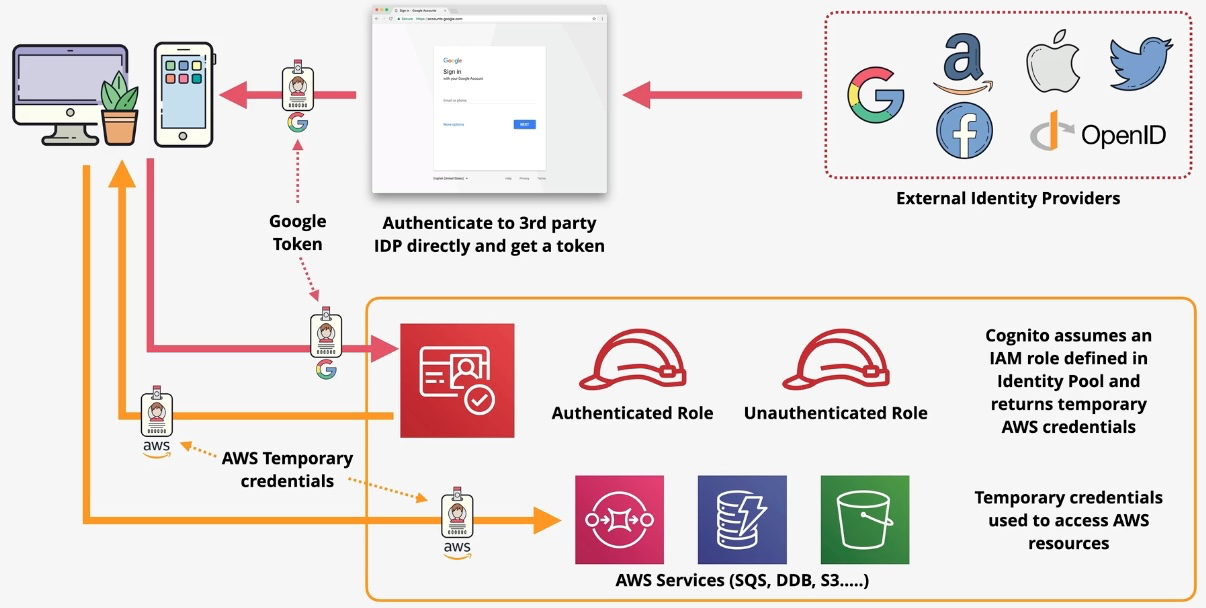
Architecture: User & Identity Pools
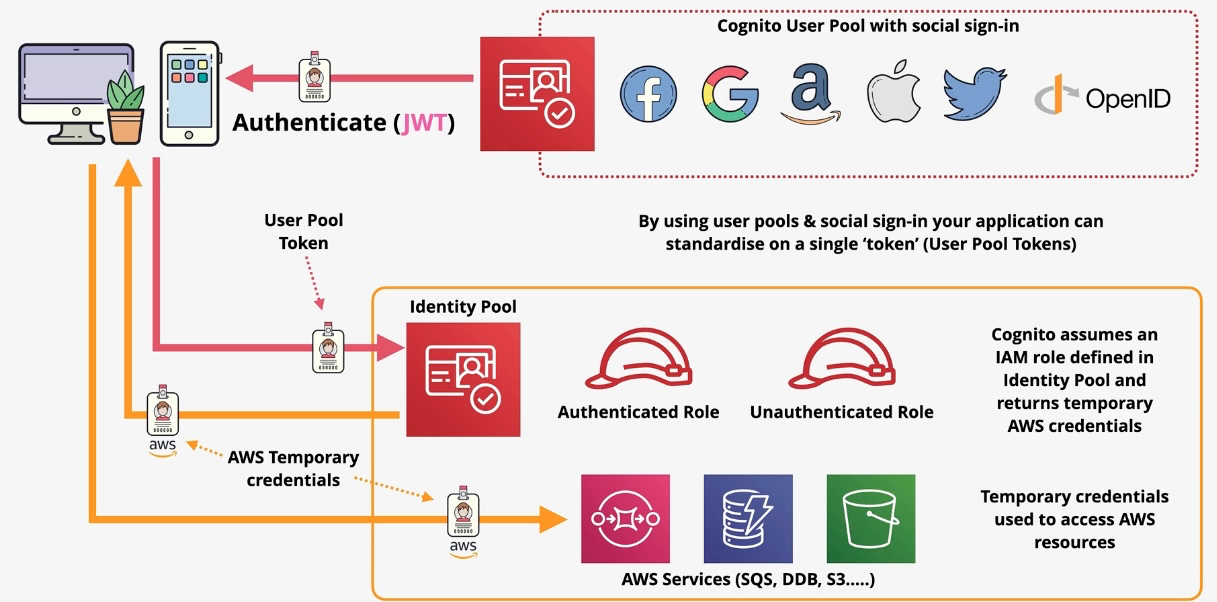
AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics. You can create and run an ETL job with a few clicks in the AWS Management Console. You simply point AWS Glue to your data stored on AWS, and AWS Glue discovers your data and stores the associated metadata (e.g. table definition and schema) in the AWS Glue Data Catalog. Once cataloged, your data is immediately searchable, queryable, and available for ETL.
- Serverless ETL (Extract, Transform, Load)
- vs data pipeline (which can do ETL) and users servers (EMR)
- Moves and transforms data between source and destination
- Crawls data sources and generates the AWS Glue Data catalog
- Data source**: Stores**: S3, RDS, JDBC Compatible and DynamoDB
- Data source: Streams: Kinesis Data Stream & Apache Kafka
- Data Targets: S3, RDS, JDBC Databases
Data Catalog
- Persistent metadata about data sources in region
- One catalog per region per accont
- Avoids data silos
- Amazon Athena, Redshift Spectrum, EMR & AWS Lake Formation all use Data Catalog
- configure crawlers for data sources
AWS Glue
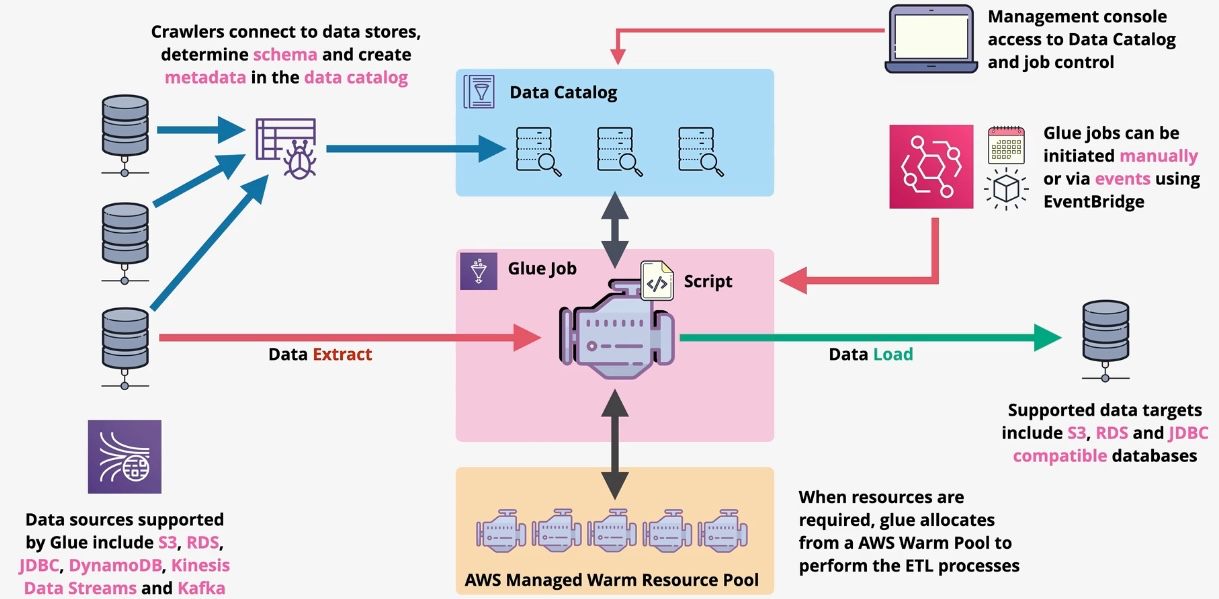
Amazon MQ
AmazonMQ is an AWS implementation of Apache ActiveMQ
It supports open standards such as JMS, AMQP, MQTT, OpenWire and STOMP
If you need to support any of these, and use queues and topics - AmazonMQ is the tool to use.
- SNS and SWS are AWS Services - using AWS APIs
- SNS provides TOPICS and SQS provides QUEUES
- Public services - highly scalable - AWS integrated
- Many ORGS already use topics and queues and want to migrate into AWS
- SNS and SQS won’t work out of the box
- We need a standards compliant solution for migration
MQ
- NOT A PUBLIC SERVICE - you need a private network connection between on-prem
- Open-source message broker
- Based on Managed Apache ActiveMQ
- JMS API - protocols such as AMQP, MQTT, OpenWire and STOMP
- Provides QUEUES and TOPICS
- One-to-one or one-to-many
- Single instance (test, dev, cheap) or HA Pair (Active/standby)
- VPC Based - Not a public service - Private networking required
- No AWS native integration - delivers activeMQ product which you manage
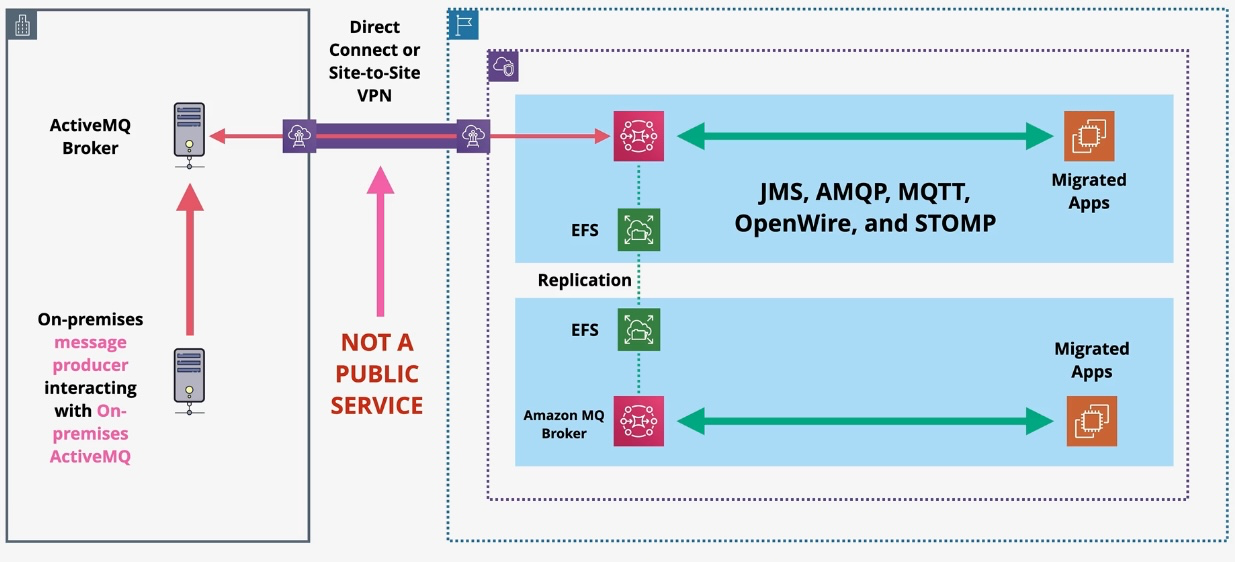
- SNS or SQS for most new implementations (default)
- SNS or SQS if AWS integration is required (logging, permissions encryptions, service integration)
- MQ if you need to migrate from an existing system with little to no application change
- MQ if APIs such as JMS or protocols such as AMQP, MQTT, OpenWite and STOMP are needed
- Remember you ned private networking for MQ
Amazon AppFlow
Amazon AppFlow is a fully managed integration service that enables you to securely transfer data between Software-as-a-Service (SaaS) applications like Salesforce, SAP, Zendesk, Slack, and ServiceNow, and AWS services like Amazon S3 and Amazon Redshift, in just a few clicks. With AppFlow, you can run data flows at enterprise scale at the frequency you choose - on a schedule, in response to a business event, or on demand. You can configure data transformation capabilities like filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps. AppFlow automatically encrypts data in motion, and allows users to restrict data from flowing over the public Internet for SaaS applications that are integrated with AWS PrivateLink, reducing exposure to security threats.
- Fully-managed integration service
- Exchange data between applications (connectors) using flows
- Syns data across applications
- Aggregate data from different sources
- Public endpoints, but works with PrivateLink (privacy)
- AppFlow Custom Connector SDK (build your own)
- E.g.
- Contact records from Salesforce → Redshift
- Support Tickets from Zendesk → S3
🌍 GLOBAL CONTENT DELIVERY AND OPTIMIZATION
CloudFront Architecture
CloudFront is a Content Delivery network (CDN) within AWS.
This lesson steps through the basic architecture
CloudFront Terms
- Origin: The source location of your content
- Used by behaviours as content sources
- S3 Origin or Custom Origin
- Distribution: The ‘configuration’ unit of CloudFront
- Edge Location: Local cache of your data
- Regional Edge Cache: Larger version of an edge location. Provides another layer of caching.
- Behaviour: Sits between origin and distribution
- private (/img/saa-guide/*)
- default (*)
- Part of distribution?
CloudFront Architecture
CloudFront Behaviors
CloudFront Behaviours control much of the TTL, protocol and privacy settings within CloudFront
- A distribution can have multiple behaviors, but have one default
- Default used when nothing else matches
CF TTL and Invalidations
- More frequent cache hits = lower origin load
- Default TLT (behavior) = 24 hours (validity period)
- You can set Min TTL and Max TTL
- Per object TTL
- Origin Header: Cache-Control max-age (seconds)
- Origin Header: Cache-Control s-maxage (seconds)
- Origin Header: Expires (Date & Time)
- Custom Origin or S3 (Via Object metadata)
- Default if not specified
Cache Invalidations
- Cache invalidation - performed on a distribution
- Applies to all edge locations - take time
- /images/whiskers1.jpg
- /images/whickers*
- /images/*
- /*
- Cache invalidations has the same cost regardless of number of hits
- Versioned file names: whiskers1_v1.jpg // _v2.jpg // _v3.jpg
- Not S3 object versioning
- More cost effective!
AWS Certificate Manager (ACM)
The AWS certificate Manage is a service which allows the creation, management and renewal of certificates. It allows deployment of certificates onto supported AWS services such as CloudFront and ALB.
- HTTP: Simple and Insecure
- HTTPS: SSL/TLS Layer of Encryption added to HTTP
- Data is encrypted in-transit
- Certificates prove identity
- Chain of trust - Signed by a trusted authority
- ACM lets you run a public or private Certificate Authority (CA)
- Private CA: Applications need to trust your private CA
- Public CA: Browsers trust a list of providers, which can trust other providers (chain of trust)
- AVM can generate or import certifications
- If generated it can automatically renew
- If imported you are responsible for renewal
- Certificates can be deployed out to supported services
- Supported AWS Services ONLY (E.g. CloudFront and ALBs… NOT EC2)
- ACM is a regional service
- Certs cannot leave the region they are generated or imported in
- To use a cert with an ALB in ap-southeast-2 you need a cert in ACM in ap-southeast-2
- Global Services such as CloudFront operate as though within us-east-1
Architecture
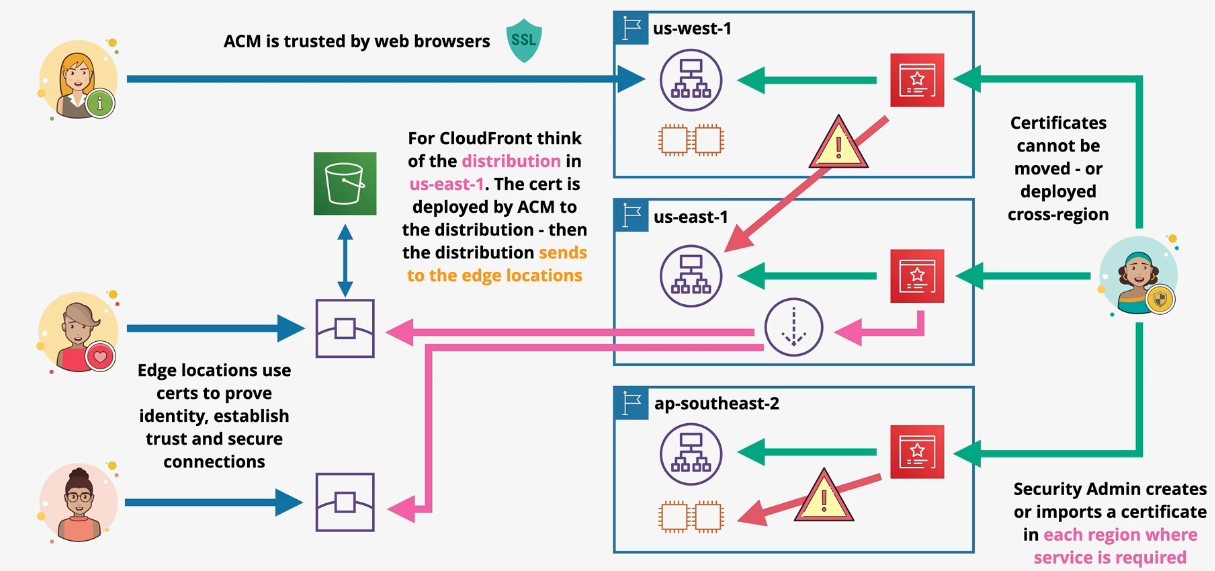
CloudFront and SSL/TLS
💡 ❗Generate or import in ACM in us-east-1 to use with CloudFront❗
- CloudFront Default Domain Name (CNAME)
- SSL supported by default - *.cloudfront.net cert
- Alternate Domain Names (CNAMES) e.g. cdn.catagram…
- Verify Ownership (optionally HTTPS) using a matching certificate
- HTTP or HTTPS, HTTP → HTTPS, HTTPS Only
- Two SSL Connections: Viewer → CloudFront and CloudFront → Origin
- Both need valid public certifications (and intermediate certs)
CloudFront and SNI
- Historically every SSL enabled site needed its own IP
- Encryption starts at the TCP connection
- Host headers happens after that: Layer 7 // Application
- Used to need multiple IPs for multiple sites if SSL enabled
- SNI is a TLS extension, allowing host to be included
- Resulting in many SSL Certs/Hosts using a shared IP
- Old browsers don’t support SNI: CF charges extra for dedicated IP
- 600$ / month
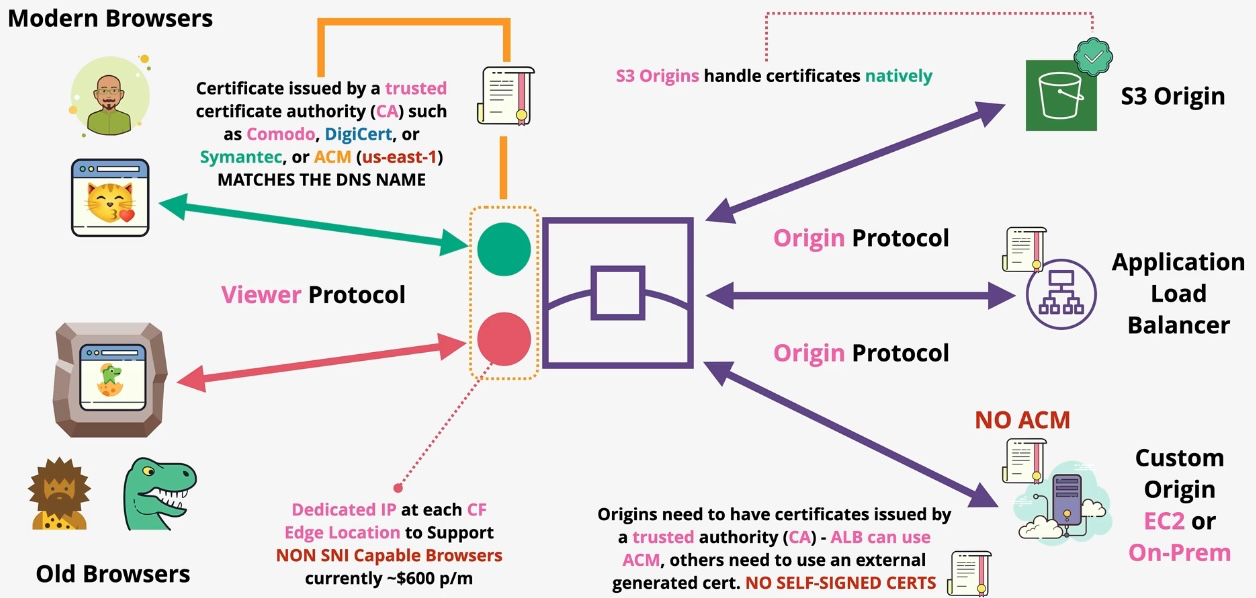
Origin Types and Architecture
CloudFront origins store content distributed via edge locations.
The features available differ based on using S3 origins vs Custom origins
Securing CF and S3 using OAI
Origin Access Identities are a feature where virtual identities can be created, associated with a CloudFront Distribution and deployed to edge locations.
Access to an s3 bucket can be controlled by using these OAI's - allowing access from an OAI, and using an implicit DENY for everything else.
They are generally used to ensure no direct access to S3 objects is allowed when using private CF Distributions.
This lesson covers the main ways to secure origins from direct access (bypassing CloudFront)
- Origin Access identities (OAI) - for S3 Origins
- Custom Headers - For Custom Origins
- IP Based FW Blocks - For Custom Origins.
Origin Access Identity (OAI)
- An OAI is a type of identity
- It can be associated with CloudFront Distributions
- CloudFront ‘becomes’ that OAI
- That OAI can be used in S3 Bucket Policies
- DENY all BUT one or more OAI’s
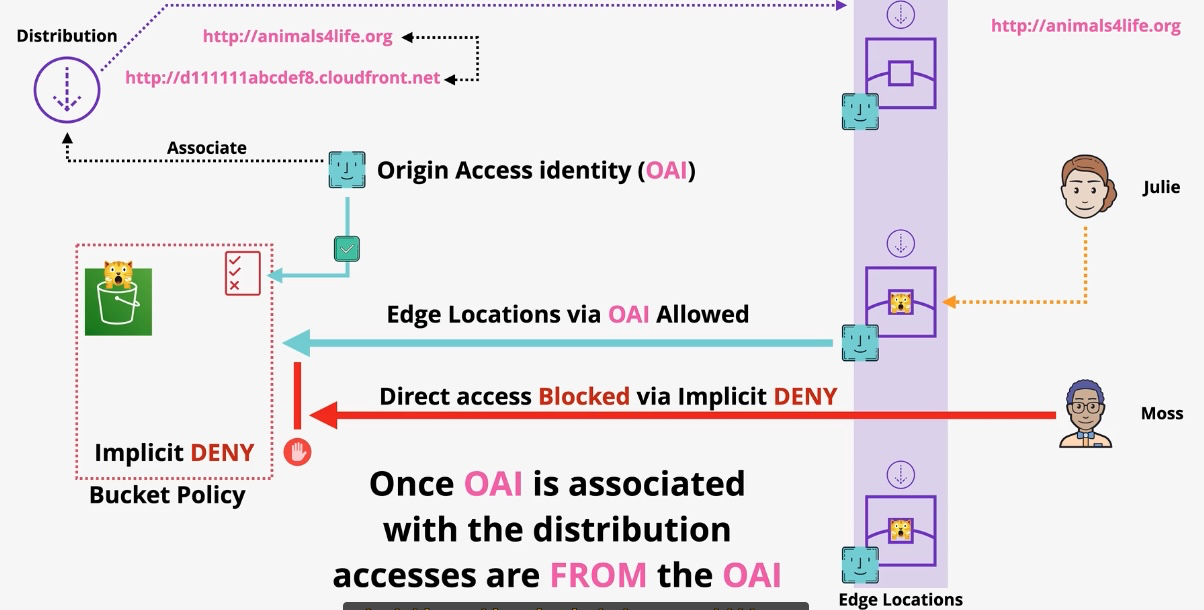
Securing Custom Origins
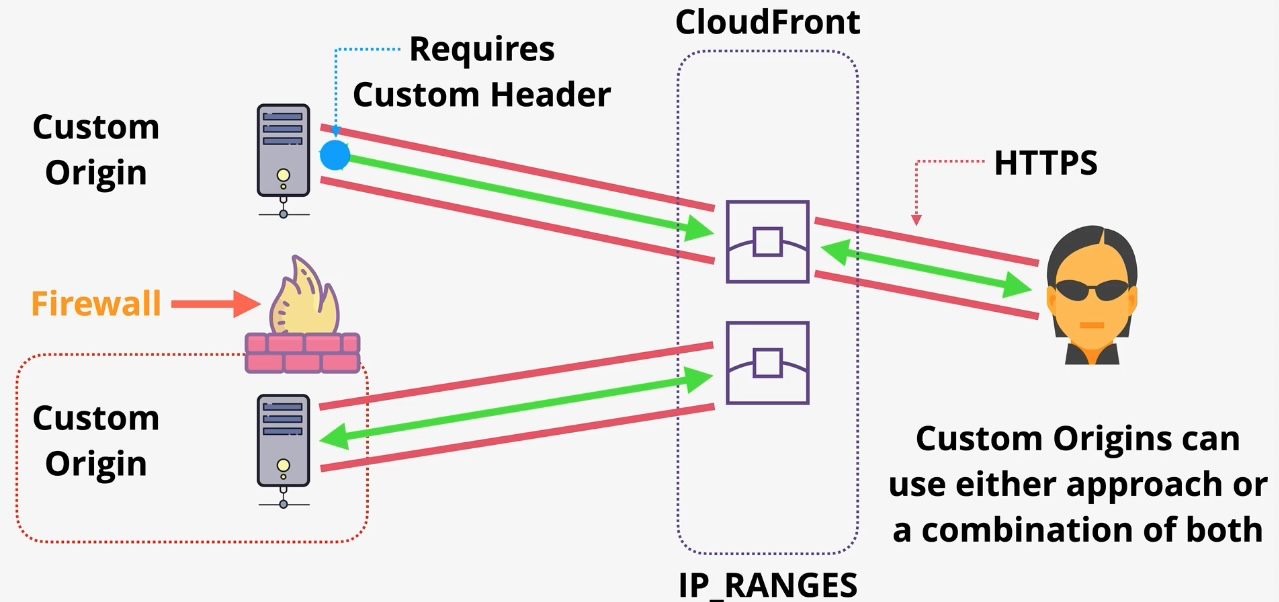
CloudFront Private Distributions & Behavior - Signed URLs & Cookies
Private Distributions (*behaviors)
- Public - Open Access to objects
- Private - Requests require Signed Cookie or URL
- 1 behavior - Whole Distribution PUBLIC or PRIVATE
- Multiple behaviors- each is PUBLIC or PRIVATE
- OLD way: A CloudFront Key is created by an Account Root User
- Then account is added as a TRUSTED SIGNER
- NEW: Trusted Key Groups added
CloudFront Signed URLs vs Cookies
- Signed URLs provides access to one object
- Historically RTMP distributions couldn’t use cookies
- Use URLs if your client doesn’t support cookies
- Cookies provides access to groups of objects
- Use for groups of files/all files of a type - e.g. all cat gifs
- Or if maintaining application URL’s is important
Private Distributions
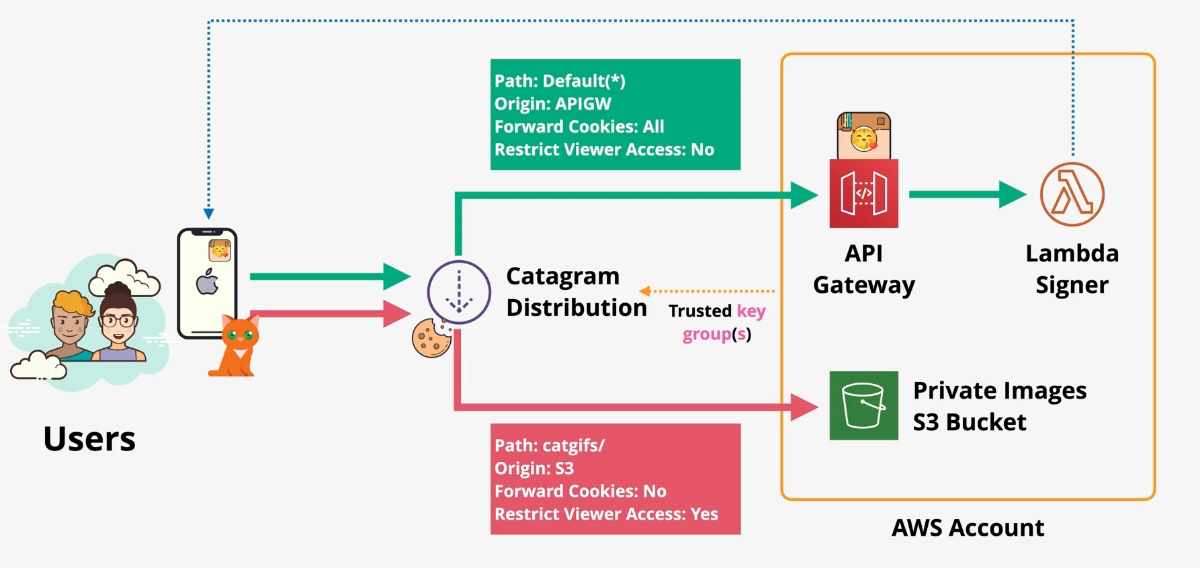
Lambda@Edge
Lambda@Edge allows cloudfront to run lambda function at CloudFront edge locations to modify traffic between the viewer and edge location and edge locations and origins.
- You can run lightweight Lambda at edge locations
- Adjust data between the viewer and origin
- Currently supports Node.js and Python
- Run in the AWS Public Space (Not VPC)
- Layers are not supported
- Different limits vs normal Lambda functions
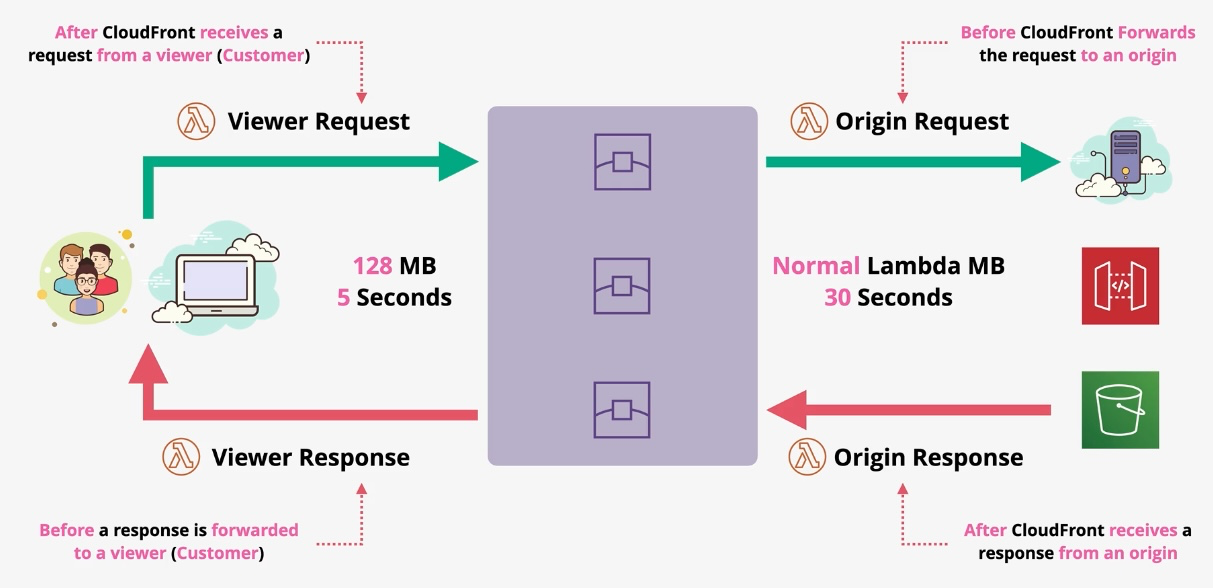
Lambda@Edge Use Cases
- A/B testing - Viewer Request
- Modify image URL
- Migration between S3 Origins - Origin Request
- Different Object based on Device - Origin Request
- Content by Country - Origin Request
AWS Global Accelerator
AWS Global Accelerator is designed to improve global network performance by offering entry point onto the global AWS transit network as close to customers as possible using ANycast IP addresses
The Problem
- Starts in one area, grows popular and then receive lots of users from far-off locations
- Latency
- Multiple “hops”
- Low quality connection
Global Accelerator
- ❗When to use CF and when to use GA
- 2x anycast IP Addresses
- 1.2.3.4 & 4.3.2.1
- Anycast IPs allow a single IP to be in multiple locations. Routing moves traffic to closest location
- Traffic initially uses public internet and enters a Global Accelerator edge location
- From the edge, data transits globally across the AWS global backbone network. Less hops, directly under AWS control, significantly better performance
Key Concepts
- Moves the AWS network closer to customers
- Connections enter at edge using anycast IPs
- Transit over AWS backbone to 1+ locations
- Can be used for NON hTTP/S (TCP/UDP) - DIFFERENCE FROM CLOUDFRONT
🪐 ADVANCED VPC Networking
VPC Flow Logs
VPC Flow logs is a feature allowing the monitoring of traffic flow to and from interfaces within a VPC
VPC Flow logs can be added at a VPC, Subnet or Interface level.
Flow Logs DON'T monitor packet contents ... that requires a packet sniffer.
Flow Logs can be stored on S3 or CloudWatch Logs
- Capture metadata (not content)
- Source/dest IP, ports, protocol, action (e.g. ACCEPT), etc…
- Attached to a VPC/Subnet/ENI - All ENIs in that VPC
- Subnet - All ENIs in that subnet
- ENIs directly
- Flow Logs are NOT realtime
- Log Destinations - S3 or CloudWatch Logs
- Or Athena for querying
Architecture
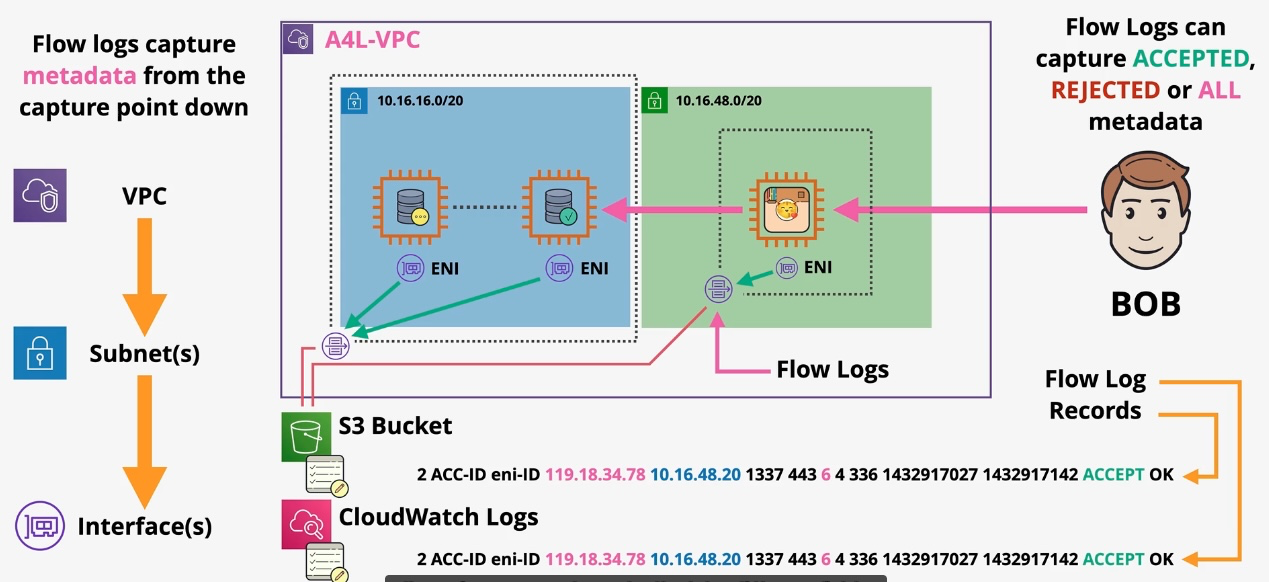
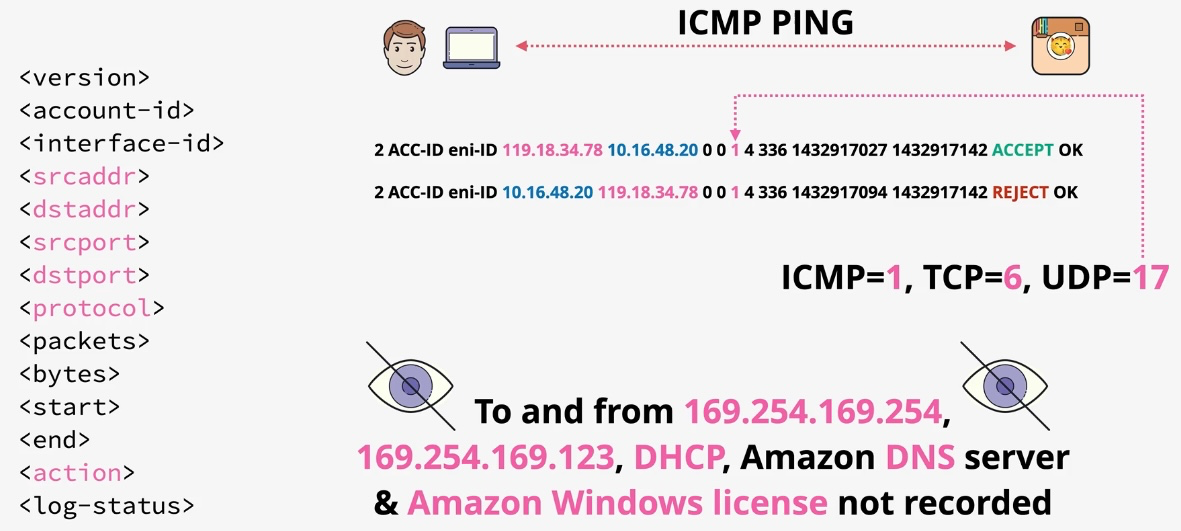
Egress-Only Internet Gateway
Egress-Only internet gateways allow outbound (and response) only access to the public AWS services and Public Internet for IPv6 enabled instances or other VPC based services.
- With IPv4 addresses are private or public
- NAT allows private IPs to access public networks
- without allowing externally initiated connections (IN)
- With IPv6 all IPs are public
- Internet Gateway (IPv6) allows all IPs IN and OUT
- Egress-Only is outbound-only for IPv6
Architecture
VPC Endpoints (Gateway)
Gateway endpoints are a type of VPC endpoint which allow access to S3 and DynamoDB without using public addressing.
Gateway endpoints add 'prefix lists' to route table, allowing the VPC router to direct traffic flow to the public services via the gateway endpoint.
- Provide private access to S3 and DynamoDB
- Prefix List added to route table → Gateway Endpoint
- Highly Available across all AZs in a region by default
- Endpoint policy is used to control what it can access
- Regional - can’t access cross-region services
- Prevent Leaky Buckets - S3 Buckets can be set to private only by allowing access ONLY from a gateway endpoint

Architecture
VPC Endpoints (Interface)
Interface endpoints are used to allow private IP addressing to access public AWS services.
S3 and DynamoDB are handled by gateway endpoints - other supported services are handled by interface endpoints.
Unlike gateway endpoints - interface endpoints are not highly available by default - they are normal VPC network interfaces and should be placed 1 per AZ to ensure full HA.
- Provide private access to AWS Public Services
- Historically anything NOT S3 and DDB - but S3 is now supported
- Added to specific subnets - an ENI - not HA
- For HA - add one endpoint, to one subnet, per AZ used in the VPC
- Network access controlled via Security Groups
- Endpoint Policies - restrict what can be done with the endpoint
- TCP and IPv4 Only
- Uses PrivateLink
- Interface endpoints use DNS
- Endpoint provides a NEW service endpoint DNS
- e.g. vpce-123-xyz.sns.us-east-1.vpce.amazonaws.com
- Endpoint regional DNS
- Endpoint Zonal DNS
- Applications can optionally use these or
- PrivateDNS overrides the default DNS for services
Architecture
VPC Peering
VPC peering is a software define and logical networking connection between two VPC's
They can be created between VPCs in the same or different accounts and the same or different regions.
In this lesson I step through the architectural key points which you'll need to understand for the exam and real world usage.
- Direct encrypted network link between two VPCs (ONLY TWO!)
- Works same/cross-region and same/cross-account
- Optional: Public hostnames resolve to private IPs
- Same region SG’s can reference peer SG’s
- VPC Peering does NOT support transitive peering
- If A→B and B→C, NOT A→C
- Routing configuration is needed, SG’s & NACLs can filter
Architecture
🏞️ Hybrid Environments and Migration
Border Gateway Protocol 101
This lesson provides a high level introduction to the Border Gateway Protocol (BGP) which is used by some AWS services such as Direct Connect and Dynamic Site to Site VPNs.
- Autonomous System (AS) - Routers controlled by one entity - a network in BGP
- ASN are unique and allocated by IANA (0-65535), 64512-65534 are private
- BGP operates over tcp/179 - it’s reliable
- Not automatic - peering is manually configured
- BGP is a path-vector protocol it exchanges the best path to a destination between peers - the path is called the ASPATH
- iBGP = Internal BGP - Routing within an AS
- eBGP = External BGP - Routing between AS
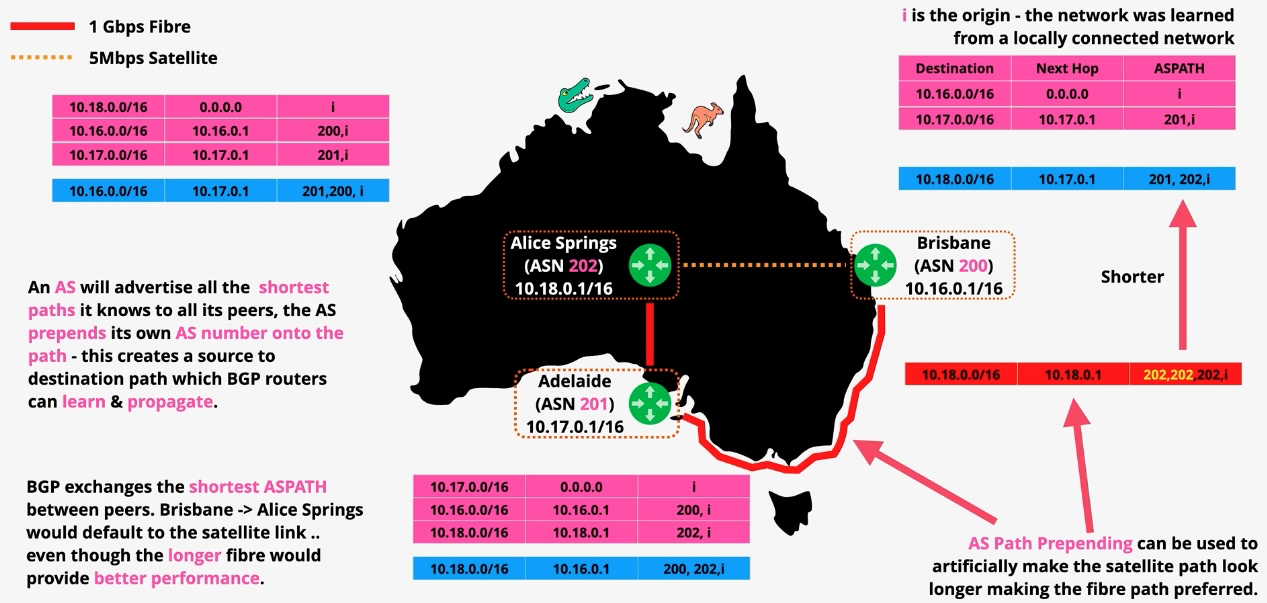
IPSec VPN Fundamentals
IPsec VPN negotiation occurs in two phases. In Phase 1, participants establish a secure channel in which to negotiate the IPsec security association (SA). In Phase 2, participants negotiate the IPsec SA for authenticating traffic that will flow through the tunnel.
- IPSEC is a group of protocols
- It sets up secure tunnels across insecure networks between two peers (local and remote)
- Provides authentication and encryption
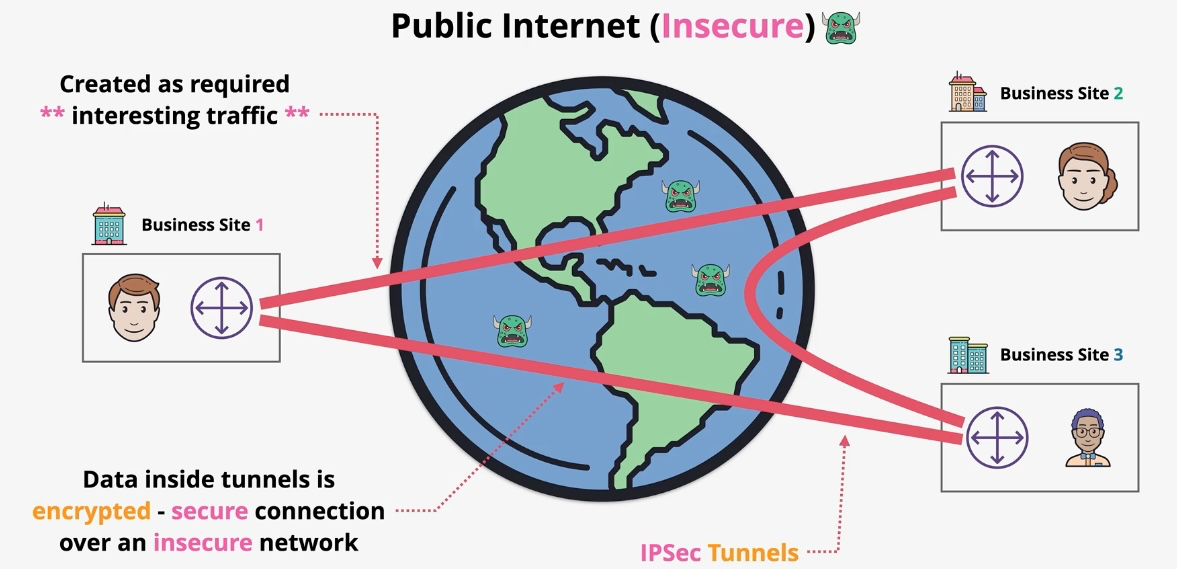
- Remember - symmetric encryption is fast, but it’s a challenge to exchange keys securely
- Asymmetric encryption is slow, but you can easily exchange public keys
- IPSEC har two main phases
- IKE PHASE 1 (Slow and heavy)
- Authenticate: Pre-shared key (password) / cert
- Using asymmetric encryption to agree on, and create a shared symmetric key
- IKE SA Created (phase 1 tunnel)
- IKE PHASE 2 (Fast and agile)
- Uses the keys agreed in phase 1
- Agree encryption method, and keys used for bulk data transfer
- Create IPSEC SA - phase 2 tunnel (architecturally running over phase 1)
- IKE PHASE 1 (Slow and heavy)
Policy-Based VPNs
- Rele sets match traffic → a pair of SAa
- Different rules/security settings
Route-Based VPNs
- Target matching (prefix)
- Matches a single pair of SA’a
IKE Phase 1 Architecture
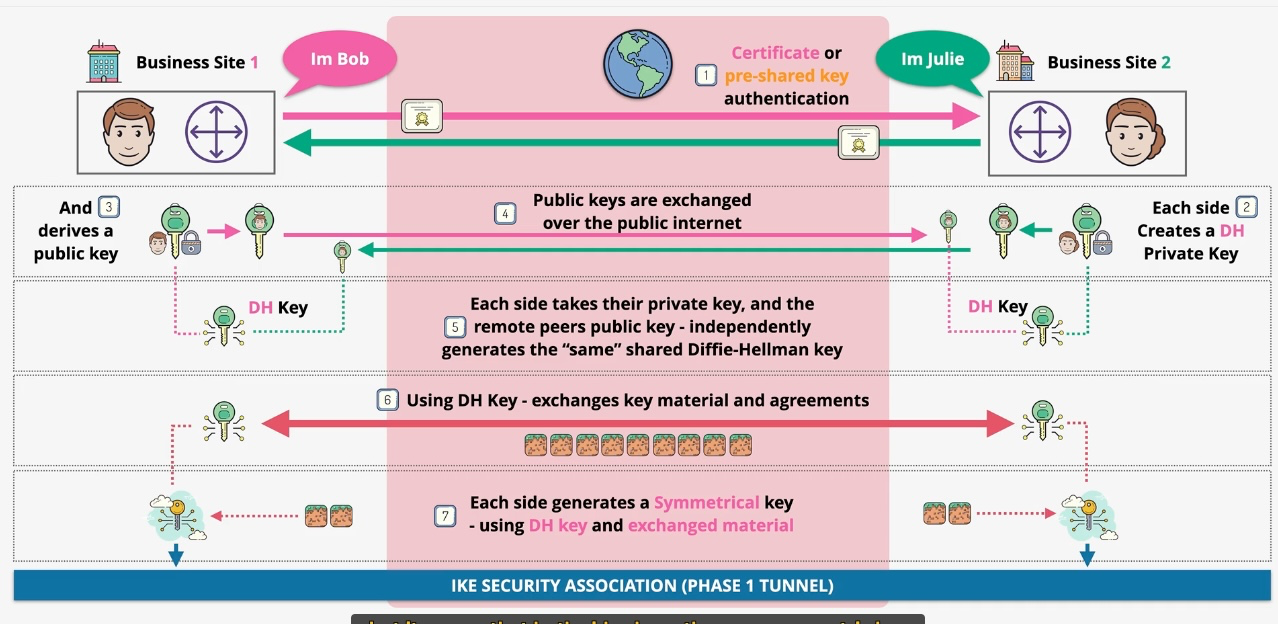
IKE Phase 2 Architecture
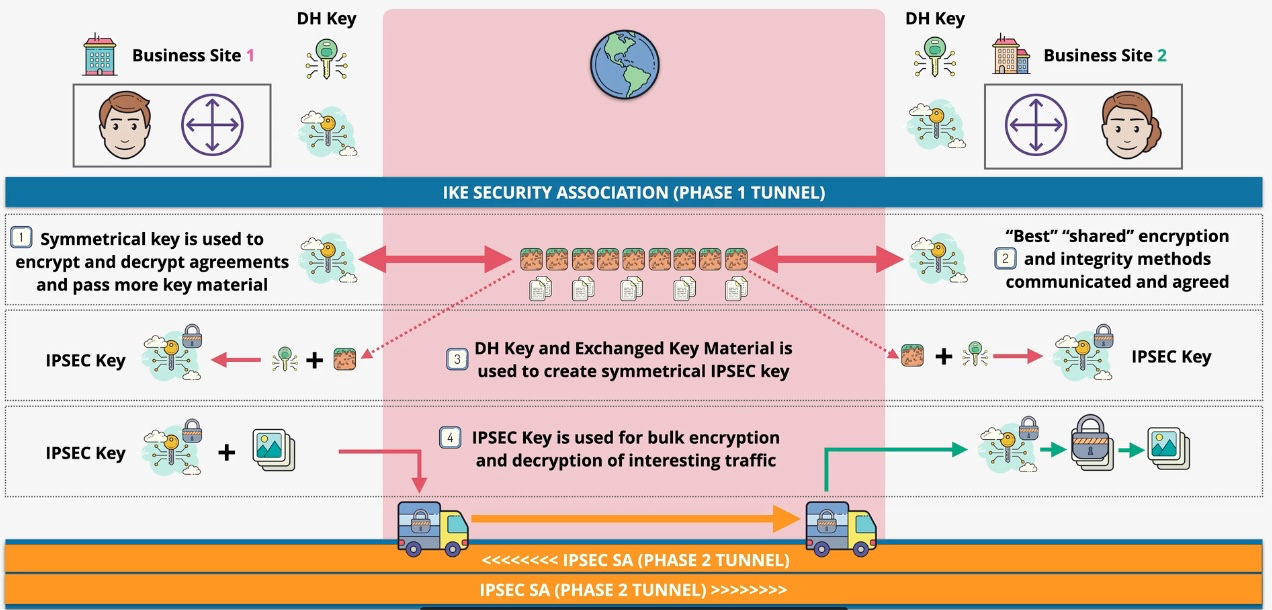
Route vs Policy Based
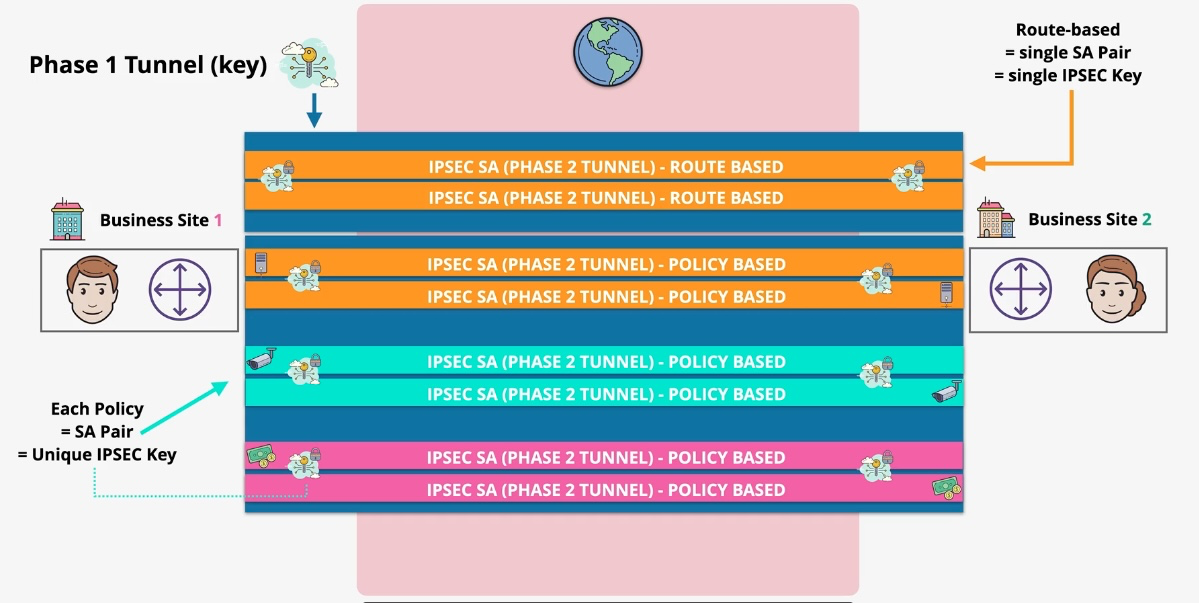
AWS Site-to-Site VPN
AWS Site-to-Site VPN is a hardware VPN solution which creates a highly available IPSEC VPN between an AWS VPN and external network such as on-premises traditional networks. VPNs are quick to setup vs direct connect, don't offer the same high performance, but do encrypt data in transit.
- A logical connection between a VPC and on-premises network encrypted using IPSec, running over the public internet
- Full HA - if you design and implement it correctly
- ❗Quick to provision - less than an hour!
- Virtual Private Gateway (VGW)
- Customer Gateway (CGW)
- VPN Connection between the VGW and CGW
VPN Considerations
- Speed Limitations ~1.25 Gbps
- Latency - inconsistent, public internet
- Cost - AWS hourly cost, GB out cost, data cap (on premises)
- Speed of setup - hours - all software configuration
- Can be used as a backup for Direct Connect (DX)
- Can be used with Direct Connect
Static vs Dynamic VPN (BGP)
- Dynamic VPN uses BGP
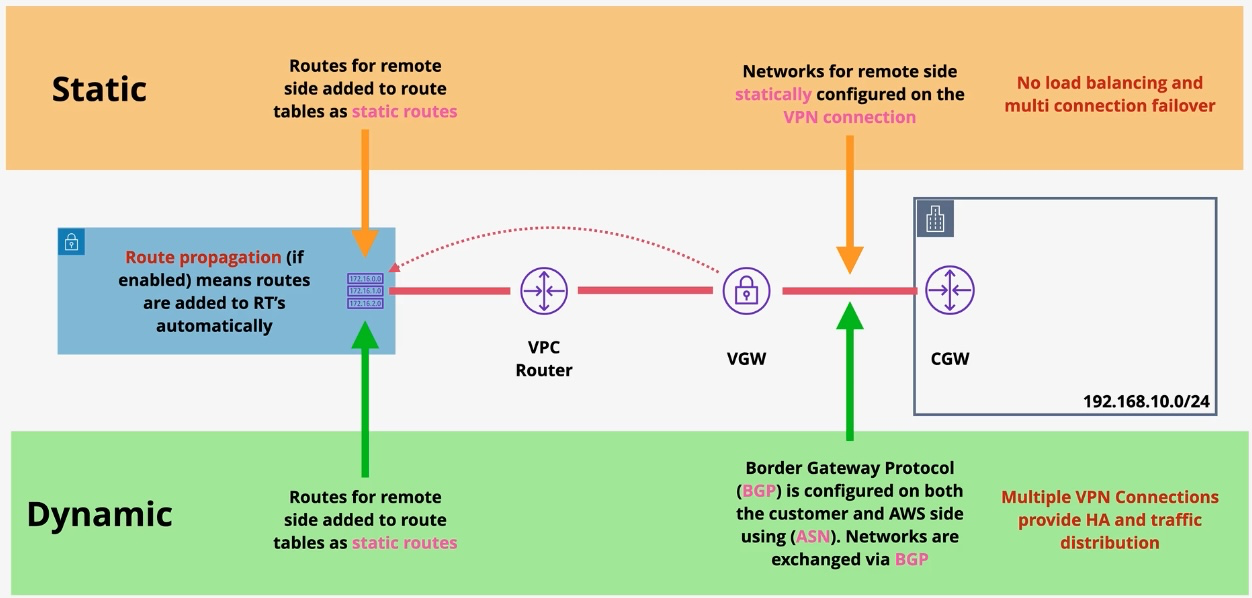
Architecture Partial HA
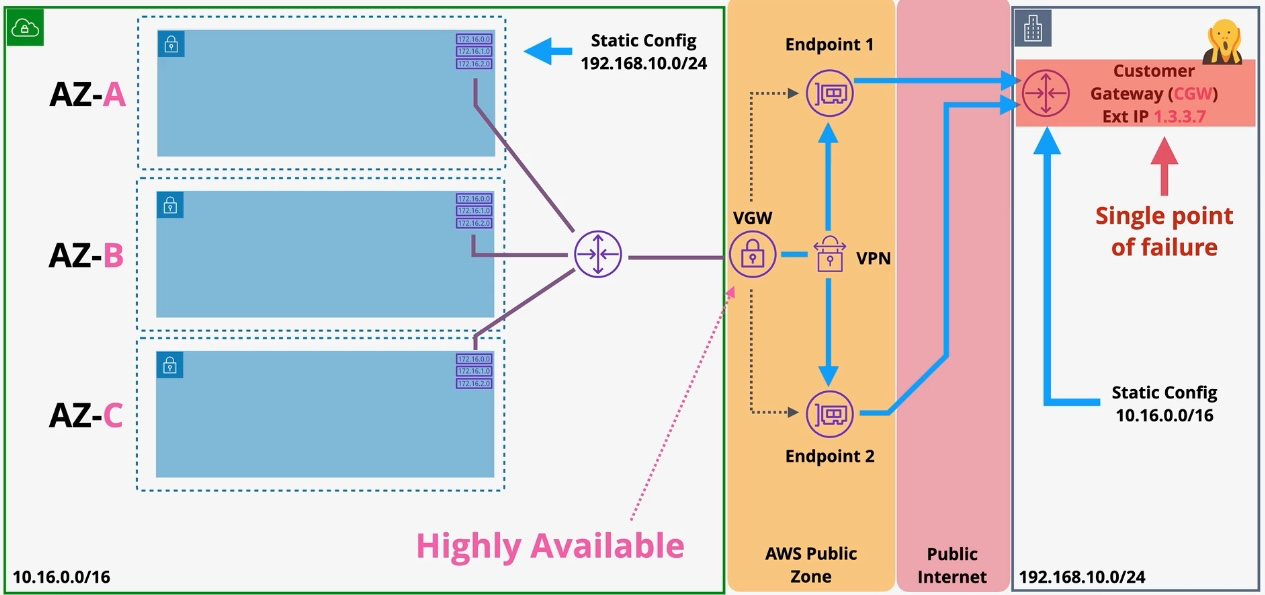
Architecture HA
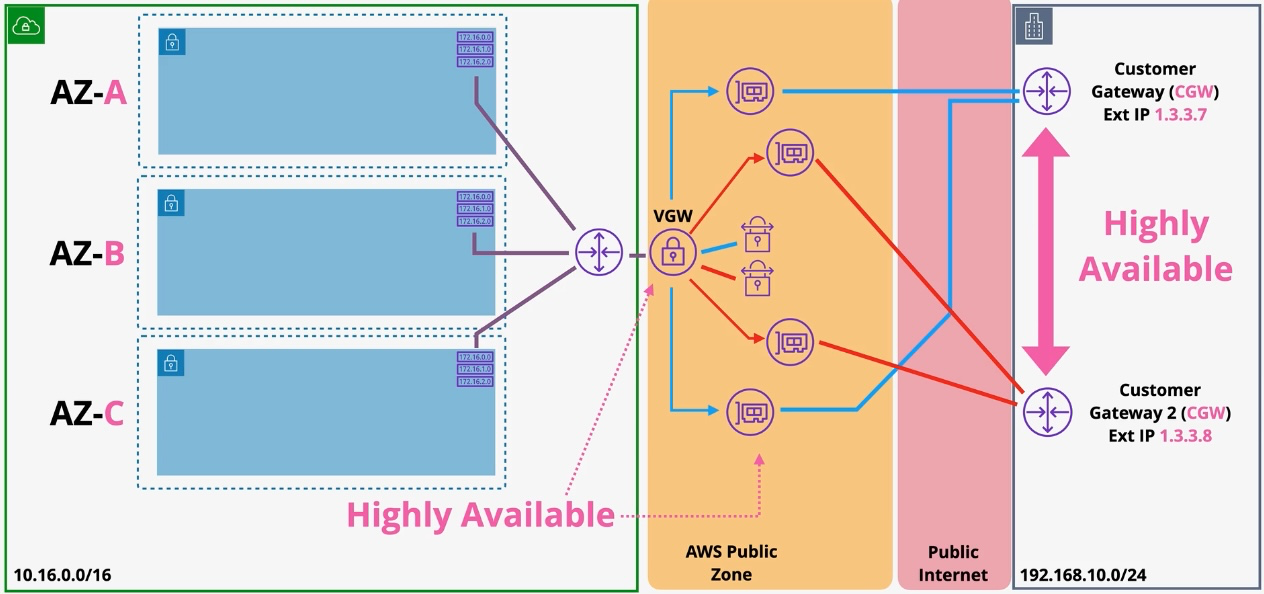
Direct Connect (DX) Concepts
AWS Direct Connect links your internal network to an AWS Direct Connect location over a standard Ethernet fiber-optic cable. One end of the cable is connected to your router, the other to an AWS Direct Connect router. With this connection, you can create virtual interfaces directly to public AWS services (for example, to Amazon S3) or to Amazon VPC, bypassing internet service providers in your network path. An AWS Direct Connect location provides access to AWS in the Region with which it is associated. You can use a single connection in a public Region or AWS GovCloud (US) to access public AWS services in all other public Regions.
- A physical connection (1, 10 or 100 Gbps)
- Business Premises → DX Location → AWS Region
- Port Allocation at a DX Location
- Port hourly cost & outbound data transfer (inbound is free of charge)
- Provisioning time - physical cables & no resilience
- Low & consistent latency + High speeds ⚡
- AWS Private Services (VPCs) and AWS Public Services - NO INTERNET
- ❗DX is NOT ENCRYPTED ❗
DX Architecture
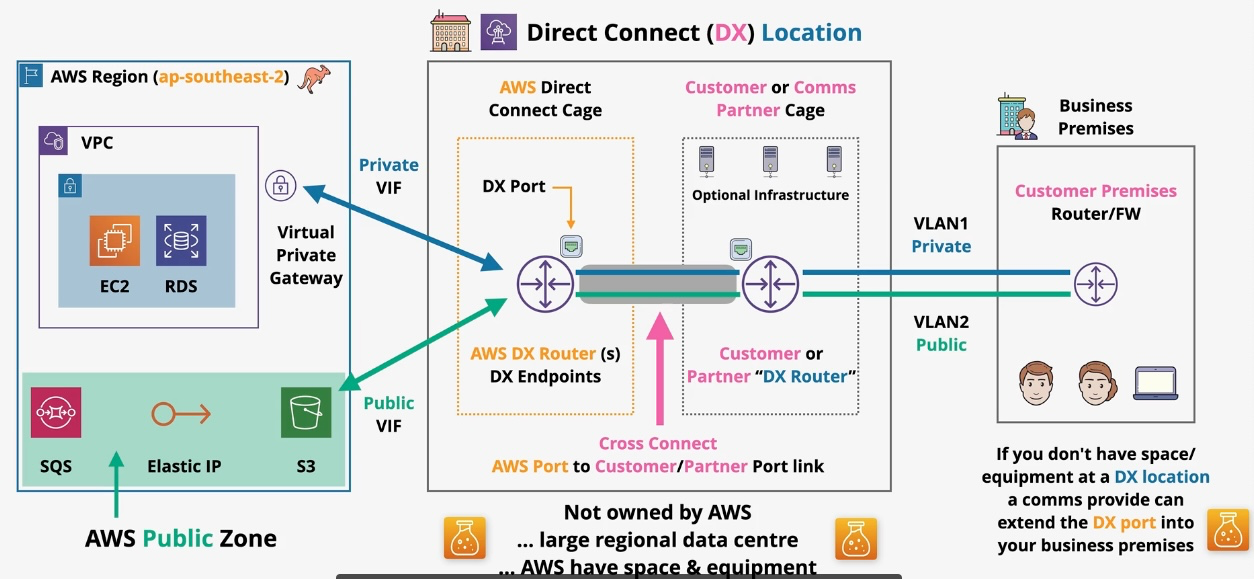
Direct Connect (DX) Resilience
This lesson steps through the architecture of a few resilient implementations of direct connect, starting with an overview of why the default implementation architecture of direct connect provides no resilience.
💡 DX is a physical technology!
Good
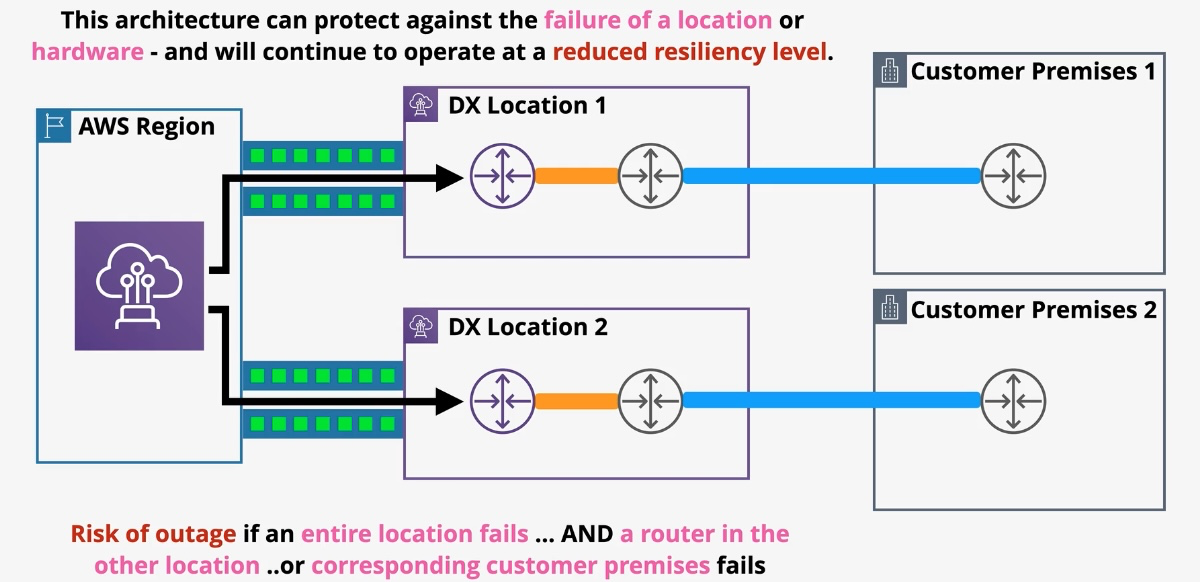
GREAT
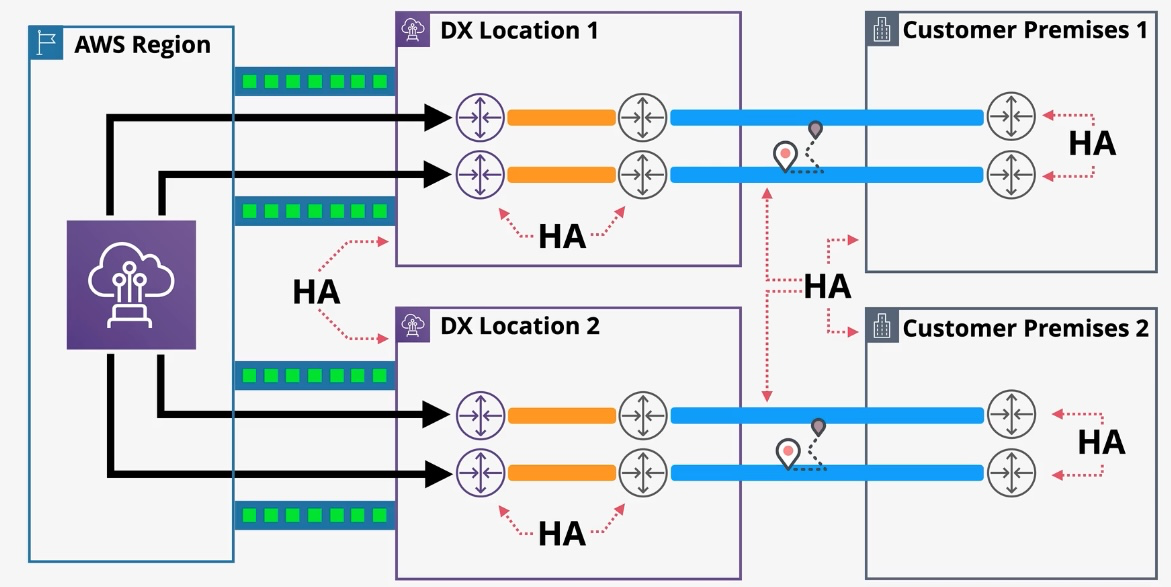
AWS Transit Gateway (TGW)
The AWS Transit gateway is a network gateway which can be used to significantly simplify networking between VPC's, VPN and Direct Connect.
It can be used to peer VPCs in the same account, different account, same or different region and supports transitive routing between networks.
- Network Transit Hub to connect VPCs to on premises networks
- Significantly reduces network complexity
- Single network object - HA and Scalable
- Attachments to other network types
- VPC, Site-to-Site VPN & Direct Connect Gateway
TGW Considerations
- ❗Supports transitive routing!
- Can be used to create global networks
- Share between accounts using AWS RAM
- Peer with different regions - same or cross account
- Less complexity vs without TGW
Architecture
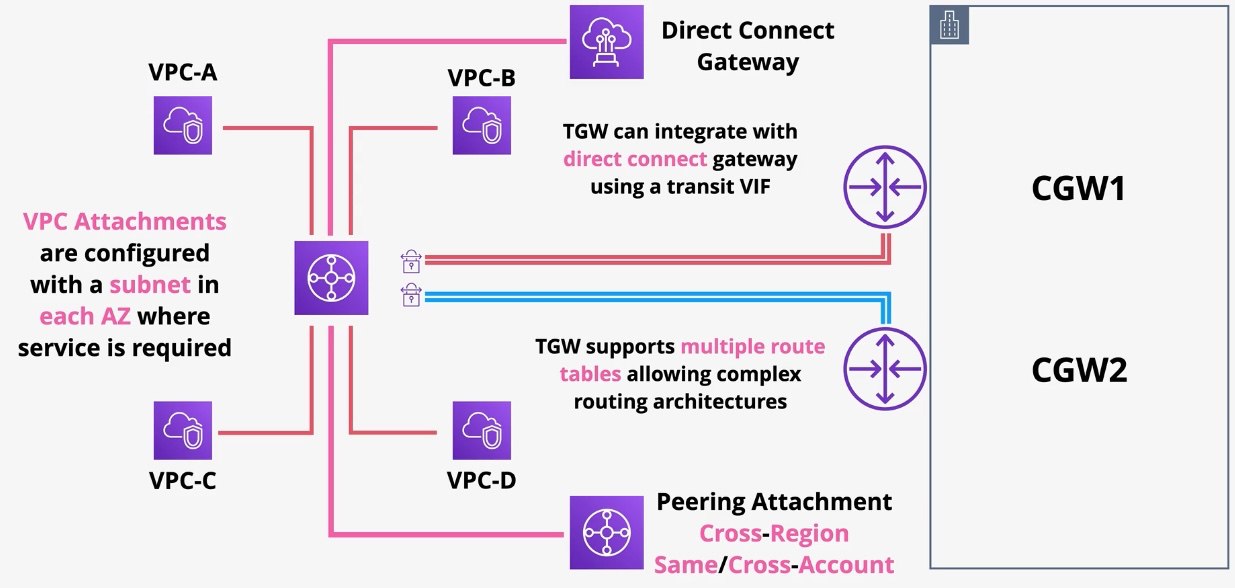
Storage Gateway - Volume
Storage gateway is a product which integrates local infrastructure and AWS storage such as S3, EBS Snapshots and Glacier.
- Virtual machine (or hardware appliance)
- Presents storage using iSCSI, NFS or SMB
- Integrates with EBS, S3 and Glacier within AWS
- Migrations, extensions, storage tiering, DR and replacement of backup systems
- For the exam: Picking the right mode
Storage GW Volume: Stored
- Primary location of data is on-prem
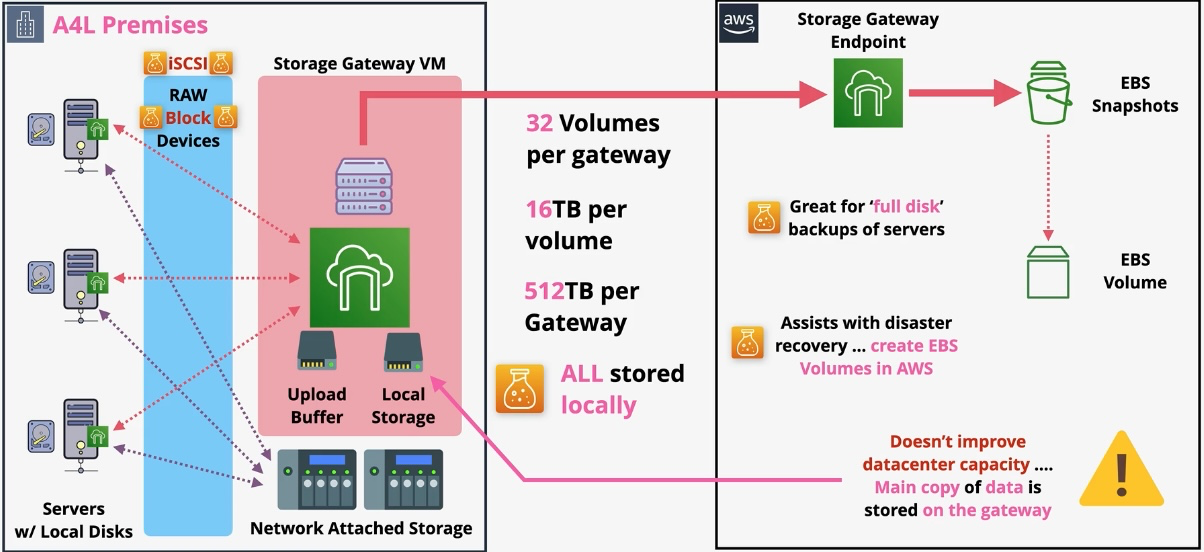
Storage GW Volume: Cached
- Primary location of data is AWS (S3)
Storage Gateway Tape - VTL Mode
Storage gateway in VTL mode allows the product to replace a tape based backup solution with one which uses S3 and Glacier rather than physical tape media.
- Large backups → Tape
- LTO-9 Media can hold 24TB Raw data (up to 60GB compressed)
- 1 tape drive can use 1 tape at a time
- Loaders (Robots) can swap tapes
- A library is 1+ drive(s), 1+ loader(s) and slots
- Drive - library - shelf (anywhere but the library)
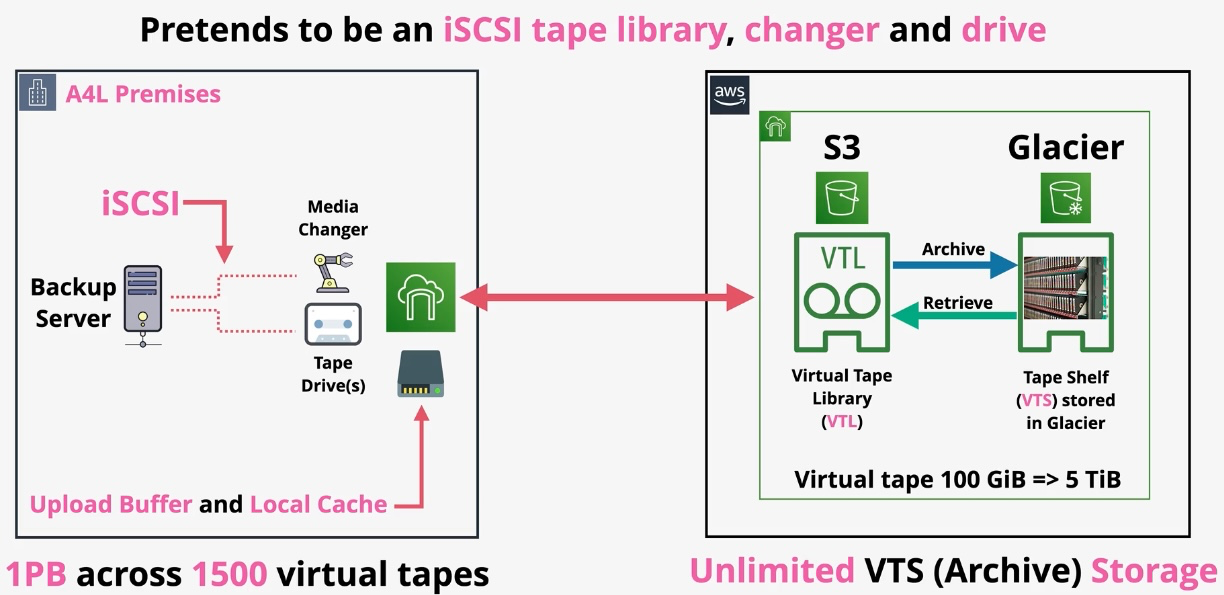
Storage Gateway - File Mode
File gateway bridges local file storage over NFS and SMB with S3 Storage.
It supports multi site, maintains storage structure, integrates with other AWS products and supports S3 object lifecycle Management
- Bridges on-premises file storage and S3
- Mount Points (shares) available via NFS or SMB
- Map directly onto an S3 bucket
- Files stored into a mount point, are visible as objects in an S3 bucket
- Read and Write Caching ensure LAN-like performance
Architecture: Two-side
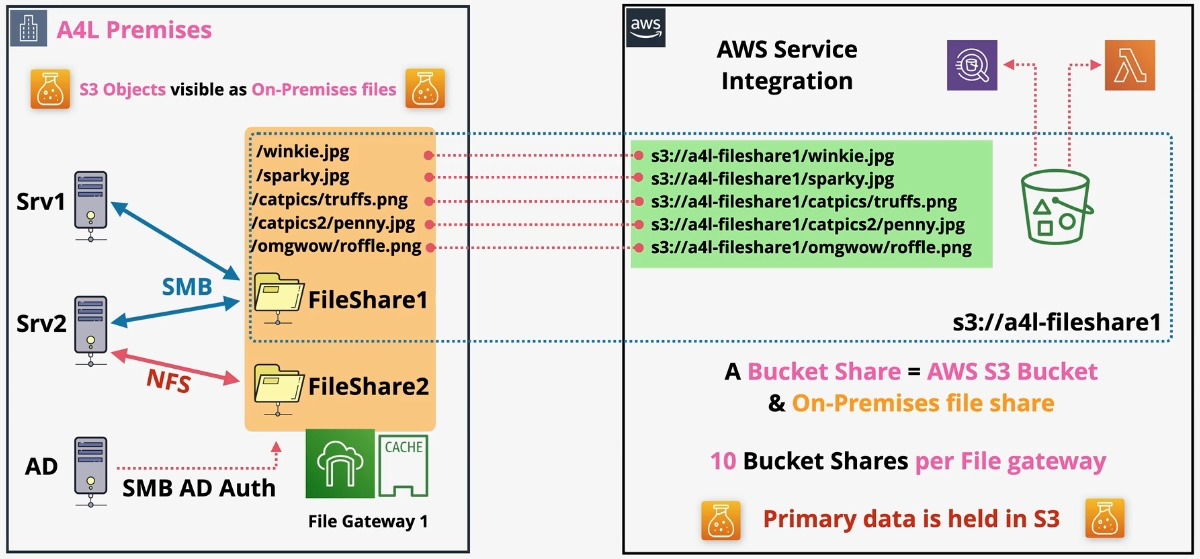
Architecture: Multiple Contributors
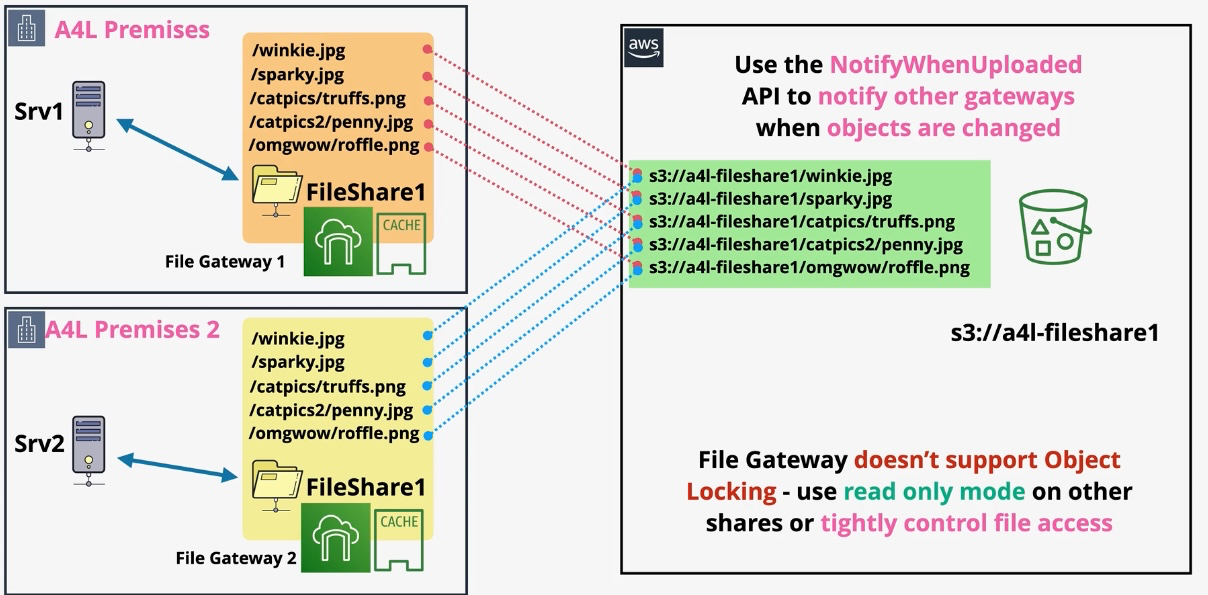
Architecture: Multiple Contributors and Replication
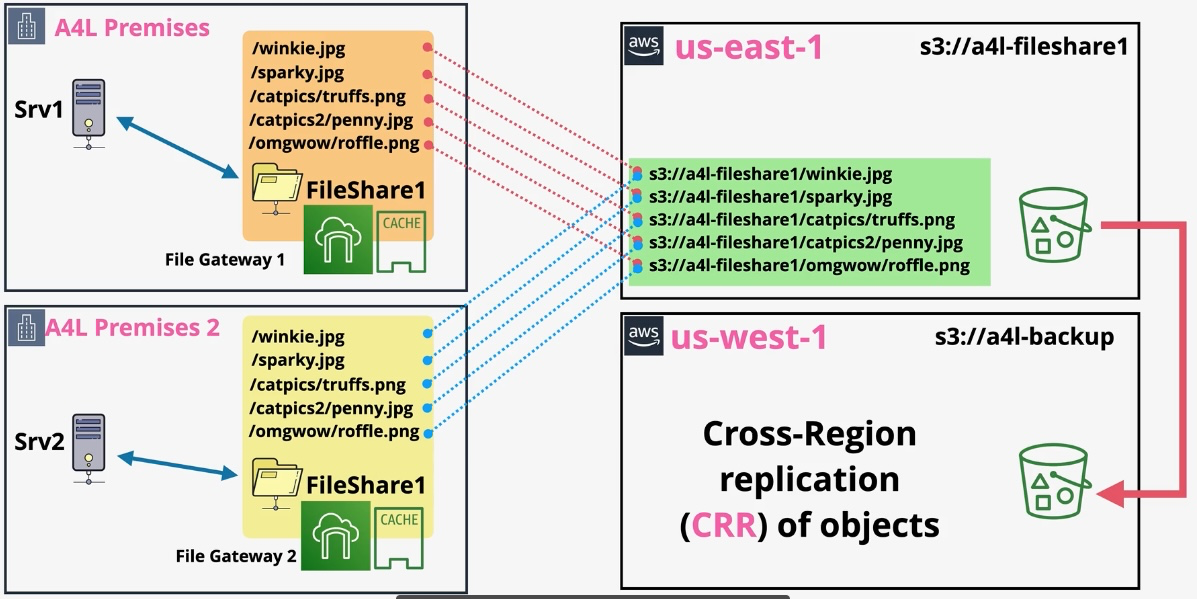
Snowball & Snowmobile
Snowball, Snowball Edge and Snowmobile are three parts of the same product family designed to allow the physical transfer of data between business locations and AWS.
Key Concepts
- Move large amount of data IN & OUT of AWS
- Physical storage - suitcase or truck
- Ordered from AWS Empty, Load up, Return
- Ordered from AWS with data, empty & Return
- For exam: Which to use!
Snowball
- Ordered from AWS, Log a Job, Device Delivered (not instant)
- Data Encryption uses KMS
- 50TB or 80TB capacity
- 1 Gbps (RJ45 GBase-TX) or 10Gbps (LR/SR) Network
- 10TB to 10PB economical range (multiple devices)❗
- Multiple devices to multiple premises ❗
- Only storage ❗
Snowball Edge
- Both storage and compute ❗
- Larger capacity vs Snowball
- 10Gbps (RJ45), 10/25 (SFP), 45/50,100 Gbps (QSFP+)
- Storage Optimized (with EC2) - 80TB, 24 vCPU, 32 Gib RAM, 1TB SSD
- Compute Optimized - 100TB + 7.68 NVME, 52 vCPU and 208 GiB RAM
- Compute with GPU - As above - with GPU!
- Ideal for remote sites or where data processing on ingestion is needed
Snowmobile
- Portable DC within a shipping container on a truck ❗
- Special order
- Ideal for single location when 10PB+ is required ❗
- Up to 100PB per snowmobile
- Not economical for multi-site (unless huge) or sub 10PB ❗
- LITERALLY A TRUCK
AWS Directory Service
The Directory service is a product which provides managed directory service instances within AWS
it functions in three modes
- Simple AD - An implementation of Samba 4 (compatibility with basics AD functions)
- AWS Managed Microsoft AD - An actual Microsoft AD DS Implementation
- AD Connector which proxies requests back to an on-premises directory.
What’s a Directory?
- Stores objects (e.g. Users, Groups, Computers, Servers, File Shares) with a structure (domain/tree)
- Multiple trees can be grouped into a forest
- Commonly used in Windows Environments
- Sign-in to multiple devices with the same username/password provides centralized management for assets
- Microsoft Active Directory Domain Services (AD DS)
- AF FD most popular, open-source alternatives (SAMBA)
What is Directory Service?
- AWS Managed implementation
- Runs within a VPC
- To implement HA - deploy into multiple AZs
- Some AWS services NEED a directory, e.g. Amazon Workspaces
- Can be isolated or integrated with existing on-premises system
- Or act as a proxy back to on-premises
Simple AD Mode Architecture
- Simple AD ↔ SAMBA 4
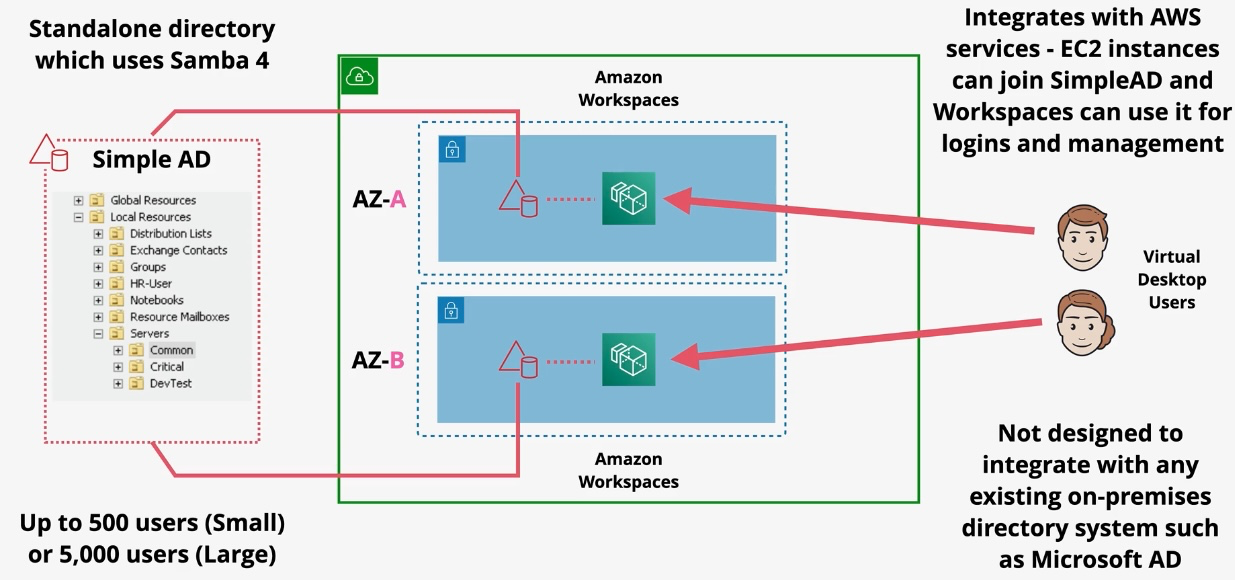
AWS Managed Microsoft AD Architecture
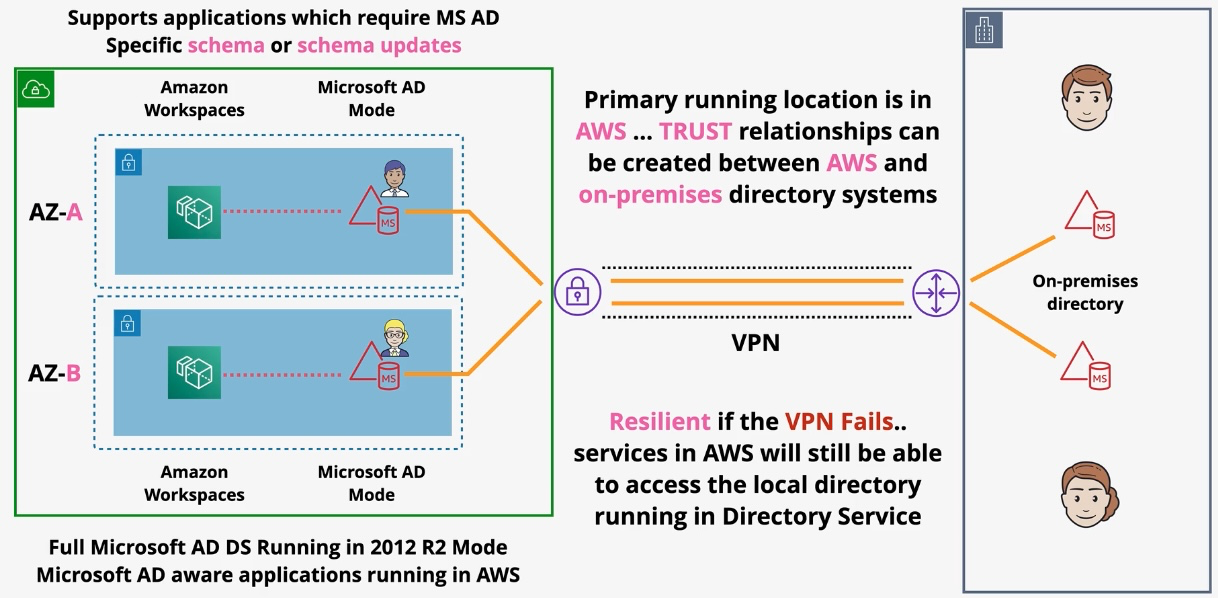
AD Connector Architecture
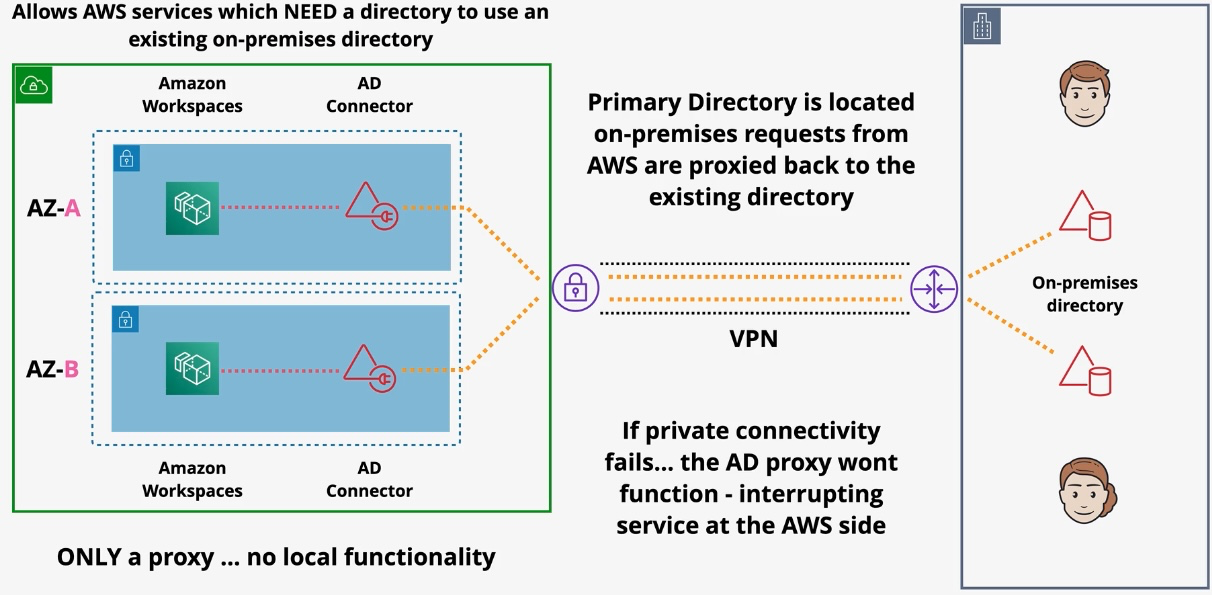
Picking Between Modes
- ❗ Simple AD should be default ❗
- Microsoft AD - Applications in AWS which need MS AD DS, or you need to TRUST AD DS
- AD Connector - Use AWS Services which need a directory without storing any directory info in the cloud - proxy to your on-premises Directory
AWS DataSync
AWS DataSync is a product which can orchestrate the movement of large scale data (amounts or files) from on-premises NAS/SAN into AWS or vice-versa
- Data Transfer service TO/FROM AWS
- Migrations, Data Processing Transfers, Archival/Cost Effective Storage or DR/BC
- Designed to work at huge scale
- Keeps metadata (e.g. permissions/timestamps)
- Built in data validation
Key Features
- Scalable - 10Gbps per agent (~100TB per day)
- Bandwidth Limiters (avoid link saturation)
- Incremental and scheduled transfer options
- Compression and encryption
- Automatic recovery from transit errors
- AWS Service integration - S3, EFS, FSx
- Pay as you use - per GB cost for data moved
Architecture
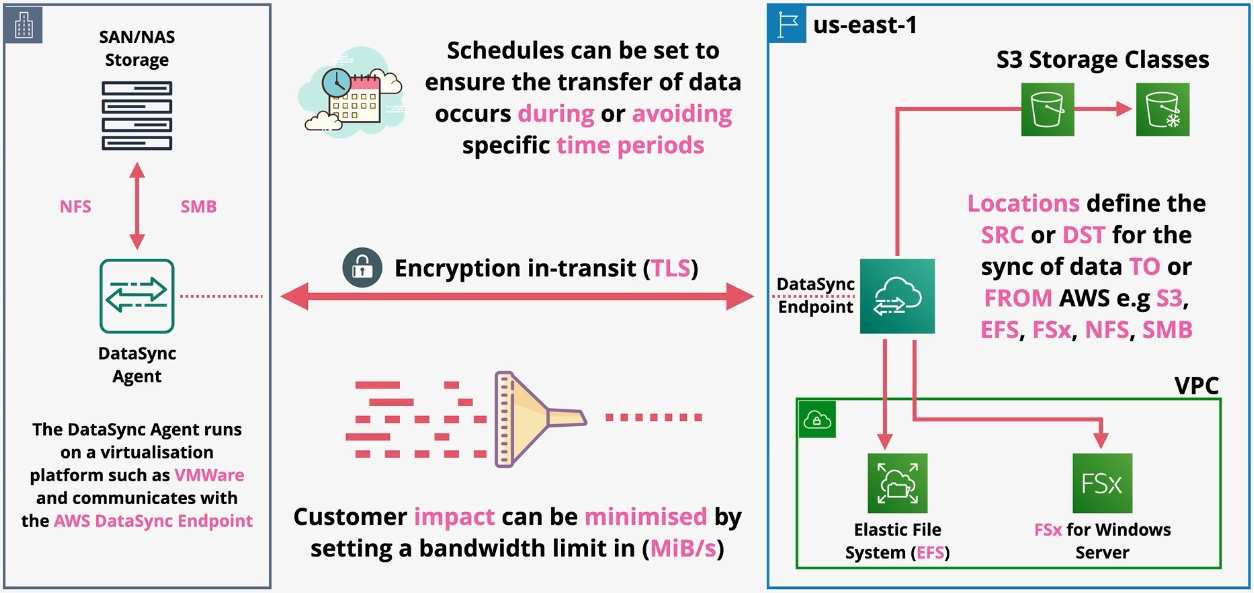
DataSync Components
- Task - A “job” within DataSync. Defines what is being synced, how quickly, FROM where and TO where
- Agent - Software used to read/write to on-premises data stores using NFS or SMB
- Location - every task has two locations (TO/FROM). E.g. NFS, Server Message Block (SMB), Amazon EFS, Amazon FSx and S3
FSx for Windows File Server
FSx for Windows Servers provides a native windows file system as a service which can be used within AWS, or from on-premises environments via VPN or Direct Connect
FSx is an advanced shared file system accessible over SMB, and integrates with Active Directory (either managed, or self-hosted).
It provides advanced features such as VSS, Data de-duplication, backups, encryption at rest and forced encryption in transit.
- Fully managed native windows file servers/shares
- Designed for integration with windows environments
- Integrates with Directory Service or Self-Managed AD
- Single or Multi-AZ within a VPC
- On-demand and Scheduled backups
- Accessible using VPC, Peering, VPN, Direct Connect
- ❗Exam job: When to use FSx and when to use EFS ❗
Architecture
FSx Key Features and Benefits
- VSS: User-Driven Restores
- ❗Native file system accessible over SMB ❗
- ❗Windows permission model❗
- Supports DFS - scale-out file share structure
- Managed - no file server admin
- ❗Integrates with DS AND your own directory ❗
FSx for Lustre
FSx for Lustre is a managed file system which uses the FSx product designed for high performance computing
It delivers extreme performance for scenarios such as Big Data, Machine Learning and Financial Modeling
- Managed Lustre - Designed for HPC - Linux clients (POSIX)
- Machine Learning, Big Data, Financial Modeling
- 100’s GB/s throughput and sub millisecond latency
- Deployment types: Persistent or Scratch
- Scratch: Highly optimized for short term no replication & fast
- Persistent: Longer term, HA (in one AZ), self-healing
- Accessible over VPN or Direct Connect
- Metadata stored on Metadata Targets (MST)
- Objects are stored on called object storage target s(OSTs) (1.17TiB)
- Baseline performance based on size
- Size - min 1.2TiB then increments of 2.4TiB
- For Scratch: Base 200 MB/s per TiB of storage
- Persistent offers 50 MB/s, 100MB/s and 200 MB/s per TiB of storage
- Burst up to 1300 MB/s per TiB (credit system)
Key Points
- Scratch is designed for pure performance
- Short term or temp workloads
- NO HA - NO REPLICATION
- Larger file systems means more servers, more disks and more chance of failure
- Persistent has replication within ONE AZ only
- Auto-heals when hardware failure occurs
- You can backup to S3 with BOTH (manual or automatic 0-35 day retention)
- ❗SMB/Windows → FSx for Windows ❗
- ❗POSIX / High Performance → FSx for Lustre ❗
Conceptually
Architecture
AWS Transfer Family
AWS Transfer Family is a secure transfer service that enables you to transfer files into and out of AWS storage services.
AWS Transfer Family supports transferring data from or to the following AWS storage services.
- Amazon Simple Storage Service (Amazon S3) storage.
- Amazon Elastic File System (Amazon EFS) Network File System (NFS) file systems.
AWS Transfer Family supports transferring data over the following protocols:
- Secure Shell (SSH) File Transfer Protocol (SFTP)
- File Transfer Protocol Secure (FTPS)
- File Transfer Protocol (FTP)
- Applicability Statement 2 (AS2)
- Managed file transfer service - Supports transferring TO or FROM S3 and EFS
- Provides managed “servers” which supports protocols
- File Transfer Protocol (FTP) - Unencrypted file transfer - Legacy
- FTPS - FTP with TLS
- Secure Shell (SSH) File Transfer Protocol (SFTP) File transfer over SSH
- Applicability Statement 2 (AS2) - Structured B2B Data
- Identities - Service managed, directory service, custom (Lambda/APIGW)
- Managed File Transfer Workflows (MFTW) - serverless file workflow engine
- Multi-AZ: Resilient and Scalable
- Provisioned Server per hours + data transferred
- FTP and FTPS - Directory Service or Custom IDP only
- FTP - VPC only (cannot be public)
- AS2 VPC Internet/internal Only
- If you need to access S3/EFS, but with existing protocols
- integrating with existing workflow
- or using MFTW to create new ones
Architecture
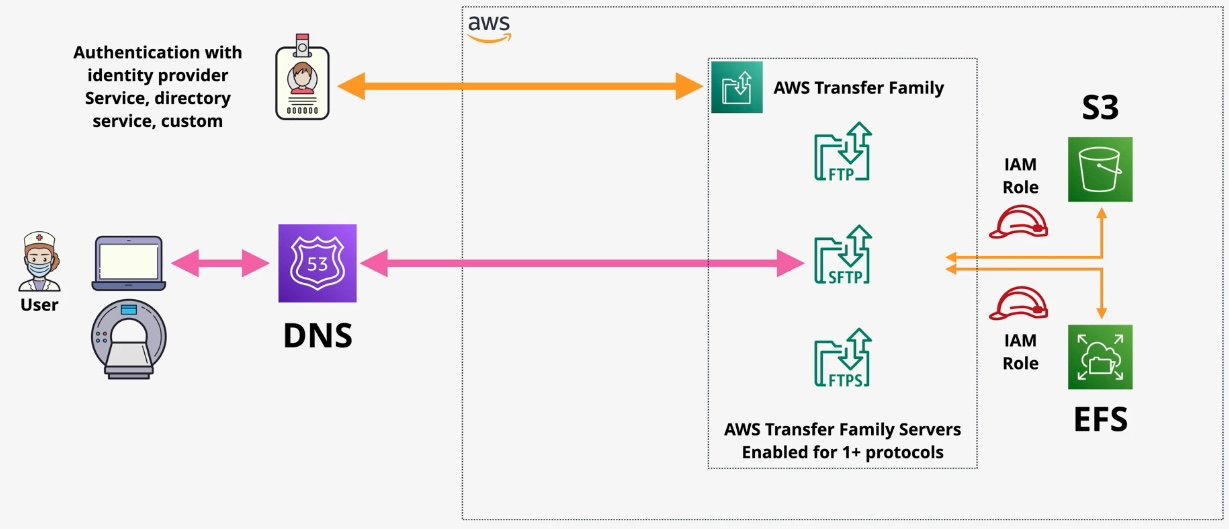
Endpoint Type
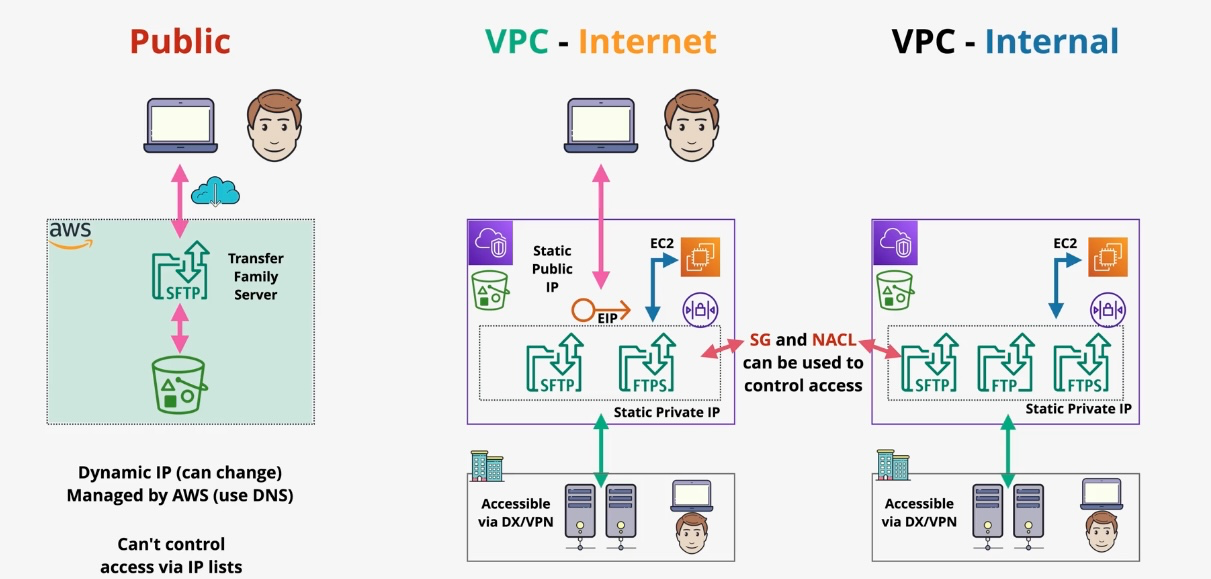
🔐 Security, Deployment & Operations
AWS Secrets Manager
AWS Secrets manager is a product which can manage secrets within AWS. There is some overlap between it and the SSM Parameter Store - but Secrets manager is specialised for secrets.
Additionally Secrets managed is capable of automatic credential rotation using Lambda.
For supported services it can even adjust the credentials of the service itself.
- It does share functionality with Paramter Store
- ❗Designed for **secrets (passwords, API KEYS…)**❗
- Usable via console, CLI, API or SDK’s (integration)
- ❗Supports automatic rotation - this uses Lambda❗
- ❗Directly integrates with some AWS Products (RDS)❗
💡 RDS, integration, secrets or rotation → Secrets Manager > Parameter Store!
Architecture
Application Layer (L7) Firewall
Application Layer, known as Layer 7 or L7 firewalls are capable of inspecting, filtering and even adjusting data up to Layer 7 of the OSI model. They have visibility of the data inside a L7 connection. For HTTP this means content, headers, DNS names .. for SMTP this would mean visibility of email metadata and for plaintext emails the contents.
Normal Firewalls (Layer 3/4/5)
Application (Layer 7) Firewalls
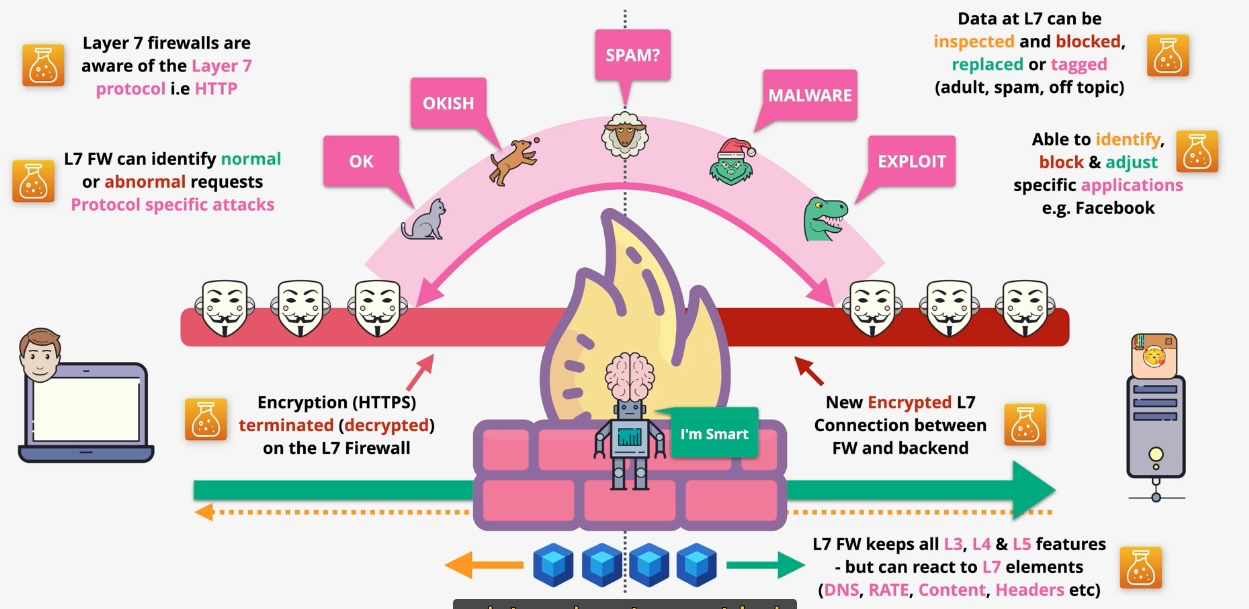
Web Application Firewall (WAF)
AWS WAF is a web application firewall that helps protect your web applications or APIs against common web exploits and bots that may affect availability, compromise security, or consume excessive resources.
- AWS Layer 7 Firewall
Architecture
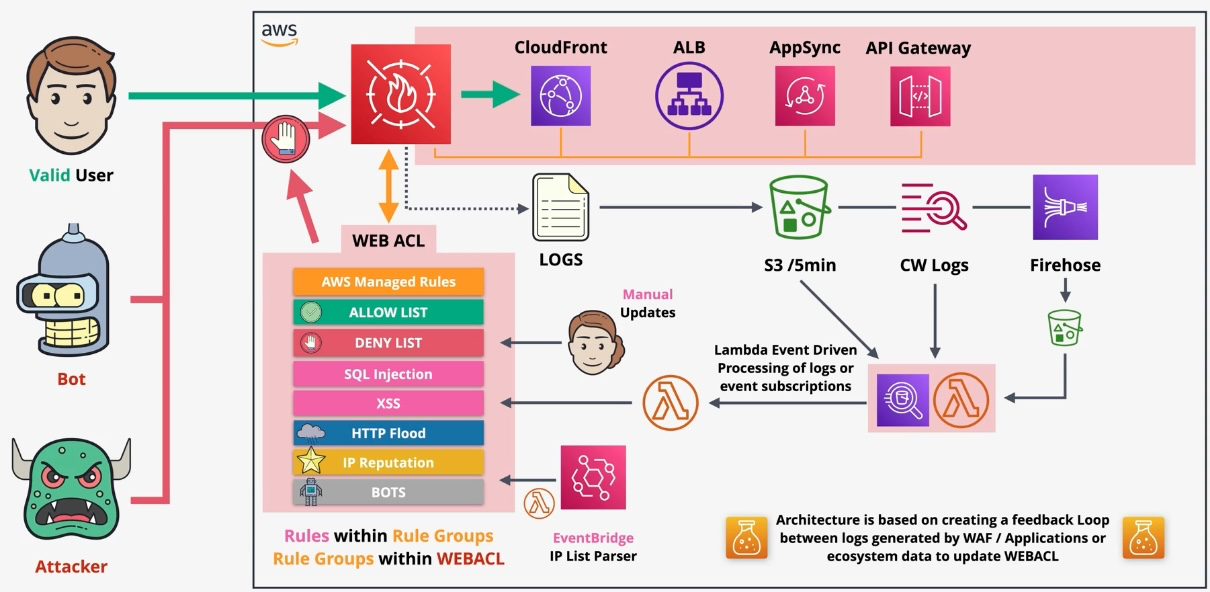
Web Access Control lists (WEBACL)
- WEBACL Default Action (ALLOW or BLOCK) - Non matching
- Resource Type - CloudFront or Regional Service (ALB, AP GW, AppSync)
- Add Rule Groups or Rules - processed in order
- Web ACL Capacity Units (WCU) - Default 1500
- can be increased via support ticket
- WEBACL’s are associated with resources (this can take time)
- adjusting a WEBACL takes less time than associating one
Rule Groups
- Rule groups contain rules
- They don’t have default actions - that’s defined when groups or rules are added to WEBACLs
- Managed (AWS or Marketplace), Yours, Service Owned (i.e Shield & Firewall Manager)
- Rule Groups can be referenced by multiple WEBACL
- Have a WCU capacity (defined upfront, max 1500*)
WAF Rules
- Type, Statement, Action
- Type:
- Regular
- Rate-Based
- Statement:
- (WHAT to match)
- or (Count ALL)
- or (WHAT & COUNT)
- origin country, IP, label, header, cookies, query parameter, URI path, query string, body (first 8292 bytes only), HTTP method
- Single, AND, OR, NOT
- Action: ALLOW, BLOCK, COUNT, CAPTCHA -* Custom Response (x-amzn-waf-), Label
- Labels can be referenced later in the same WEBACL - multi-stage flows
- ALLOW and BLOCK stop processing, Count/Captcha actions continue
Pricing
- WEBACL - Monthly ($5 month) (remember can be reused)
- RULE on WEBACL - Monthly ($1 /month*)
- REQUESTS per WEBACL - Monthly ($0.60 / 1 million*)
- Intelligent Threat Mitigation
- Bot Control - $10/month & $1/1mil reqs
- Captcha - $0.40 / 1000 challenge attempts
- Fraud control/account takeover ($10 month) & $1 / 1000 login attempts
- Marketplace Rule Groups - Extra costs
AWS Shield
AWS Shield is a managed Distributed Denial of Service (DDoS) protection service that safeguards applications running on AWS. AWS Shield provides always-on detection and automatic inline mitigations that minimize application downtime and latency, so there is no need to engage AWS Support to benefit from DDoS protection.
- AWS Shield Standard & Advanced — DDOS Protection ❗
- Shield Standard is free - Advanced has a cost
- Network Volumetric Attacks (L3) - Saturate Capacity
- Network Protocol Attacks (L4) - TCP SYN Flood
- Leave connections open, prevent new ones
- L4 can also have volumetric component
- Application Layer Attacks (L7) - e.g. web request floods
- query.php?search=all_the_cat_images_ever
Shield Standard
- Free for AWS Customers
- protection at the perimeter
- region/VPC or the AWS edge
- Common Network (L3) or Transport (L4) layer attacks
- Best protection using R53, CloudFront and AWS Global Accelerator
AWS Shield Advanced
- $3000 per month (per ORG), 1 year lock-in + data (OUT) / month
- Protects CF, R53, Global Accelerator, Anything Associated with EIPs (EC2), ALBs, CLBs, NLBs
- Not automatic - must be explicitly enabled in Shield Advanced or AWS Firewall Manager Shield Advanced policy
- Cost protection (i.e. EC2 scaling) for unmitigated attacks
- Proactive engagement & AWS Shield Response Team (SRT)
- WAF Integration - includes basic AWS WAF fees for web ACLs, rules and web requests
- Application Layer (L7) DDOS protection (uses WAF)
- Real time visibility of DDOS events and attacks
- Health-based detection - application specific health checks, used by proactive engagement team
- Protection groups
CloudHSM
CloudHSM is required to achieve compliance with certain security standards such as FIPS 140-2 Level 3
- With KMS - AWS Manage - Shared but separated
- ❗Security concern: Shared Service❗
- True “Single Tenant” Hardware Security Module (HSM)
- ❗AWS provisioned - fully customer managed❗
- ❗FIPS 140-2 Level 3 (KMS is L2 overall, some L3)❗
- Industry Standard APIs - PKCS#11, Java Cryptography Extensions (JCE), Microsoft CryptoNG (CNG) libraries
- KMS can use CloudHSM as a custom key store, CloudHSM integration with KMS
Architecture
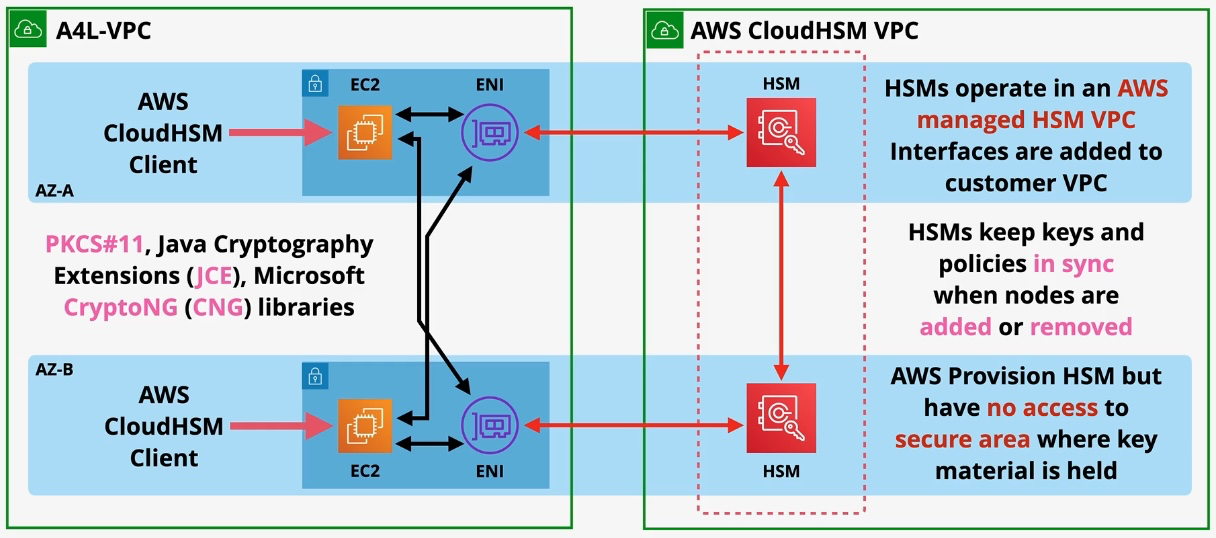
CloudHSM Use Cases
- No native AWS integration - e.g. no S3 SSE
- Offload the SSL/TLS processing for web servers
- Enable Transparent Data Encryption (TDE) for Oracle Databases
- Protect the Private Keys for an Issuing Certificate Authority (CA)
AWS Config
AWS Config is a service which records the configuration of resources over time (configuration items) into configuration histories.
All the information is stored regionally in an S3 config bucket.
AWS Config is capable of checking for compliance .. and generating notifications and events based on compliance.
- Record configuration changes over time on resources
- Auditing of changes, compliance with standards
- Does not prevent changes happening - no protection
- Regional Service - supports cross-region and account aggregation
- Changes can generate SNS notifications and near-real time events via EventBridge & Lambda
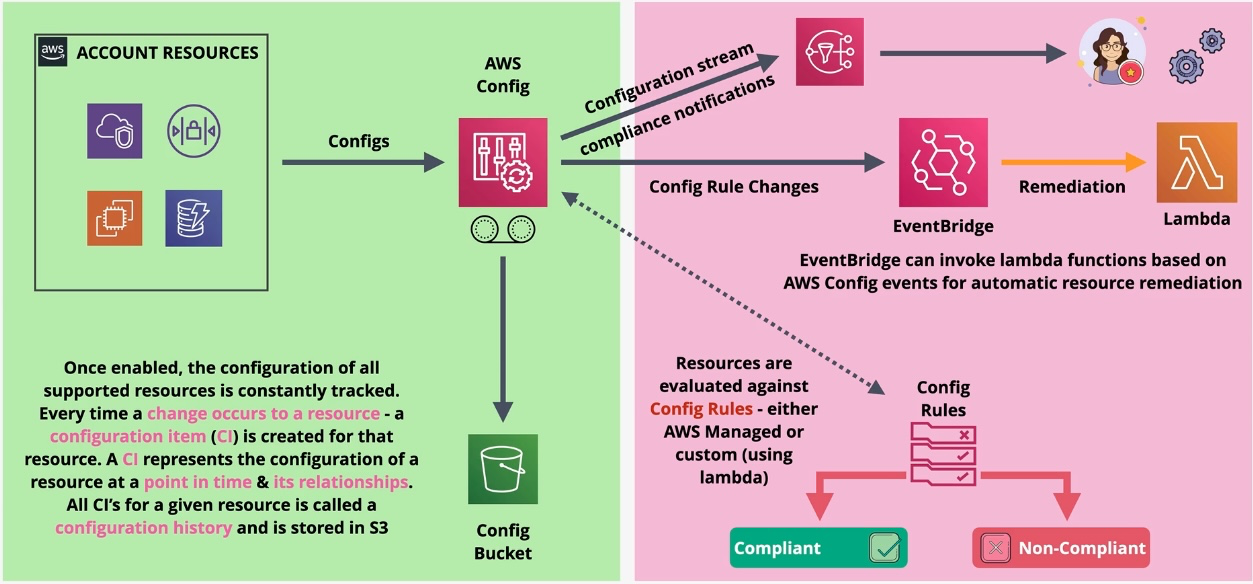
Amazon Macie
Amazon Macie is a fully managed data security and data privacy service that uses machine learning and pattern matching to discover and protect your sensitive data in AWS.
- Data Security and Data Privacy Service
- Discover, Monitor and Protect data - stored in S3 buckets
- Automated discovery of data, i.e. PII, PHI, Finance
- Managed Data Identifiers - Built-in - ML/Patterns
- Custom Data Identifiers - Proprietary - Regex Based
- Integrates - With Security Hub & “finding events” to EventBridge
- Centrally manage - either via AWS ORG or one Macie Account Inviting
Architecture
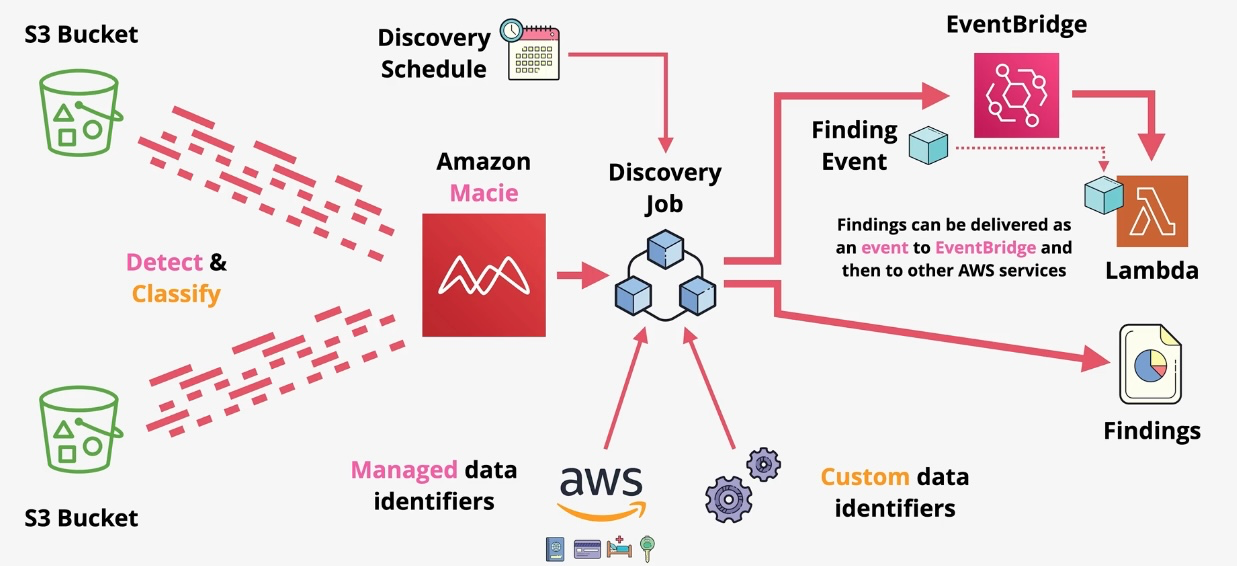
Identifiers
- Managed data identifiers - maintained by AWS
- growing list of common sensitive data types
- credentials, finance, health, personal identifiers
- Custom data identifiers - created by you
- Regex
- Maximum Match Distance - how close keywords are to regex pattern
- Ignore words - if regex match contains ignore words, it’s ignored
Findings
- Policy findings or sensitive data findings
- Policy: E.g. public access to s3 bucket
- Sensitive data: credentials, financial etc
Amazon Inspector
Amazon Inspector is an automated security assessment service that helps improve the security and compliance of applications deployed on AWS. Amazon Inspector automatically assesses applications for exposure, vulnerabilities, and deviations from best practices
- Scans EC2 instances & the instance OS
- also containers
- Vulnerabilities and deviations against best practice
- Length - 15min, 1 hour, 8/12 hours or 1 day
- Provides a report of findings ordered by priority
- Network Assessment (Agentless)
- Network & Host Assessment (Agent)
- Rules packages determine what is checked
- Network Reachability (no agent required)
- Agent can provided additional os visibility
- Check reachability end to end. EC2, ALB, DX, ELB, ENI, IGW, ACLs, RT’s, SG’s, Subnets, VPCs, VGWs and VPC Peering
- RecognizedPortWithListener, RecognizedPortNoListener, UnRecognizedPortWithListener
- Packages (Host assessments, agent required)
- Common vulnerabilities and exposures (CVE)
- Center for Internet Security (CIS) Benchmarks
- Security best practices for Amazon Inspector
Amazon GuardDuty
Guard Duty is an automatic threat detection service which reviews data from supported services and attempts to identify any events outside of the 'norm' for a given AWS account or Accounts.
- Continuous security monitoring service
- Analyses supported Data Sources
- plus AI/ML, plus threat intelligence feeds
- Identifies unexpected and unauthorized activity
- Notify or event-driven protection/remediation
- Supports multiple accounts (MASTER and MEMBER)
Architecture
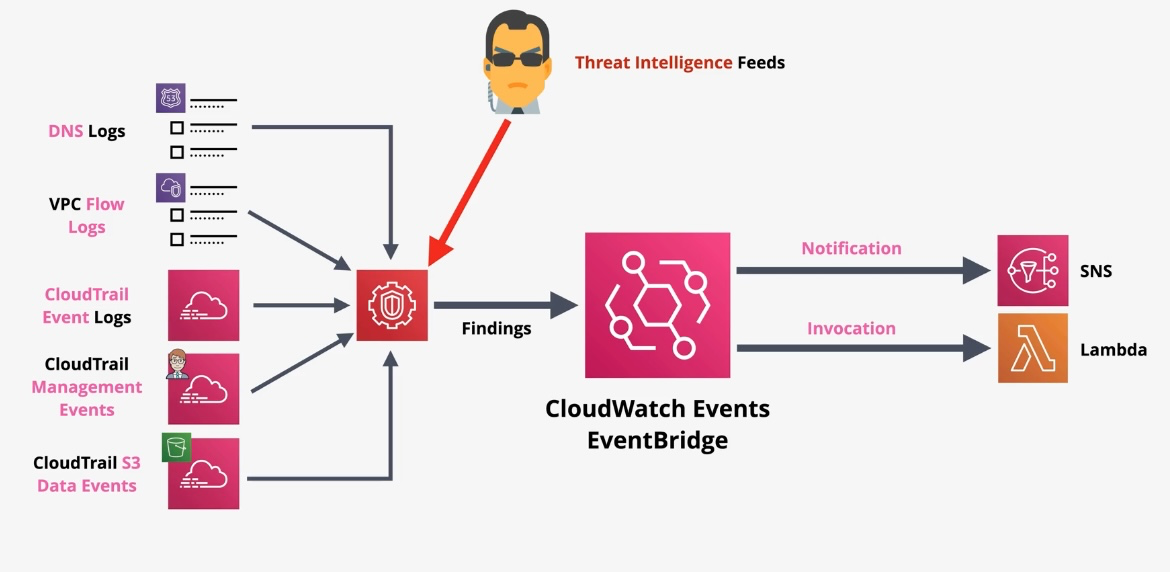
🏢🧑💻 Infrastructure as Code (CloudFormation)
Physical & Logical Resources
CloudFormation defines logical resources within templates (using YAML or JSON). The logical resource defines the WHAT, and leaves the HOW up to the CFN product. A CFN stack creates a physical resource for every logical resource - updating or deleting them as a template changes.
- CF Template - YAML or JSON
- Contains logical resources - the WHAT
- Templates are used to create stacks
- Can create one or multiple
- Stacks create physical resources from the logical
- If a stacks template is change physical resources are changed
- If a stack is deleted, normally, the physical resources are deleted
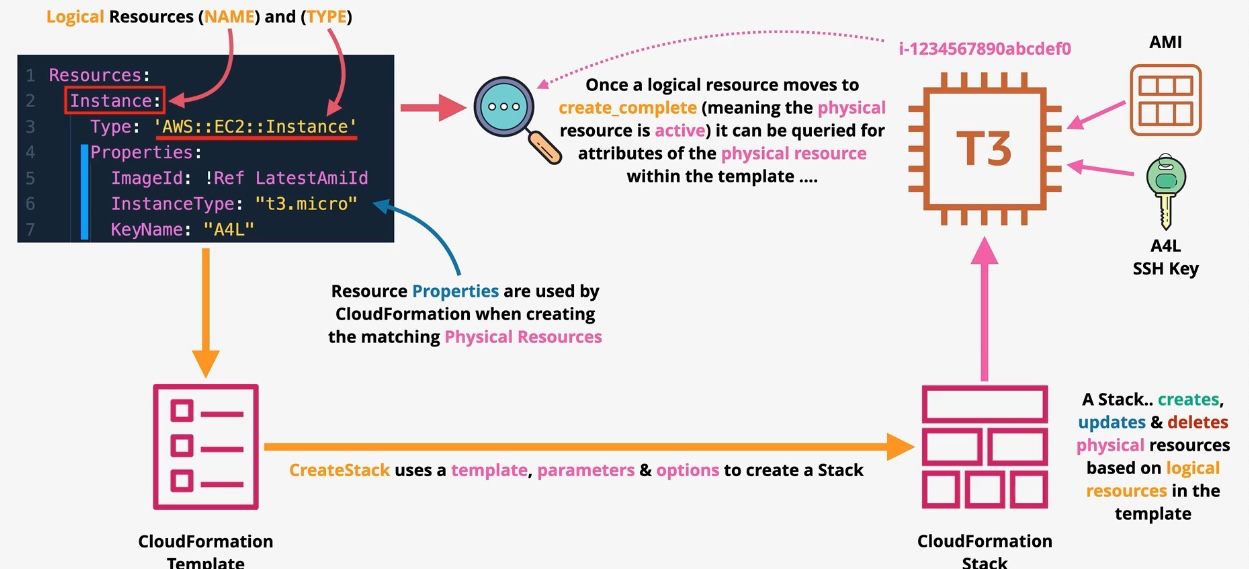
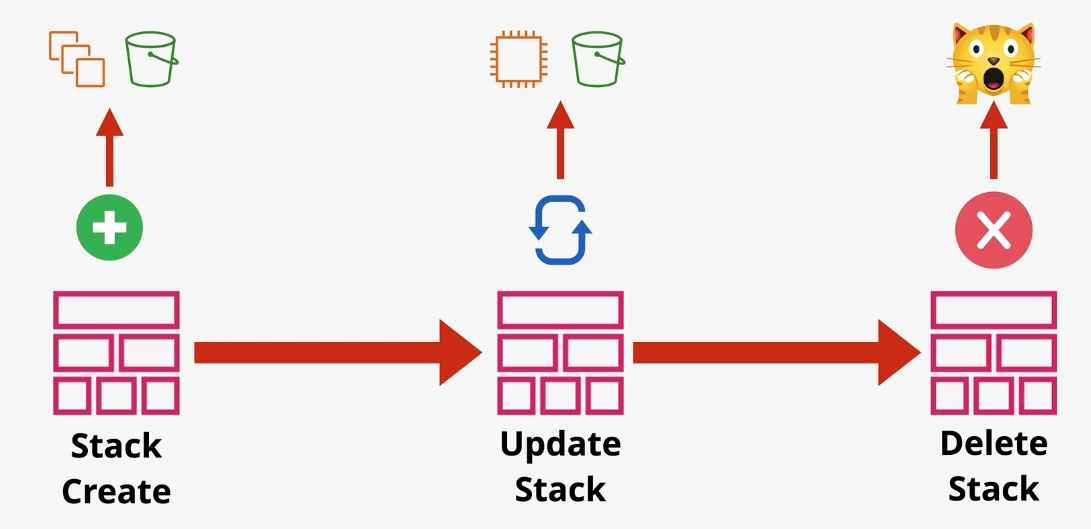
Template and Pseudo Parameters
Template and Pseudo Parameters are two methods to provide input to a template, which can influence what resources are provisioned, and the configuration of those resources.
- Template parameters accept input - console/CLI/API
- When a stack is created or updated
- Can be referenced from within Logical Resources
- Influence physical resources and/or configuration
- Can be configured with Defaults, AllowedValues, Min and Max length & AllowedPatterns, NoEcho & Type
Template Parameters

Pseudo Parameters
AWS::Regionmatches region template is used in
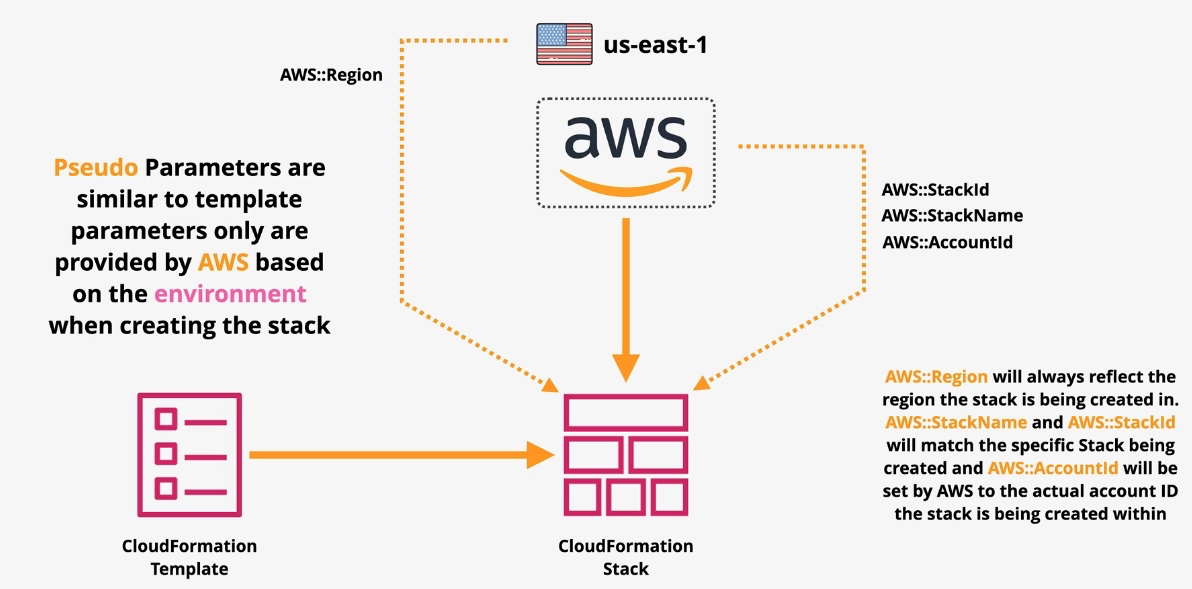
Intrinsic Functions
AWS CloudFormation provides several built-in functions that help you manage your stacks. Use intrinsic functions in your templates to assign values to properties that are not available until runtime.
RefandFn::GetAttFn::JoinandFn::SplitFn::GetAZsandFn::Select- Commonly used together
- Conditions (
Fn:: IF, And, Equals, Not, Or) Fn::Base64andFn::SubFn::Cidr- Later
Fn::ImportValueFn::FindInMapFn::Transform
Ref and Fn::GetAtt
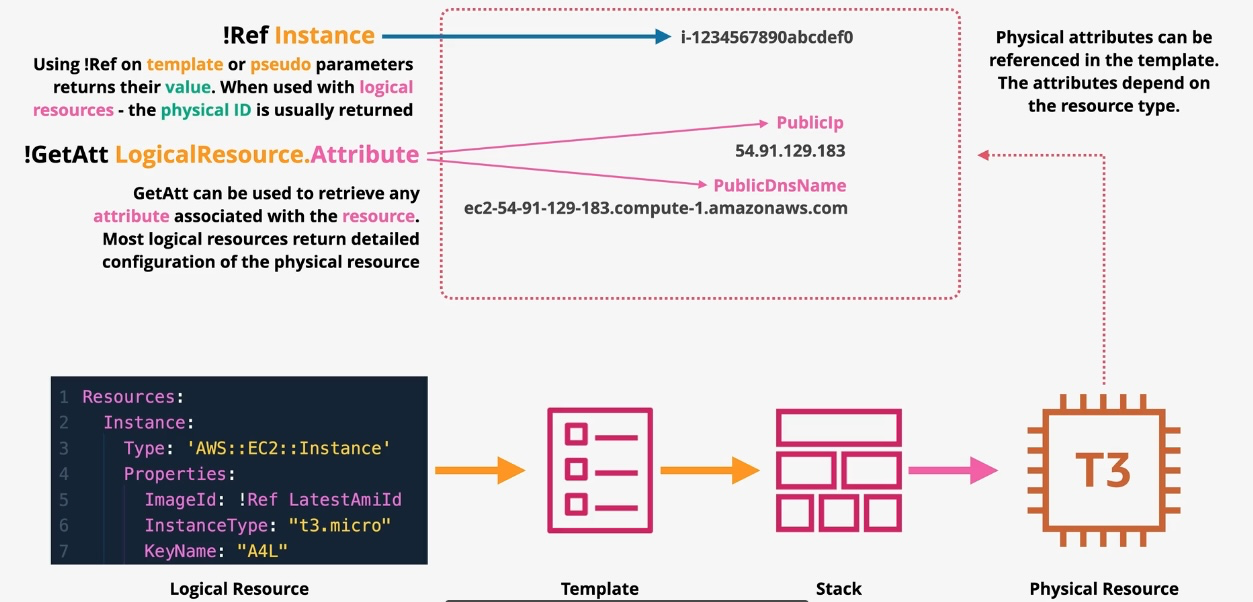
Fn::GetAZs and Fn::Select
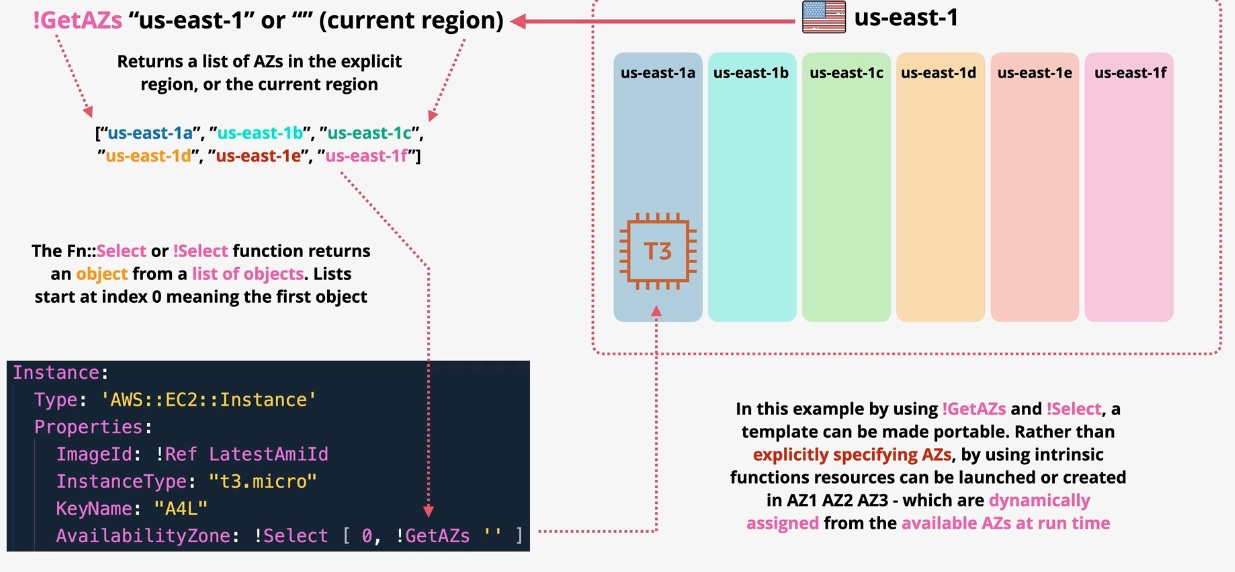
Fn::Join and Fn::Split

Fn::Base64 and Fn::Sub

FN::Cidr

Mappings
The optional
Mappingssection matches a key to a corresponding set of named values. For example, if you want to set values based on a region, you can create a mapping that uses the region name as a key and contains the values you want to specify for each specific region. You use theFn::FindInMapintrinsic function to retrieve values in a map.
- Templates can contain a Mappings object
- which can contain many mappings
- which map keys to values, allowing lookup
- Can have one key, or Top & Second level
- Mappings use the
!FindInMapintrinsic function - Common use - retrieve AMI for given region & architecture
- Improve template portability ❗
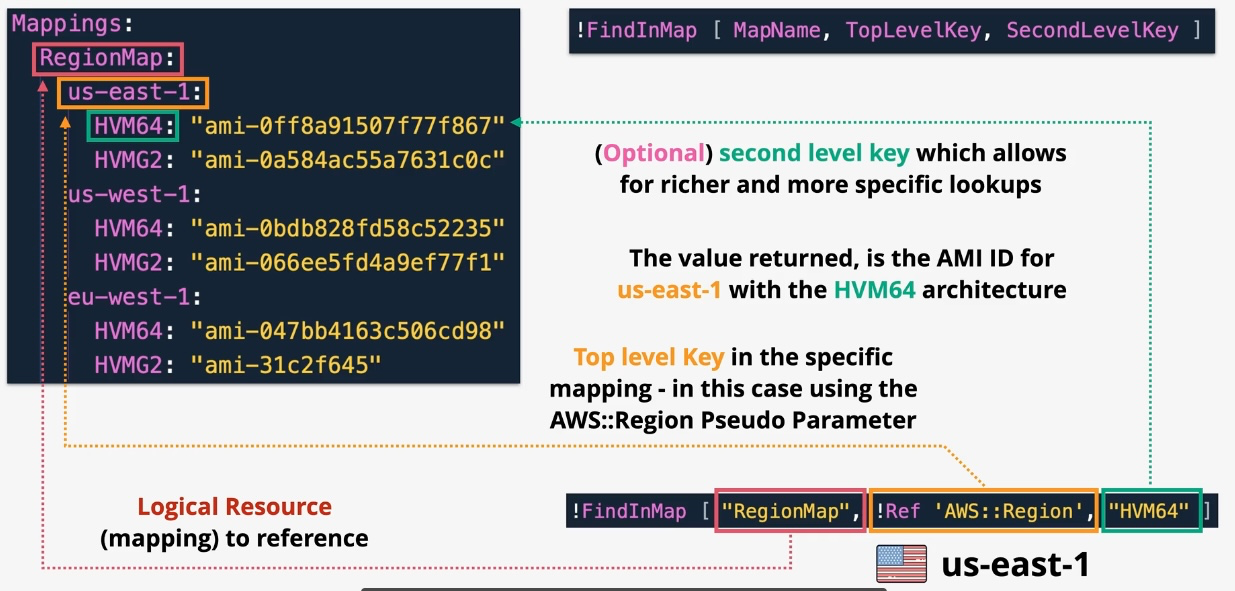
Outputs
The optional
Outputssection declares output values that you can import into other stacks (to create cross-stack references), return in response (to describe stack calls), or view on the AWS CloudFormation console. For example, you can output the S3 bucket name for a stack to make the bucket easier to find.
- Templates can have an optional Outputs section
- Values can be declared in this section
- Visible as outputs when using the CLI
- visible as outputs in the console UI
- accessible from a parent stack when using nesting ❗
- can be exported, allowing cross-stack references ❗

Conditions
The optional
Conditionssection contains statements that define the circumstances under which entities are created or configured. You might use conditions when you want to reuse a template that can create resources in different contexts, such as a test environment versus a production environment. In your template, you can add anEnvironmentTypeinput parameter, which accepts eitherprodortestas inputs. Conditions are evaluated based on predefined pseudo parameters or input parameter values that you specify when you create or update a stack. Within each condition, you can reference another condition, a parameter value, or a mapping. After you define all your conditions, you can associate them with resources and resource properties in theResourcesandOutputssections of a template
- Created in the optional
Conditionssection of a template - Conditions are evaluated to TRUE or FALSE
- processed before resources are created ❗
- Use the other intrinsic functions
AND, EQUALS, IF, NOT, OR- associated with logical resources to control if they are created or not
- e.g. ONEAZ, TWOAZ, THREEAZ - how many AZs to create resources in
- e.g. PROD, DEV - control the size of instances created in a stack
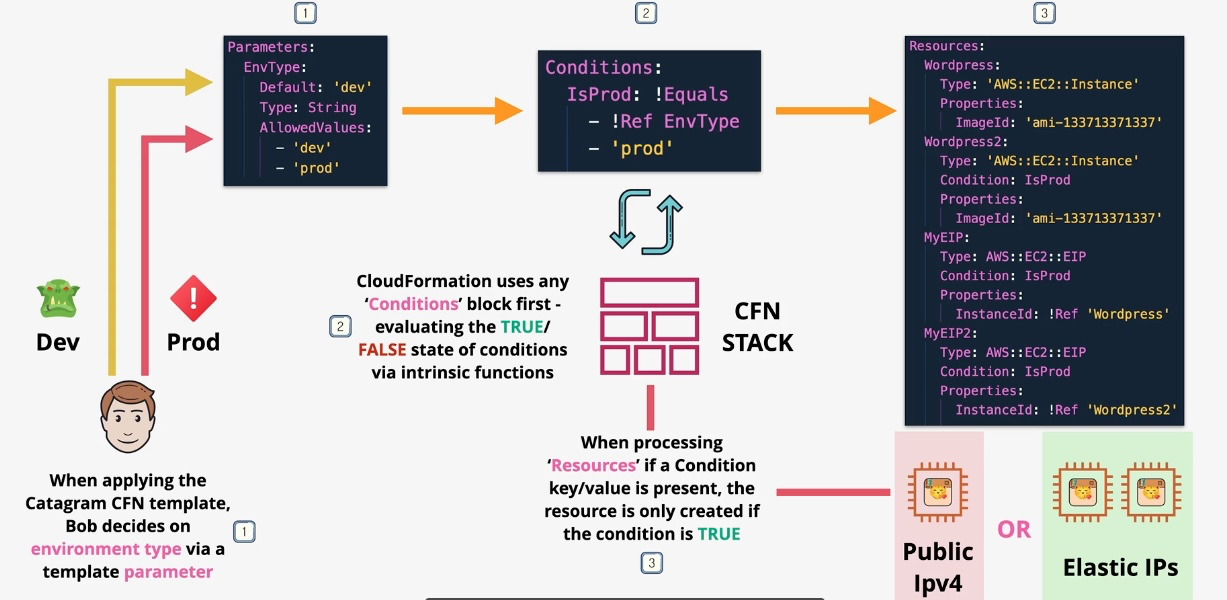
DependsOn
With the
DependsOnattribute you can specify that the creation of a specific resource follows another. When you add aDependsOnattribute to a resource, that resource is created only after the creation of the resource specified in theDependsOnattribute
- CloudFormation tries to be efficient
- does thing in parallel (create, update & delete)
- tries to determine a dependency order (VPC → SUBNET → EC2)
- references or functions create these
DependsOnlets you explicitly define these- If resources B and C depends on A
- both wait for A to complete before starting
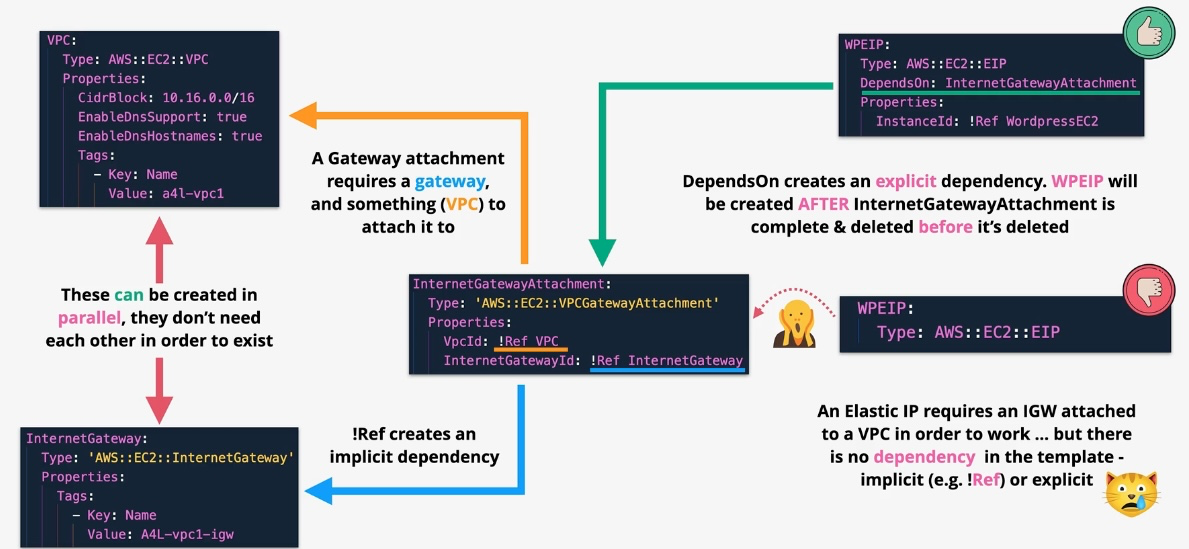
WaitCondition, CreationPolicy and cfn-signal
CreationPolicy, WaitConditions and cfn-signal can all be used together to prevent the status if a resource from reaching create complete until AWS CloudFormation receives a specified number of success signals or the timeout period is exceeded.The cfn-signal helper script signals AWS CloudFormation to indicate whether Amazon EC2 instances have been successfully created or updated.
CF Provisioning
- Logical resources in the template
- used to create stack
- creates physical resources in AWS
- Logical Resource CREATE_COMPLETE = All ok? ❓
CF Signal
- Configure CF to hold
- Wait for X number of success signals
- Wait for Timeout H:M:S for those signals (12 hour max)
- If success signals received - CREATE_COMPLETE
- If failure signal received - creation fails
- If timeout is reached - creation fails
- CreationPolicy or WaitCondition
CF CreationPolicy
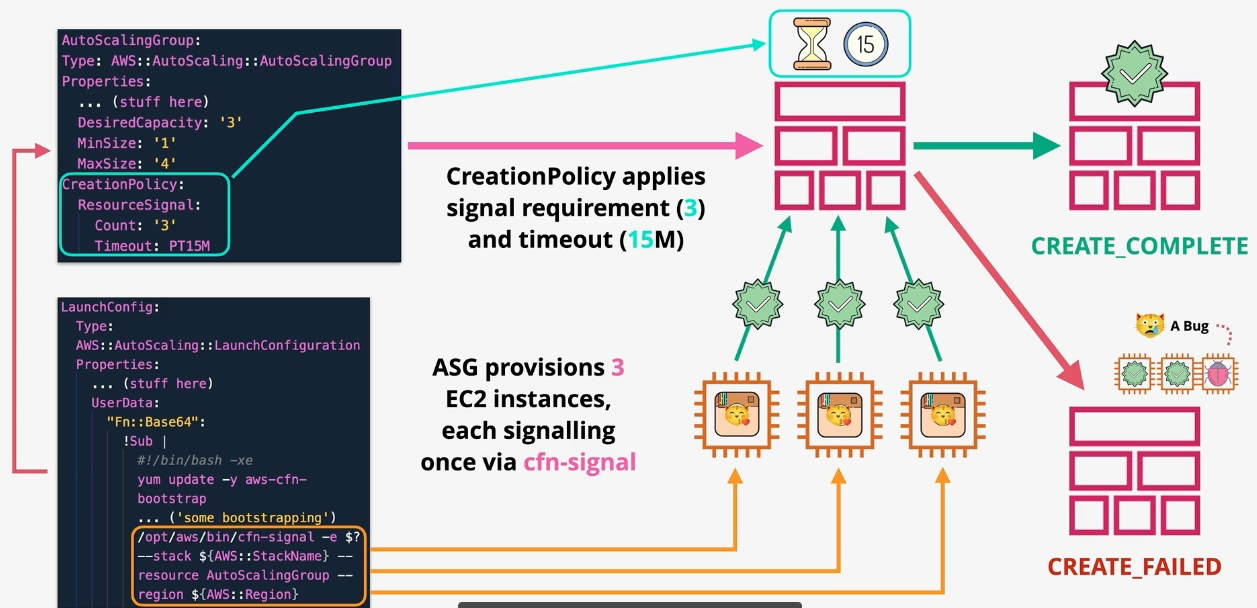
CF WaitCondition
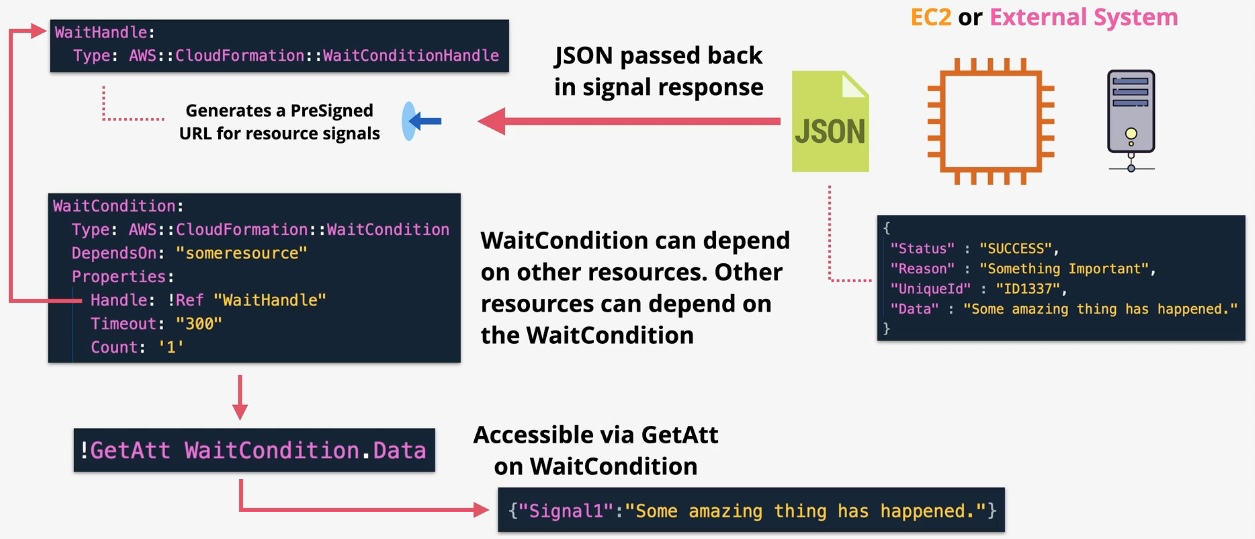
Nested Stacks
Nested stacks allow for a hierarchy of related templates to be combined to form a single product
A root stack can contain and create nested stacks .. each of which can be passed parameters and provide back outputs.
Nested stacks should be used when the resources being provisioned share a lifecycle and are related.
Key Concepts
- Overcome the 500 resource limit of one stack
- Modular templates - code resuse
- Make the installation process process easier
- nested stacks created by the root stack
- ❗Use only when everything is lifecycle linked! ❗
A Stack
- Resources in a single stack share a lifecycle
- Stack resource limits 500
- Can’t easily reuse resources, e.g. a VPC
- Can’t easily reference other stacks
Nested Stacks
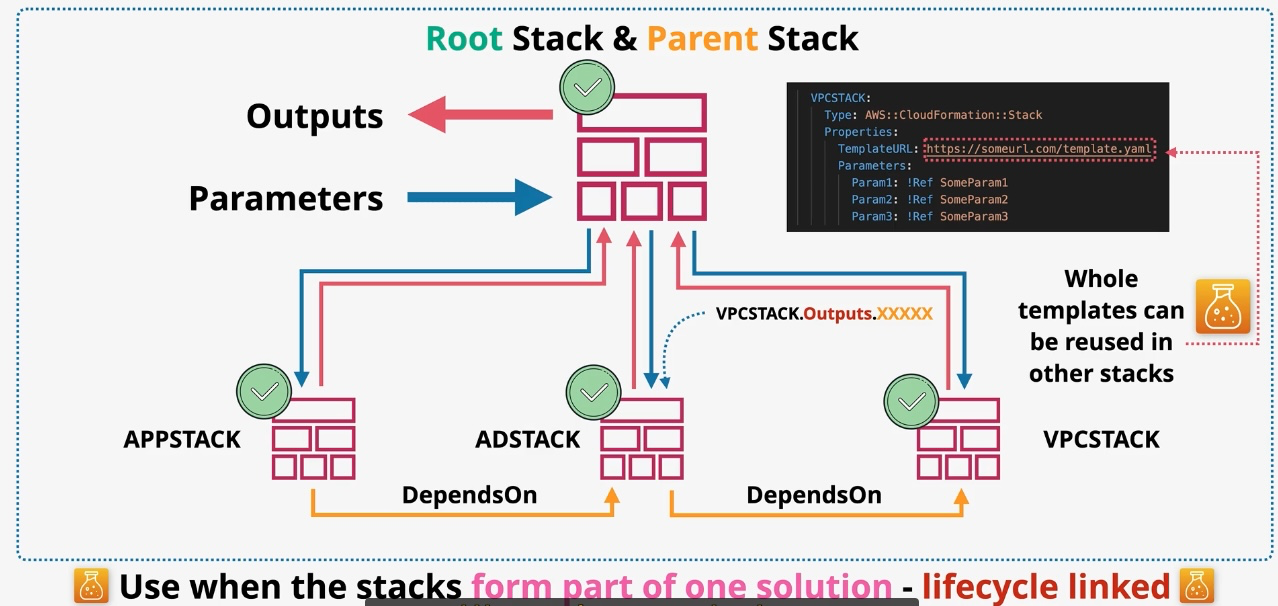
Cross-Stack References
Cross stack references allow one stack to reference another
Outputs in one stack reference logical resources or attributes in that stack
They can be exported, and then using the !ImportValue intrinsic function, referenced from another stack.
💡 Nested Stacks allow you to reuse templates - Cross-Stack References allow you to reuse actual physical resources
- Outputs are normally not visible from other stacks
- Nesten stacks can reference them
- Outputs can be exported - making them visible from other stacks
- Exports must have a unique name in the region
Fn::ImportValuecan be used instead ofRef
Architecture
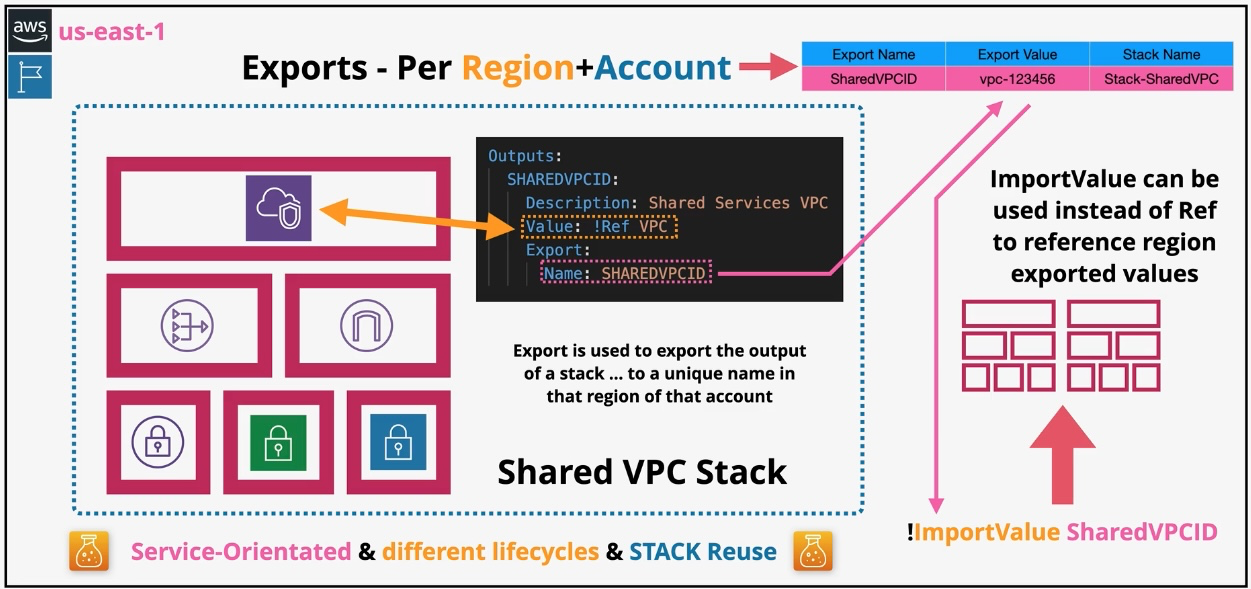
StackSets
StackSets are a feature of CloudFormation allowing infrastructure to be deployed and managed across multiple regions and multiple accounts from a single location.
Additionally it adds a dynamic architecture - allowing automatic operations based on accounts being added or removed from the scope of a StackSet.
- Deploy CFN stacks across many accounts and regions
- StackSets are containers in an admin account
- contain stack instances - which reference stacks
- Stack instances & stacks are in ‘target accounts’
- Each stack = 1 region in 1 account
- 🚨 Security = self-managed or service-managed 🚨
Key Concepts
- Term: Concurrent Accounts
- Term: Failure Tolerance
- Term: Retain Stacks
- Scenario: Enable AWS Config
- Scenario: AWS Config Rules - MFA, EIPS, EBS Encryption
- Scenario: Create IAM Roles for cross-account access
Architecture
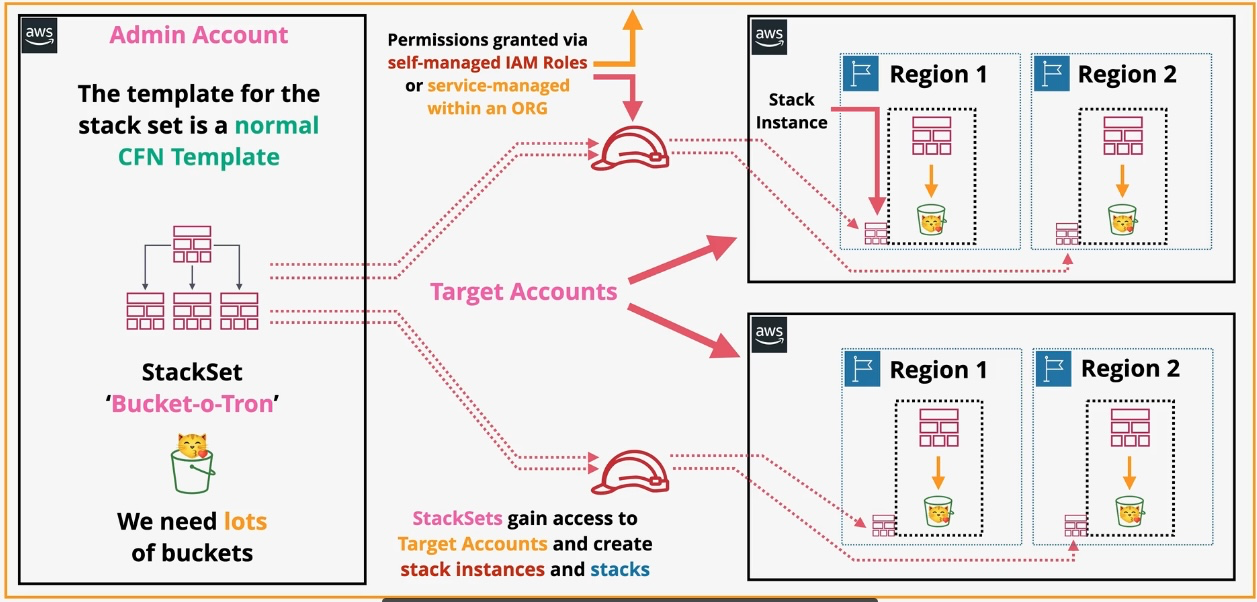
DeletionPolicy
With the DeletionPolicy attribute you can preserve or (in some cases) backup a resource when its stack is deleted. You specify a DeletionPolicy attribute for each resource that you want to control. If a resource has no DeletionPolicy attribute, AWS CloudFormation deletes the resource by default.
- If you delete a logical resource from a template
- by default, the physical resource is deleted
- This can cause data loss
- With deletion policy, you can define on each resource
- Delete (Default)
- Retain
- (if supported) Snapshot
- Supported resources for snapshot: EBS Volume, ElastiCache, Neptune, RDS, Redshift
- Snapshots continue past Stack lifetime - you have to clean up
- ONLY APPLIES TO DELETE - NOT REPLACE
Visual
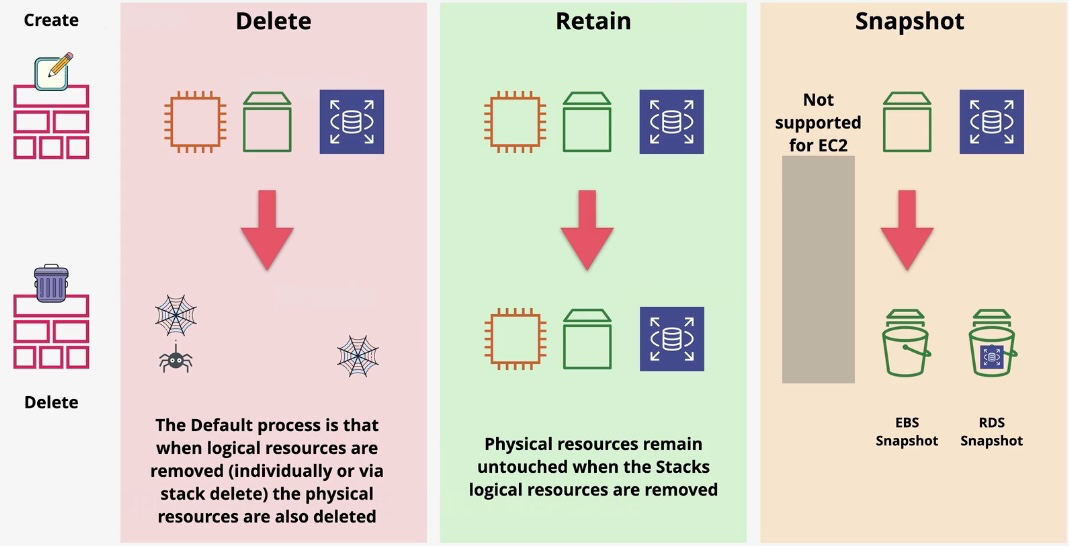
Stack Roles
Stack roles allow an IAM role to be passed into the stack via PassRole
A stack uses this role, rather than the identity interacting with the stack to create, update and delete AWS resources.
It allows role separation and is a powerful security feature.
- When you create a stack CFN creates physical resources
- CFN uses the permissions of the logged in identity
- Which means you need permissions for AWS
- CFN can assume a role to gain the permissions
- This lets you implement role reparation
- The identity creating the stack doesn’t need resource permissions - only PassRole
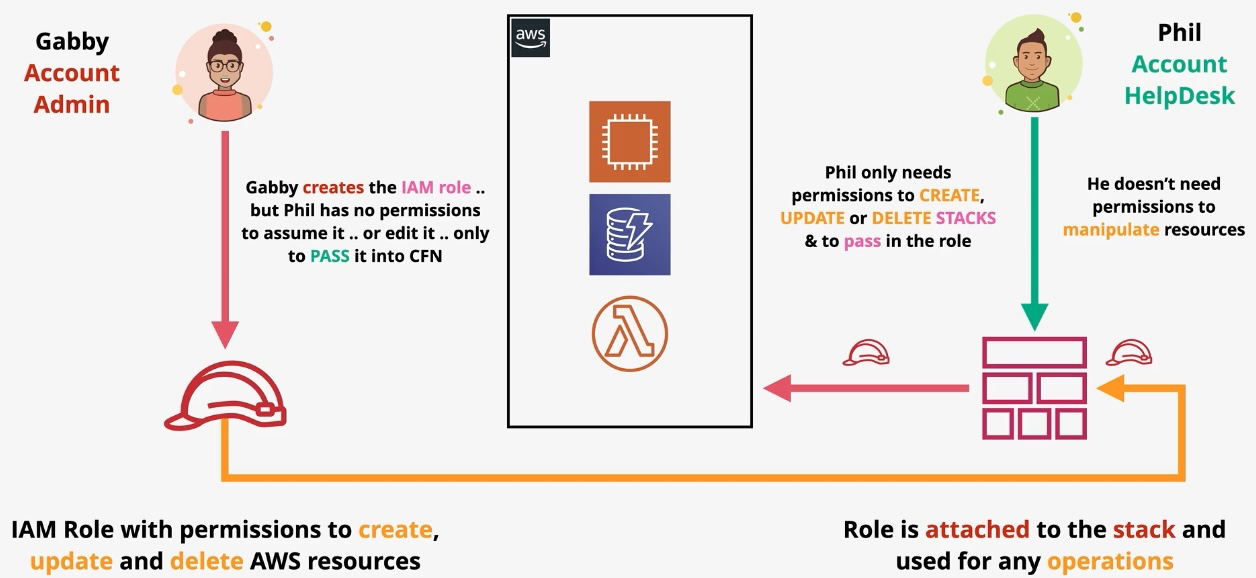
CloudFormationInit (CFN-INIT)
CloudFormationInit and cfn-init are tools which allow a desired state configuration management system to be implemented within CloudFormation
Use the AWS::CloudFormation::Init type to include metadata on an Amazon EC2 instance for the cfn-init helper script. If your template calls the cfn-init script, the script looks for resource metadata rooted in the AWS::CloudFormation::Init metadata key. cfn-init supports all metadata types for Linux systems & It supports some metadata types for Windows
- Simple configuration management system
- Configuration directives stored in template
AWS::CloudFormation::Initpart of logical resource- Procedural - HOW (User Data)
- vs Desired State - WHAT (cfn-init)
- cfn-init helper scripts - installed on EC2 OS
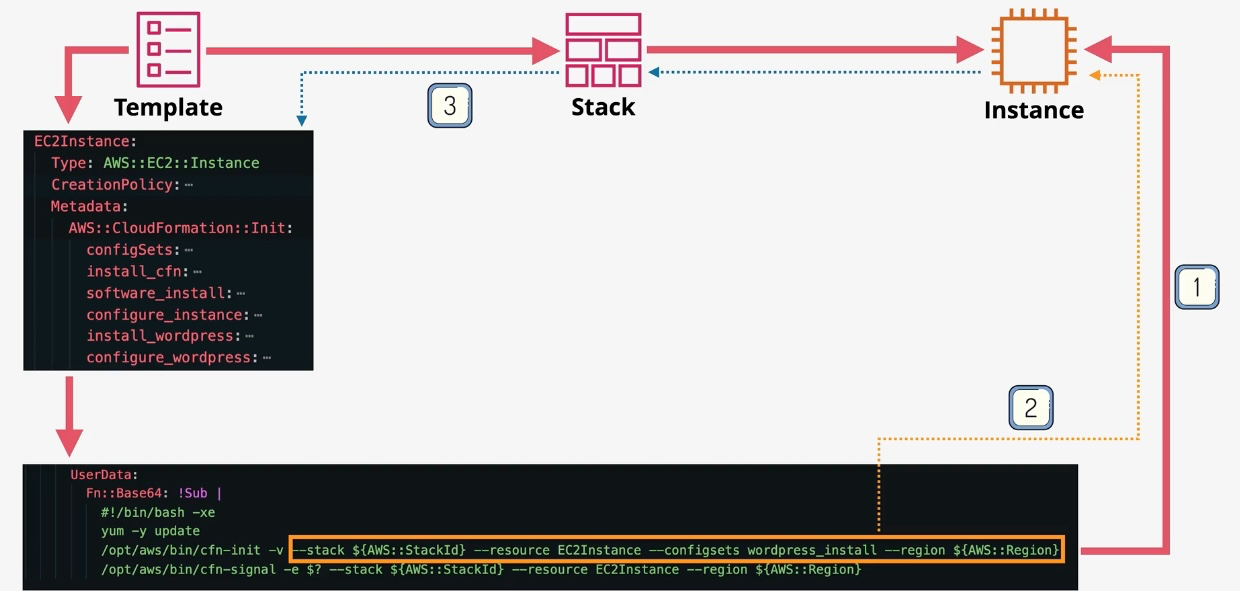
cfn-hup
The cfn-hup helper is a daemon that detects changes in resource metadata and runs user-specified actions when a change is detected. This allows you to make configuration updates on your running Amazon EC2 instances through the UpdateStack API action.
- cfn-init is run once as part of bootstrapping (user data)
- if CloudFormation::Init is updated, it isn’t rerun
- cfn-hup helper is a daemon which can be installed
- it detects changes in resource metadata
- running configurable actions when a change is detected
- UpdateStack → updated config on EC2 instances
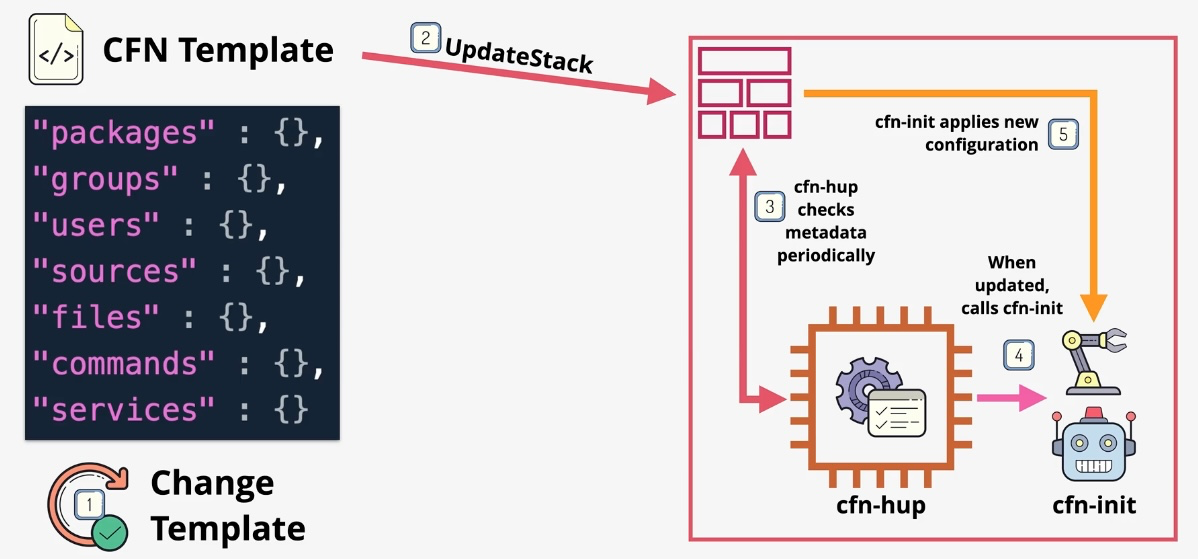
ChangeSets
When you need to update a stack, understanding how your changes will affect running resources before you implement them can help you update stacks with confidence. Change sets allow you to preview how proposed changes to a stack might impact your running resources, for example, whether your changes will delete or replace any critical resources, AWS CloudFormation makes the changes to your stack only when you decide to execute the change set, allowing you to decide whether to proceed with your proposed changes or explore other changes by creating another change set.
- Template → Stack → Physical Resources (CREATE)
- Stack (Delete) → (Delete) Physical Resources
- v2 Template → Existing Stack → Resources Change
- ⚠️No interruption, ⚠️ some interruption, 🚨 Replacement 🚨
- ChangeSets let you preview changes (A Change Set)
- multiple different versions (lots of change sets)
- Chosen changes can be applied by executing the change set
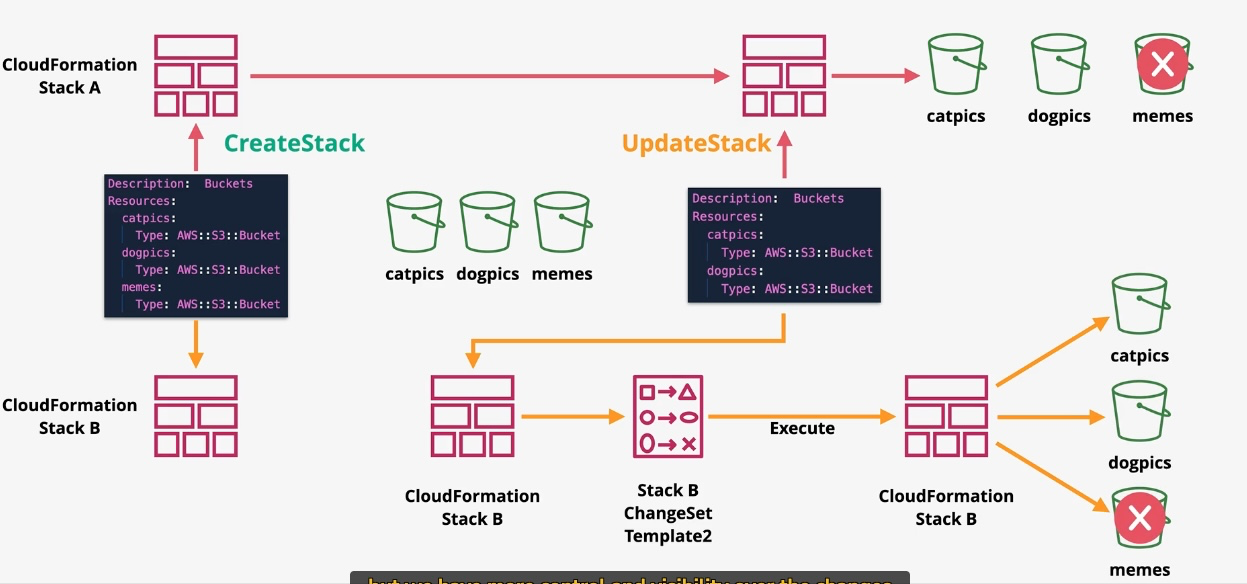
Custom Resources
Custom resources enable you to write custom provisioning logic in templates that AWS CloudFormation runs anytime you create, update (if you changed the custom resource), or delete stacks
- Logical resources in a template - WHAT you want
- CFN uses them to CREATE, UPDATE and DELETE physical resources
- CloudFormation doesn’t support everything
- ❗Custom Resources let CFN integrate with anything it doesn’t yet, or doesn’t natively support ❗
- ❗Passes data to something, gets data back from something❗
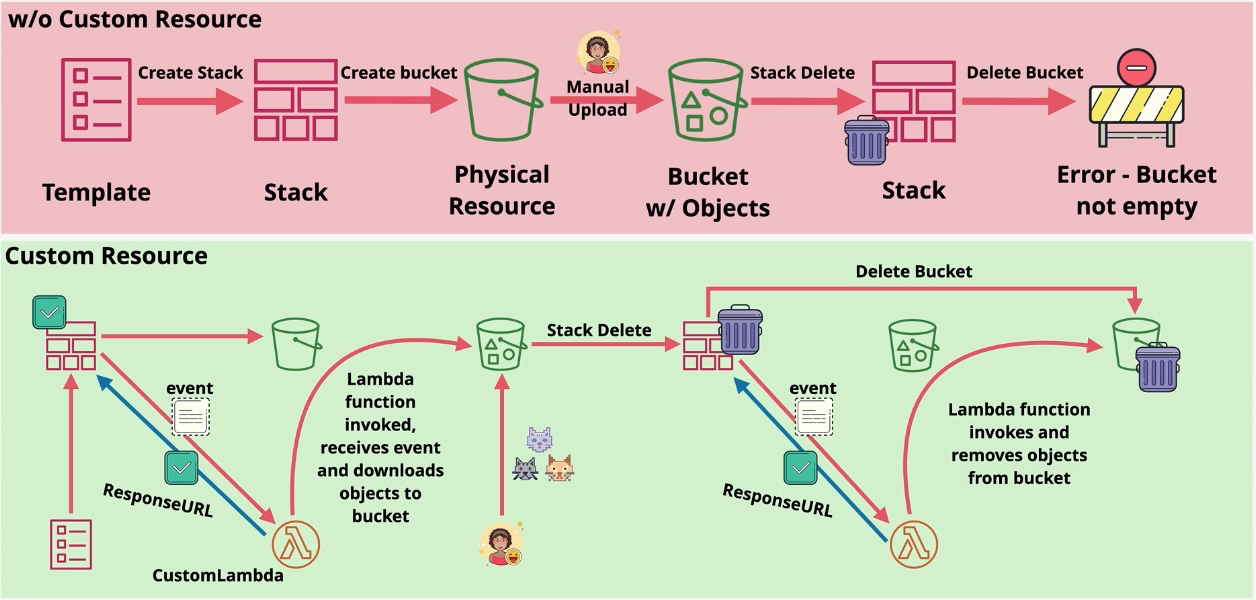
👃NoSQL Databases & DynamoDB 🧨
DynamoDB - Architecture
DynamoDB is a NoSQL fully managed Database-as-a-Service (DBaaS) product available within AWS.
- NoSQL Public Database-as-a-Service (DBaaS). Key/Value & Document
- No self-managed servers or infrastructure
- Manual/automatic provisioned performance IN/OUT or on-demand
- Highly Resilient
- Across AZs
- Optionally GLOBAL
- Really fast - single-digit milliseconds (SSD based)
- Backups, point-in-time recovery, encryption at rest
- Event-Driven integration - do things when data changes
DynamoDB Considerations
- NoSQL - Preference DynamoDB in exam
- Relational Data - Generally NOT DynamoDB
- Key/value - Preference DynamoDB in exam
- Access via console, CLI, API - “No SQL”
- Billed based RCU, WCU, Storage and Features
- No cost for infrastructure
DynamoDB Tables
Database-(table)-as-a-Service
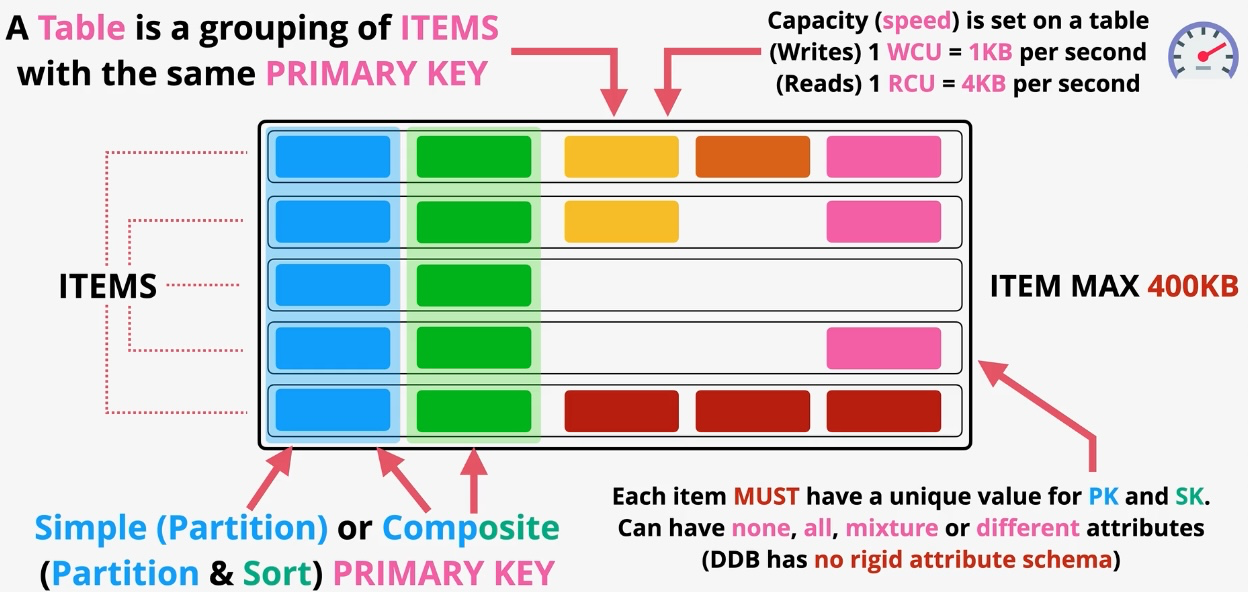
On-Demand Backups
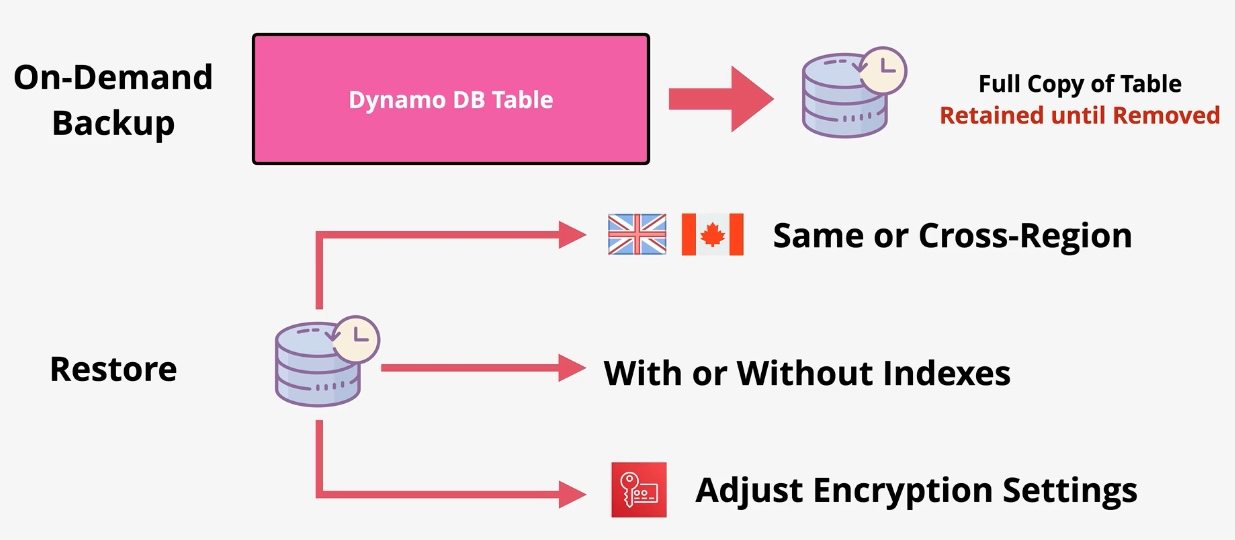
Point-in-time Recovery (PITR)
Not enabled by default
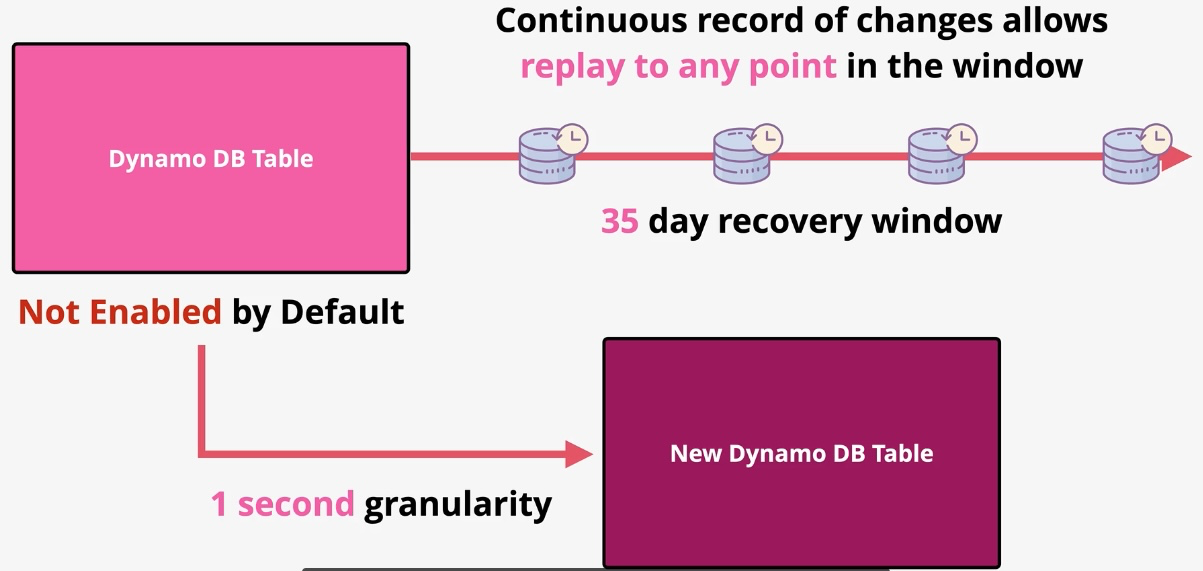
Operations, Consistency and Performance
Reading and Writing
- On-Demand: Unknown, unpredictable, low admin
- On-Demand: price per million R/W units
- Provisioned - RCU and WCU set on a per table basis
- ❗Every operation consumes at least 1 RCU/WCU❗
- ❗1 RCU is 1 x 4KB read operation per second ❗
- ❗1 WCU is 1 x 1KB write operation per second ❗
- Every table has a RCU and WCU burst pool (300 seconds)
Query
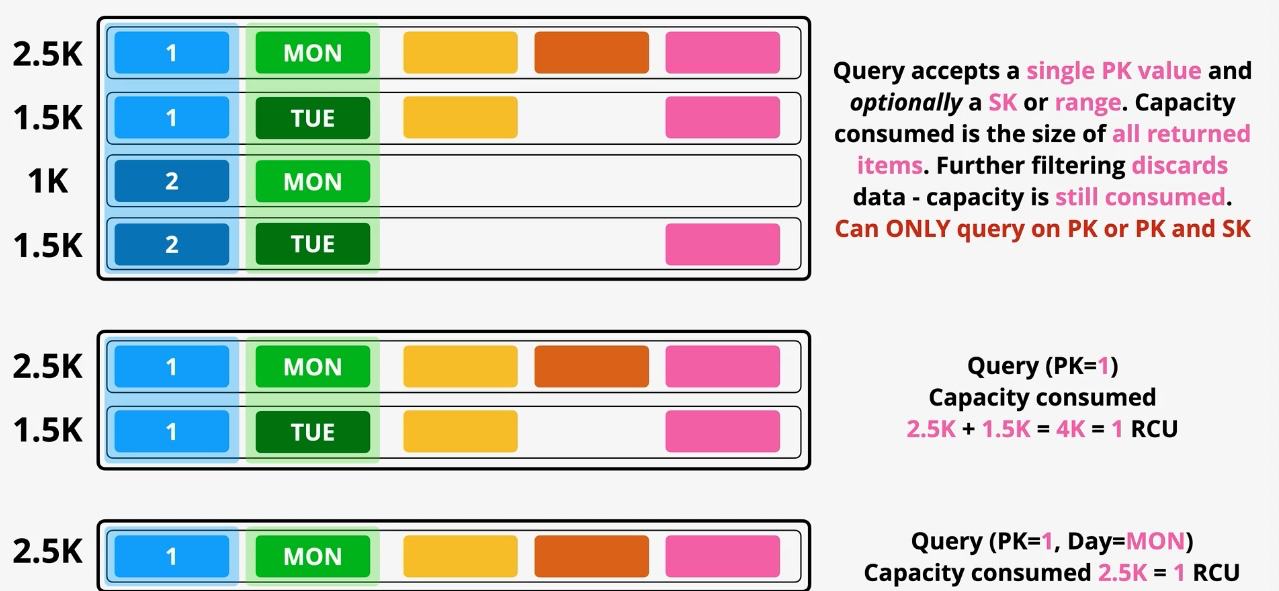
Scan
Least efficient operation in DynamoDB, but also most flexible
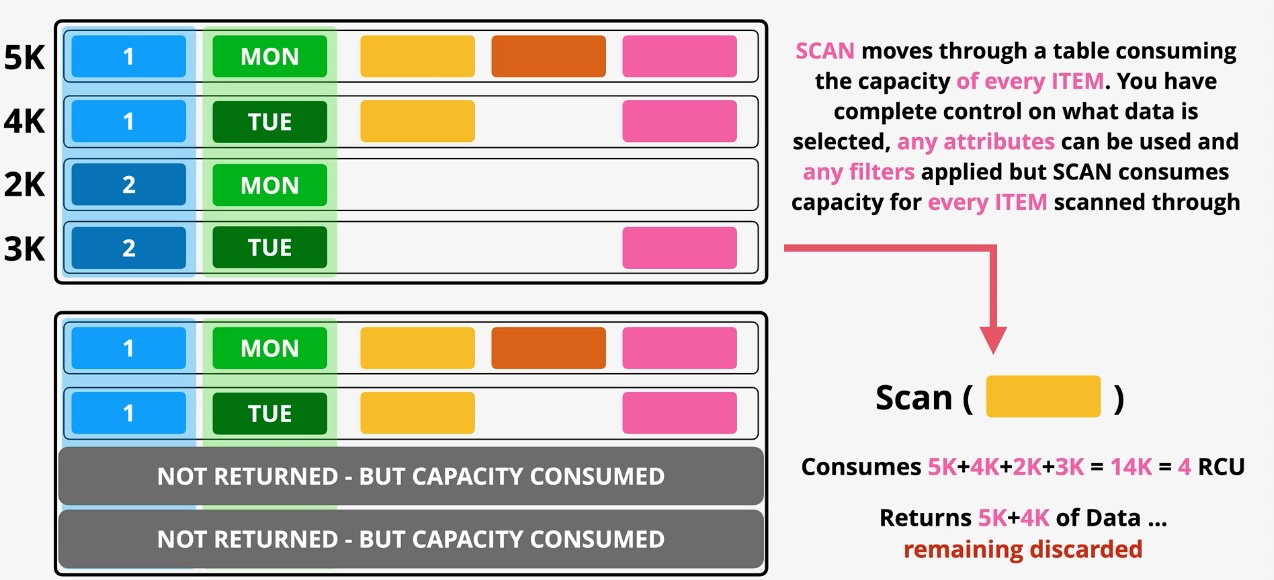
Consistency Model
Eventually or strong/immediate consistency
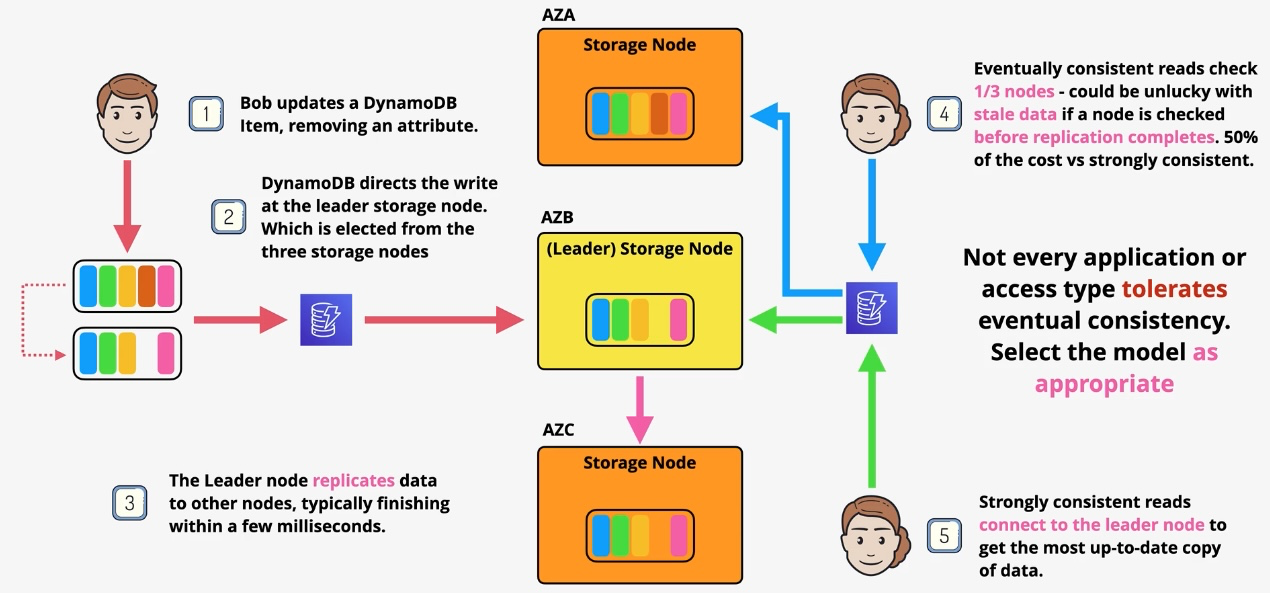
WCU Calculation
If you need to store 10 ITEMS per second - 2.5K average size per ITEM
Calculate WCU per item - ROUND UP! ITEM.SIZE / 1 KB (3)
Multiply by average number per second (30)
= WCU Required (30)
RCU Calculation
Need to retrieve 10 ITEMS per second - 2.5K average size
Calculate RCU per item - ROUND UP! ITEM.SIZE / 4KB = 1
Multiply by average read ops per second (10)
= Strongly Consistent RCU Required = 10
(50% of strongly consistent) = Eventually consistent RCU required = 5
DynamoDB Local and Global Secondary Indexes
Local Secondary Indexes (LSI) and Global Secondary Indexes (GSI) allow for an alternative presentation of data stored in a base table.
LSI allow for alternative SK's whereas with GSIs you can use alternative PK and SK.
DynamoDB Indexes
- Query is the most efficient operation in DDB
- Query can only work on 1 PK value at a time
- and optionally a single, or range of SK values
- Indexes are alternative views on table data
- ❗Different SK (LSI) or different PK and SK (GSI)❗
- ❗Some or all attributes (projection) ❗
Local Secondary Indexes (LSI)
- LSI is an alternative view for a table
- MUST be created with a table❗
- Use when strong consistency is required ❗
- 5 LSI’s per base table
- Alternative SK on the table❗
- Shares the RCU and WCU with the table❗
- Shared Capacity Settings with the table
- Attributes - ALL, KEYS_ONLY & INCLUDE
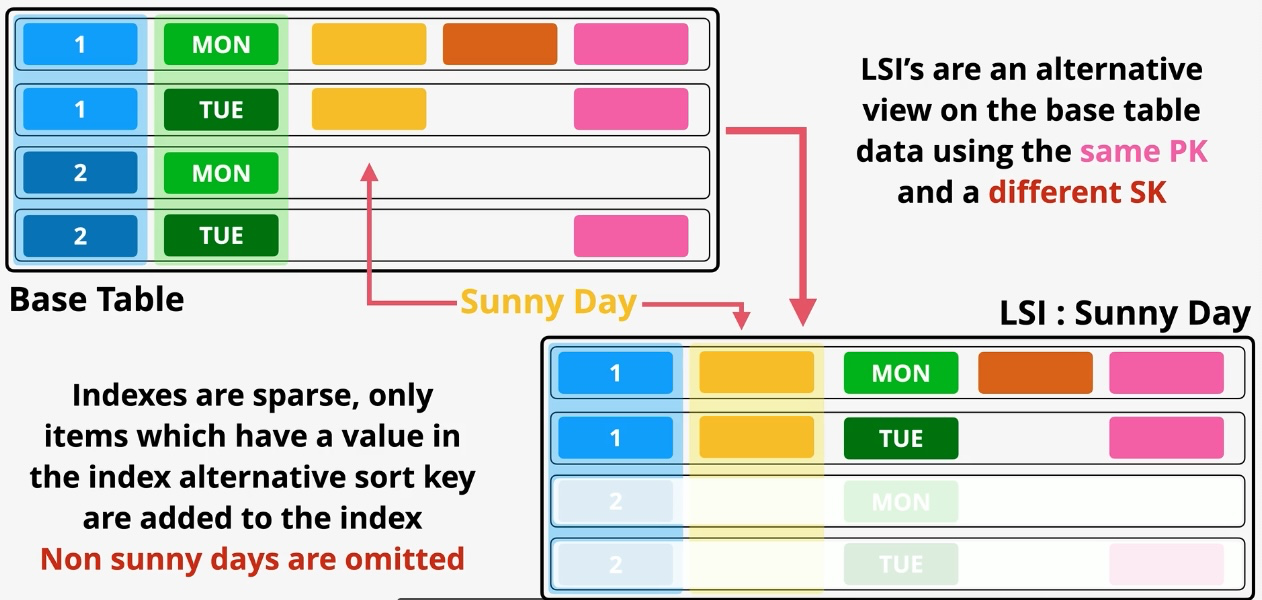
Global Secondary Indexes (GSI)
- Can be created at any time❗
- Default limit of 20 per base table❗
- Use as default, when strong consistency is NOT required ❗
- Alternative PK and SK❗
- GSI’s have their own RCU and WCU allocations ❗
- Attributes - ALL, KEYS_ONLY & INCLUDE
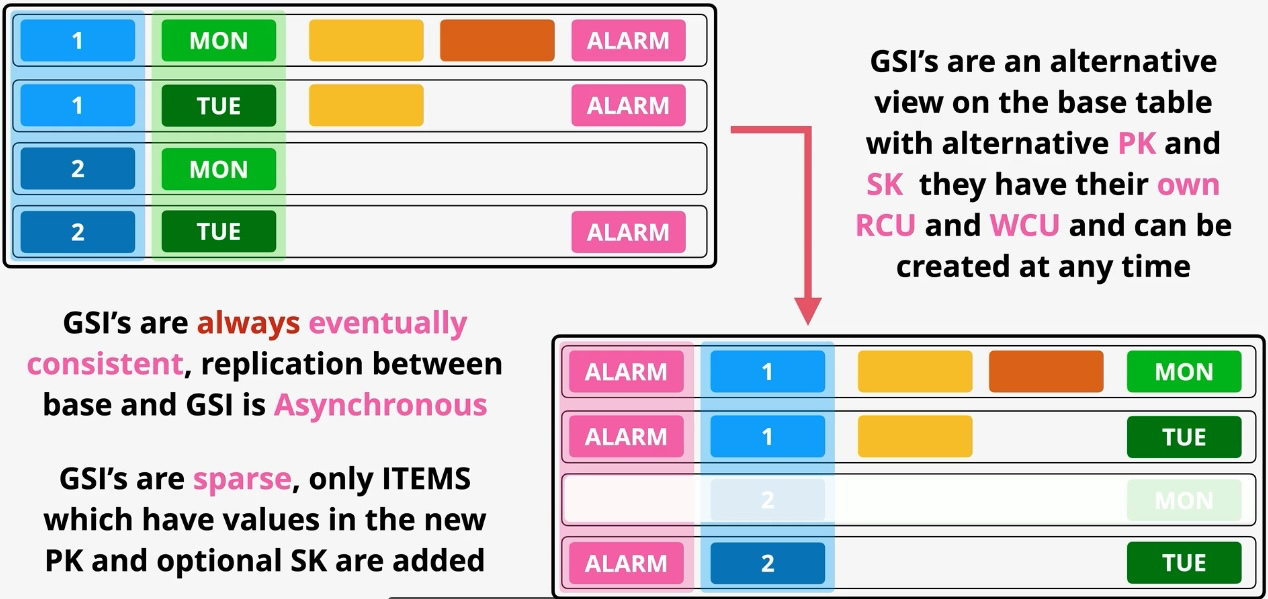
LSI and GSI Considerations
- Careful with projection (KEYS_ONLY, INCLUDE, ALL)
- Queries on attributes NOT projected are expensive
- Use GSIs as default, LSO only when strong consistency is required ❗
- Use indexes for alternative access patterns
Streams and Triggers
DynamoDB Streams are a 24 hour rolling window of time ordered changes to ITEMS in a DynamoDB table
Streams have to be enabled on a per table basis , and have 4 view types
KEYS_ONLY
NEW_IMAGE
OLD_IMAGE
NEW_AND_OLD_IMAGES
Lambda can be integrated to provide trigger functionality - invoking when new entries are added on the stream.
Stream Concepts
- Time ordered list of ITEM CHANGES in a table
- 24-hour rolling window
- Enabled on a per table basis
- Records INSERTS, UPDATE and DELETES
- Different view types influence what is in the stream
- KEYS_ONLY
- NEW_IMAGE
- OLD_IMAGE
- NEW_AND_OLD_IMAGES
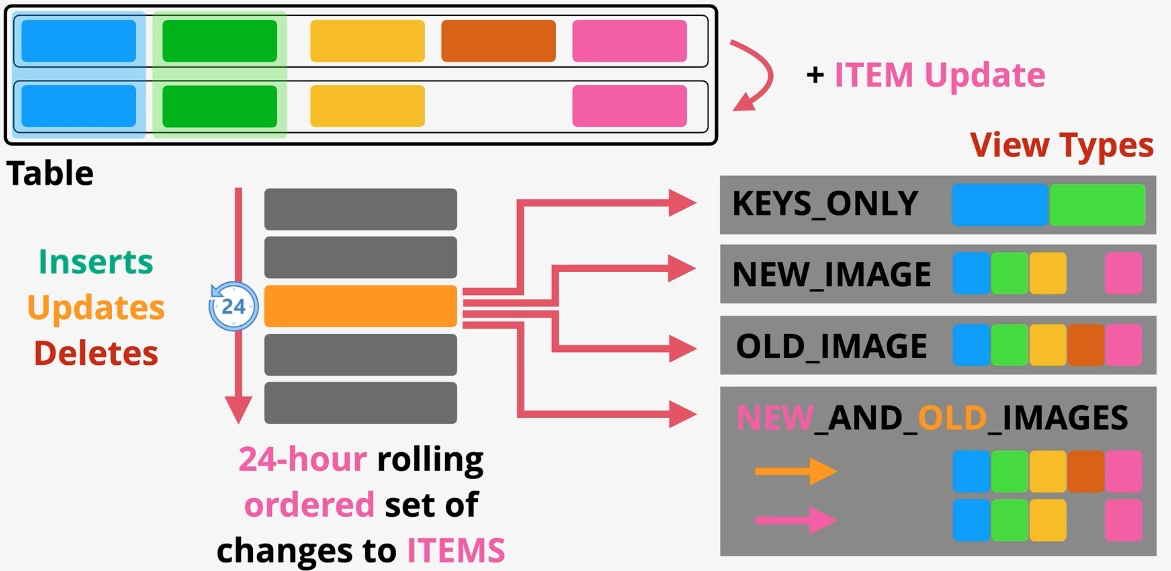
Trigger Concepts
Event-driven architecture - respond to events
- ITEM changes generate an event
- That event contains the data which changed
- An action is taken using that data
- AWS = Streams + Lambda
- Reporting & Analytics
- Aggregation, Messaging or Notifications
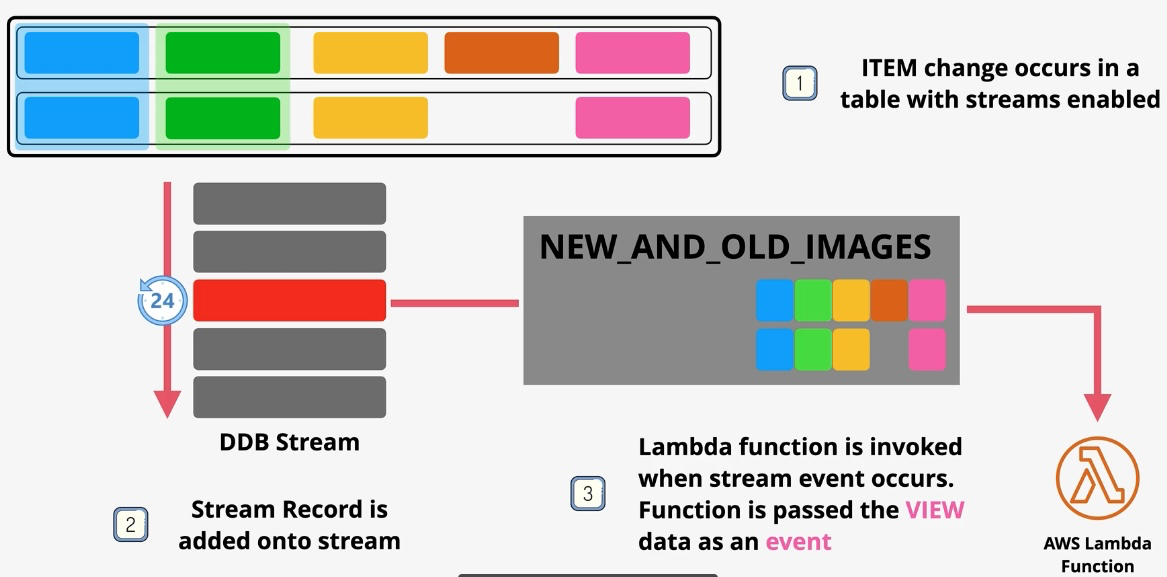
Global Tables
DynamoDB Global Tables provides multi-master global replication of DynamoDB tables which can be used for performance, HA or DR/BC reasons.
- Global tables provides multi-master cross-region replication
- Tables are created in multiple regions and added to the same global table (becoming replica tables)
- Last writer wins is used for conflict resolution
- Reads and writes can occur to any region
- Generally sub-second replication between regions
- Strongly consistent reads ONLY in the same region as writes
- Global eventual consistency
- Provides Global HA and Global DR/BC
DynamoDB Accelerator (DAX)
DynamoDB Accelerator (DAX) is an in-memory cache designed specifically for DynamoDB. It should be your default choice for any DynamoDB caching related questions.
Traditional Caches vs DAX
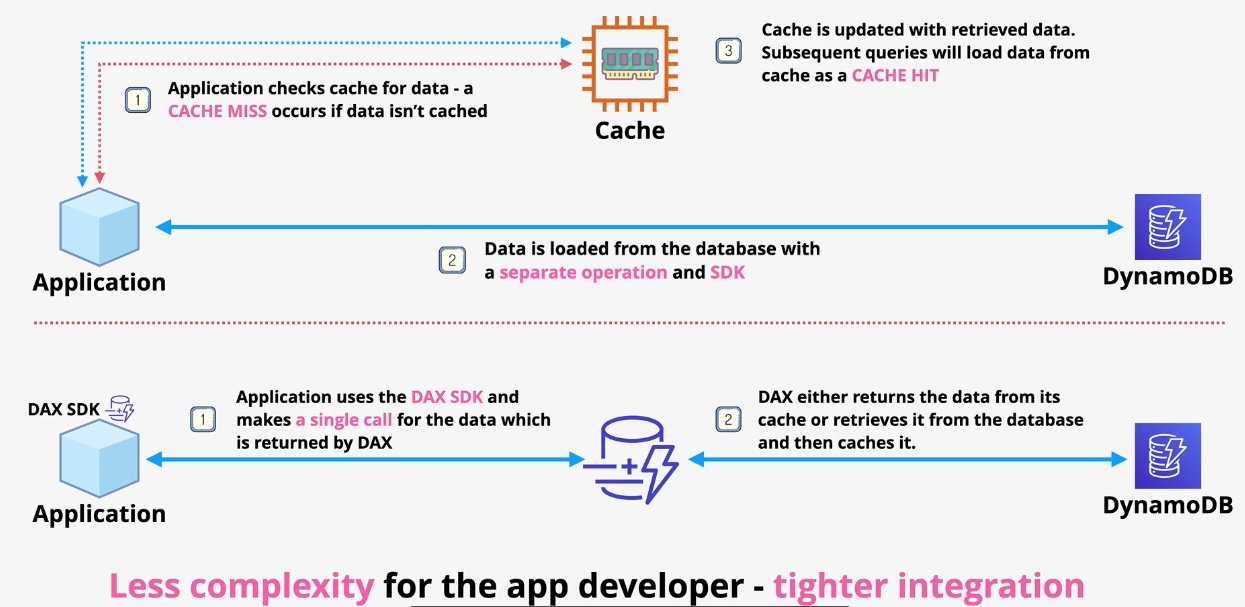
DAX Architecture
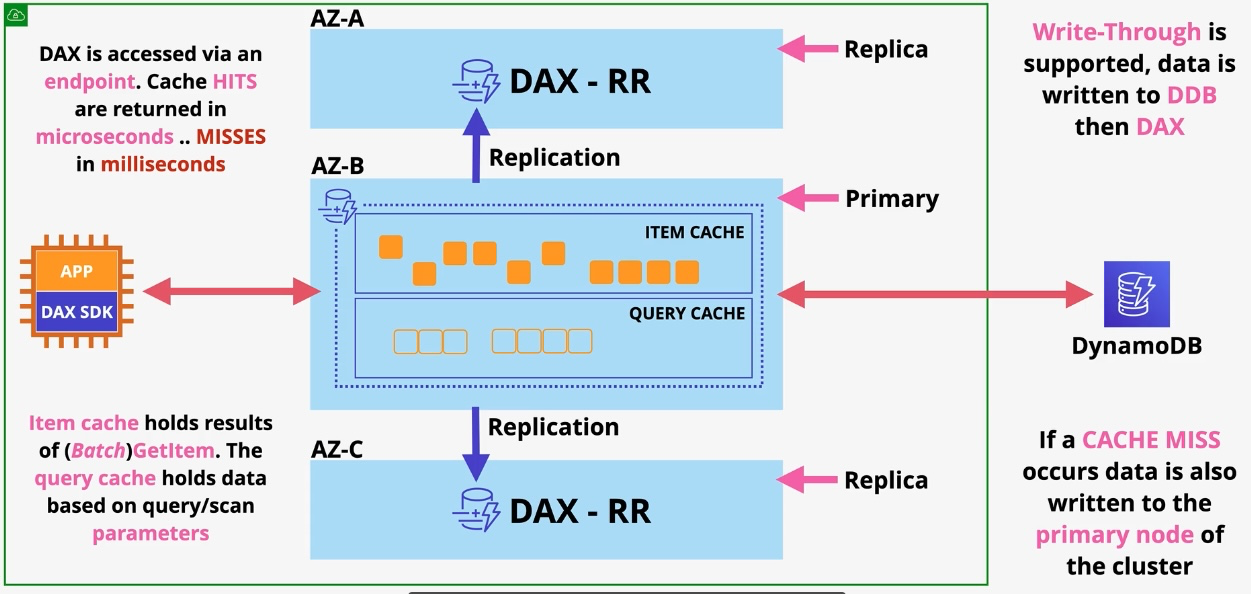
DAX Considerations
- Primary NODE (Writes) and Replicas (Read)
- Nodes are HA - Primary failure = Election
- In-memory cache - Scaling. Much faster reads, reduced costs
- Scale UP and scale OUT (Bigger or More)
- Supports write-through
- DAX Deployed WITHIN a VPC
- Bad if strong consistency is required❗
DynamoDB TTL
Amazon DynamoDB Time to Live (TTL) allows you to define a per-item timestamp to determine when an item is no longer needed. Shortly after the date and time of the specified timestamp, DynamoDB deletes the item from your table without consuming any write throughput. TTL is provided at no extra cost as a means to reduce stored data volumes by retaining only the items that remain current for your workload’s needs
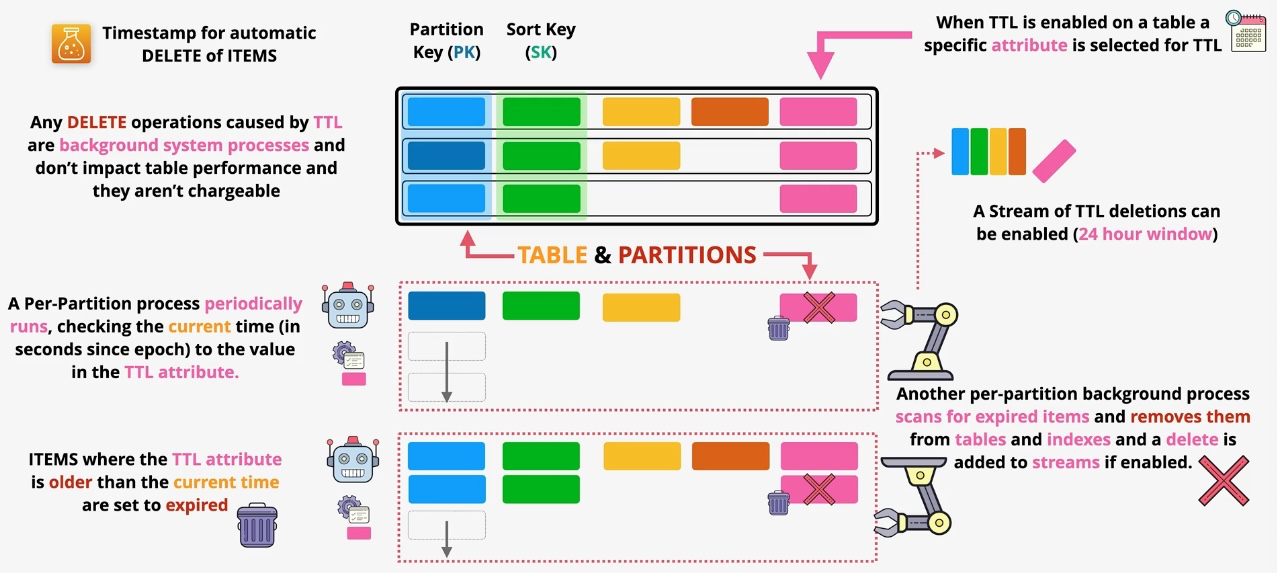
Amazon Athena
Amazon Athena is serverless querying service which allows for ad-hoc questions where billing is based on the amount of data consumed.
Athena is an underrated service capable of working with unstructured, semi-structured or structured data
- Serverless Interactive Querying Service
- Ad-hoc queries on data - pay only data consumed
- Schema-on-read - table-like translation
- Original data never changed - remains on S3
- Schema translates data → relational-like when read
- Output can be sent to other services
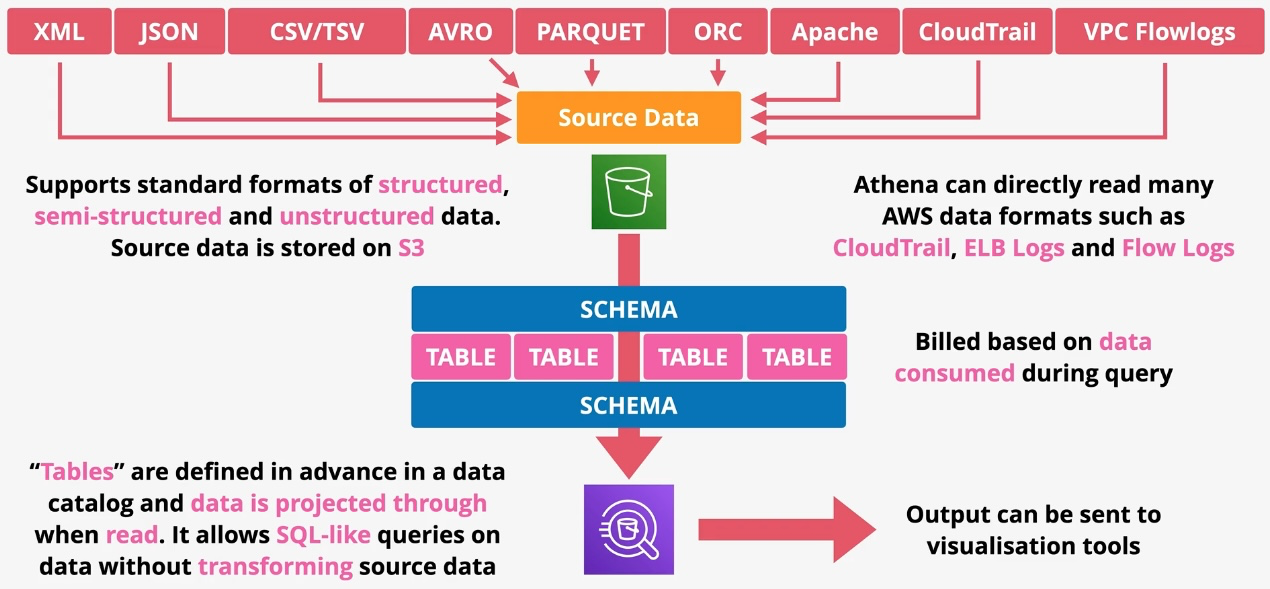
Athena Considerations
- Queries where loading/transformation isn’t desired
- Occasional / ad-hoc queries on data in S3
- Serverless querying scenarios - cost conscious
- Querying AWS logs - VPC Flow logs, CloudTrail, ELB logs, cost reports etc…
- AWS Glue Data Catalog & Web Server Logs
- w/ Athena Federated Query - other data sources
ElastiCache
ElastiCache is a managed in-memory cache which provides a managed implementation of the Redis or Memcached engines.
It’s useful for read heavy workloads, scaling reads in a cost effective way and allowing for externally hosted user session state.
- In-memory database - high performance
- Managed Redis or Memcached - as a serivce ❗
- Can be used to cache data - for READ HEAVY workloads with low latency requirements ❗
- Reduces database workloads (expensive)❗
- Can be used to store Session Data (Stateless Servers)❗
- **Requires application code changes!!**❗
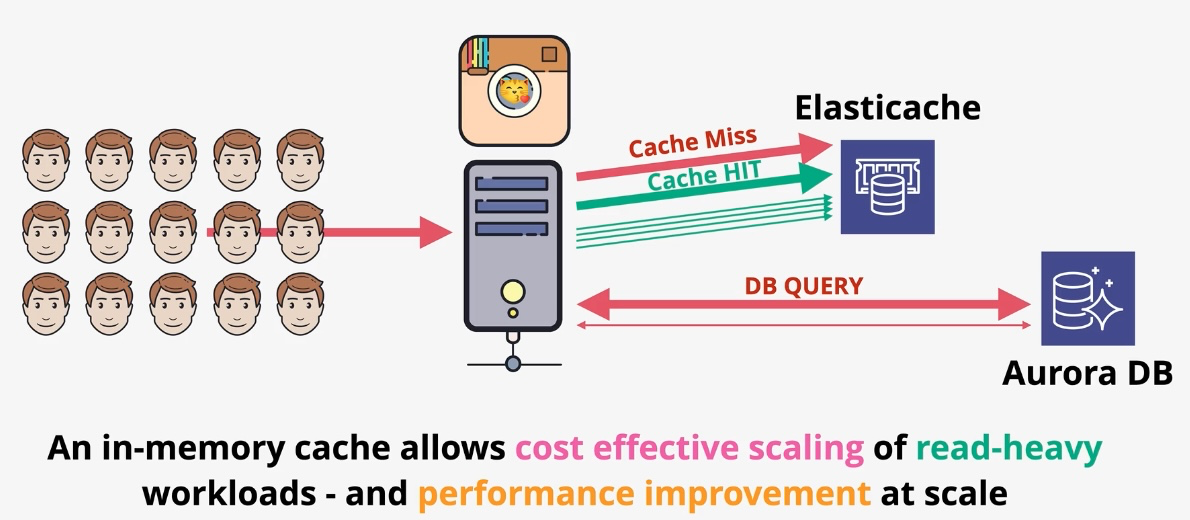
Session State Data
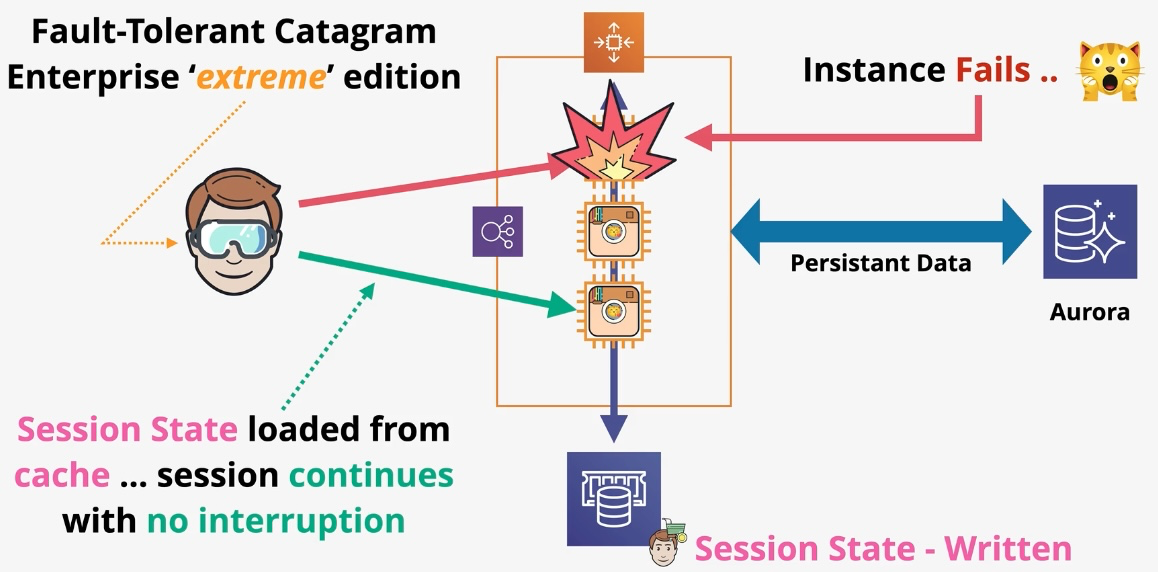
Redis vs MemcacheD
MemcacheD
- Simple data structures
- No replication
- Multiple Nodes (sharding)
- No backups
- Multi-threaded
- Utilize CPU
Redis
- Advanced Structures
- Multi-AZ
- Replication (Scale reads)
- Backup & Restore
- Transactions
- More strict consistency requirements
Redshift Architecture
Redshift is a column based, petabyte scale, data warehousing product within AWS
Its designed for OLAP products within AWS/on-premises to add data to for long term processing, aggregation and trending.
- Petabyte-scale Data warehouse
- OLAP (Column based) not OLTP (row/transaction)
- Pay as you use - similar structure to RDS
- Direct Query S3 using Redshift Spectrum
- Direct Query other DBs using federated query
- Integrates with AWS tooling such as Quicksight
- SQL-like interface JDBC/ODBC
Architecture
- Server based (not serverless)
- One AZ in a VPC - network cost/performance
- Leader node - Query input, planning and aggregation
- Compute node - performing queries of data
- VPC security, IAM permissions, KMS at rest Encryption, CW monitoring
- Redshift Enhanced VPC Routing - VPC Networking ❗
- Routing based on VPC/SG etc
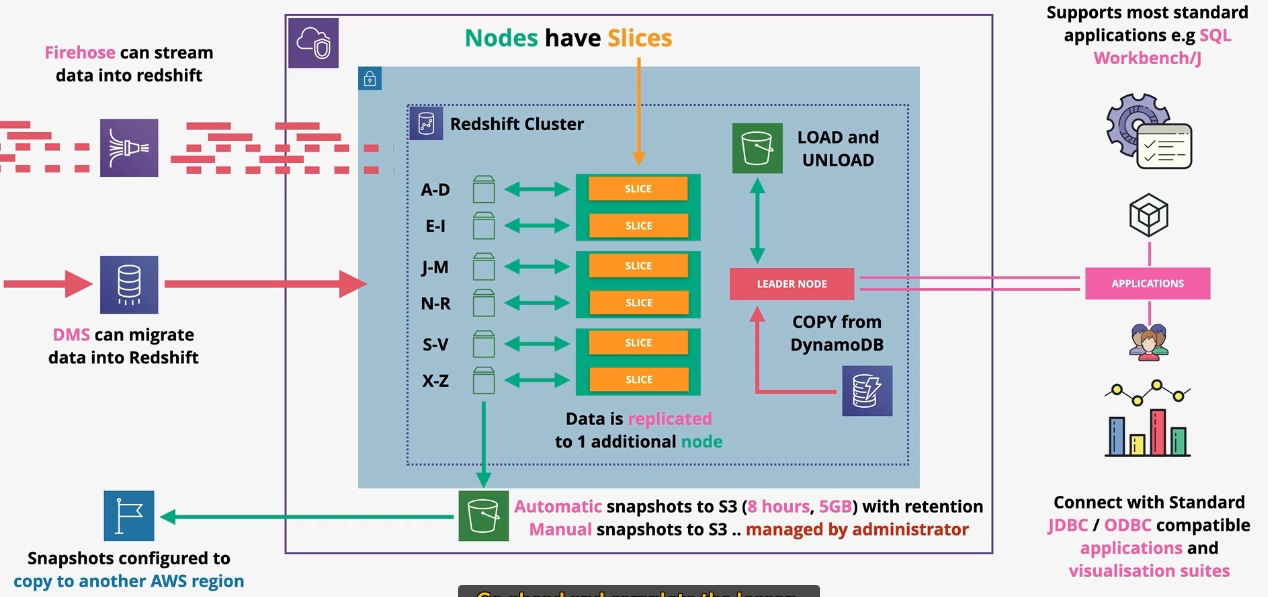
Redshift Resilience and Recovery
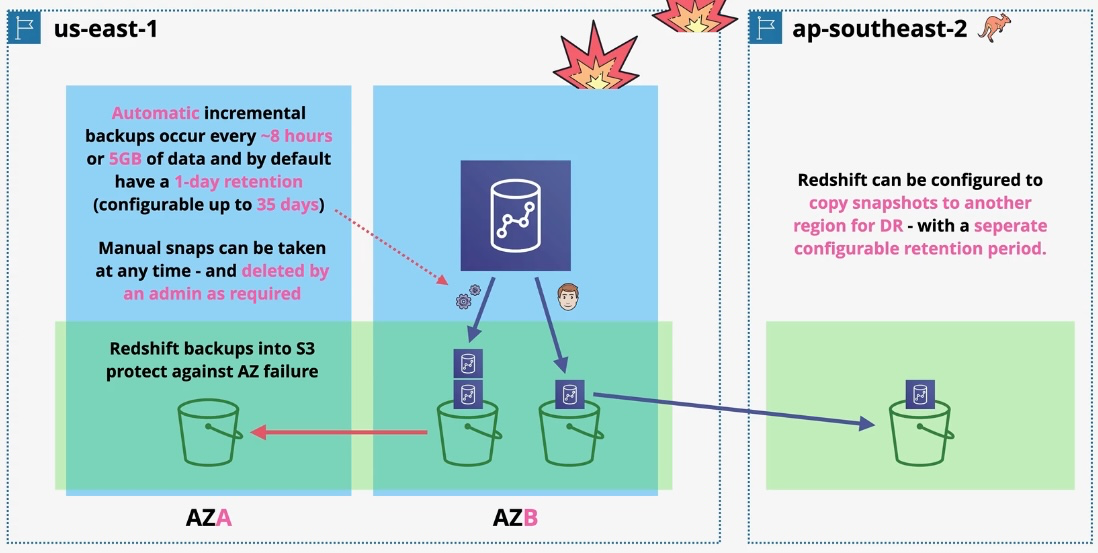
🤖Machine Learning📘
Amazon Comprehend
Amazon Comprehend is a natural-language processing (NLP) service that uses machine learning to uncover valuable insights and connections in text.
- Natural Language Processing (NLP)
- Input = Document (conceptually text)
- Output = Entities, phrases, language, PII, sentiments
- Pre-trained models or custom
- Real-time analysis
- Async jobs for larger workloads
- Console & CLI, interactive, or use APIs to build into applications
Amazon Kendra
Amazon Kendra is an intelligent search service powered by machine learning (ML).
- Intelligent search service
- designed to mimic interacting with a human expert
- Supports wide range of question types
- Factoid - Who, what, where
- Descriptive - How do I get my cat to stop being a jerk?
- Keyword - What time is the keynote address (address can have multiple meaning) - Kendra helps determine intent
Key Concepts
- Index - searchable data organized in an efficient way
- Data Source - Where your data lives, Kendra connects and indexes from this location
- S3, Confluence, Google Workspace, RDS, OneDrive, Salesforce, Kendra Web Crawler, Workdocs, FSx
- Synchronize with index based on a schedule
- Documents - Structured (FAQs), Unstructured (HTML, PDFs, text)
- Integrates with AWS Services (IAM, Identity Center (SSO), …)
Amazon Lex
Amazon Lex is a fully managed artificial intelligence (AI) service with advanced natural language models to design, build, test, and deploy conversational interfaces in applications.
- Backend-service
- Text or voice conversational interfaces
- Powers the Alexa voice
- Automatic speech recognition (ASR) - speech to text
- Natural Language Understanding (NLU) - Intent
- Build understanding into your application
- Scales, integrates, quick to deploy, Pay as you go pricing
- Chatbots, voice assistants, Q&A Bots, Info/Enterprise Bots
Concepts
- Lex provides BOTS, conversing in 1+ languages
- Intent - an action the user wants to perform
- order a pizza, milkshake or fries
- samle utterances - ways in which an intent might be said “can I order” “I want to order” “Give me a”
- How to fulfil the intent - lambda integration
- Slot (parameters… e.g. Size small/medium/large, crust normal or cheesy)
Amazon Polly
Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk, and build entirely new categories of speech-enabled products.
- Converts text into “life-like” speech
- Text (language) → Speech (Language) NO translation
- Standard RRS = Concatenative (phonemes)
- Neutral TTS = phonemes → spectrograms → vocoder → audio
- MUCH more human/natural sounding but more complex
- Output formats - MP3, Ogg Vorbis, PCM
- Speech Synthesis Markup Language (SSML)
- additional control over how Polly generates speech
- emphasis
- pronunciation
- whispering
- “newscaster” speaking style
Amazon Rekognition
Amazon Rekognition offers pre-trained and customizable computer vision (CV) capabilities to extract information and insights from your images and videos.
- Deep learning image and video analysis
- Identify objects, people, text, activities, content moderation, face detection, face analysis, face comparison, pathing & much more
- Per image or per minute (video) pricing
- Integrates with applications & event-driven
- Can even analyse live video streams - kinesis video streams
Amazon Textract
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. It goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables
- Detect and analyze text contained in input documents
- Input = JPEG, PNG, PDF or TIFF
- Output = Extracted text, structure and analysis
- Most documents = Synchronous (real-time)
- Large documents (big PDFs) = Asynchronous
- Pay for usage - custom pricing for large volume
Use Cases
- Detection of text
- relationship between text
- metadata i.e. where text occurs
- Document analysis (names, address, birthdate)
- Receipt analysis (prices, vendor, lite items, dates)
- Identity documents (abstract fields… i.e DocumentID)
Amazon Transcribe
Amazon Transcribe is an automatic speech recognition service that uses machine learning models to convert audio to text. You can use Amazon Transcribe as a standalone transcription service or to add speech-to-text capabilities to any application.
- Automatic Speech Recognition (ASR) service
- Input = Audio, Output = Text
- Language customization, Filters for privacy, audience-appropriate language, speaker identification
- Custom vocabularies and language models
- Pay as you use - per second of transcribed audio
Use Cases
- Full text indexing of audio - allow searching
- Meeting notes
- Subtitle/captions & transcripts
- Call analytics (characteristics, summarization, categories and sentiment)
- Integration with other apps / AWS ML services
Amazon Translate
Amazon Translate is a neural machine translation service that delivers fast, high-quality, affordable, and customizable language translation.
- Text translation service - ML based
- Translates text from native language to other languages - one word at a time
- Encoder reads source → semantic representation (meaning)
- Decoder reads meaning → writes target language
- Attention mechanisms ensure meaning is translated
- Auto detect source text language
Use Cases
- Multilingual user experience
- meeting notes, posts, communications, articles
- emails, in-game chat, customer live chat
- Translate incoming data (social media/news/communications)
- Language-independence for other AWS services
- comprehend, transcribe, polly, data stored in S3, RDS, DDB
- Commonly integrates with other services/apps/platforms
Amazon Forecast
Amazon Forecast is a fully managed service that uses statistical and machine learning algorithms to deliver highly accurate time-series forecasts.
- Forecasting for time-series data
- retail demand, supply chain, staffing, energy, server capacity, web traffic
- Import historical & related data
- understands what’s normal
- Output = forecast and forecast explainability
- Web Console (visualization), CLI, APIs, Python SDK
Amazon Fraud Detector
Amazon Fraud Detector is a fully managed fraud detection service that automates the detection of potentially fraudulent activities online. These activities include unauthorized transactions and the creation of fake accounts. Amazon Fraud Detector works by using machine learning to analyze your data.
- Fully managed Fraud Detection service
- new account creations, payments, guest checkout
- Upload historical data, choose model type
- Online Fraud: Little historical data e.g. new customer account
- Transaction Fraud: Transactional history, identifying suspect payments
- Account Takeover: Identify phishing or another social based attack
- Things are scored - Rules/Decision logic allow you to react to a score based on business activity
Amazon SageMaker
Amazon SageMaker is a fully managed machine learning service. With SageMaker, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment.
- Collection of ML services
- Fully managed ML service
- Fetch, Clean, Prepare, Train, Evaluate, Deploy, Monitor/Collect
- Sage Maker Studio - Build, train, debug and monitor models - IDE for ML lifecycle
- Sage Maker Domain - EFS Volume, Users, Apps, Policies, VPCs - isolation
- Containers - Docker containers deployed to ML EC2 instance - ML environments (OS, Libs, Tooling)
- Hosting - Deploy endpoints for your models
- SageMaker has no cost - the resources it create do
- Complex pricing!
📍AWS Local Zones
Key Concepts
- “1” zone - so no built in resilience
- Think of them like an AZ, but near your locatoin
- They are closer to you - so lower latency
- Not all products support them - many are opt in w/ limitations
- DX to a local zone IS support (extreme performance needs)
- Utilize parent region - i.e. EBS Snapshots are TO parent
- Use Local zones when you need THE HIGHEST performance ❗
AWS w/o Local Zones
AWS w/ Local Zones
📝 Exam
General AWS Exam Technique
- 25% easy Q’s
- 50% medium Q’s
- 25% hard Q’s
Phases
Consider it three phases
- Phase 1: Easy questions. Do these first.
- Phase 2: Whatever questions is left, go through. Identify hard questions and mark these for later.
- Phase 3: In remaining time focus on remaining hard questions. Depending on time, focus or guess.
Exam Technique
- If it’s your first exam, assume you will run out of time
- The way to succeed is to be efficient
- 2 minutes to read Q, Answers and make a decision
- Don’t guess until the end - later questions may remind you of something important from earlier
- Use the mark for review!! ❗
- Take ALL the practice tests you can
- aim for 90%+ before you do the real exam
Question Technique
If you follow a set, logical process of identifying the key elements of questions, removing word fluff (duplicated irrelevant wording) and identifying any self-eliminating answers you can reduce your cognitive load in the exam, and improve your accurate questions per minute rate.
- Questions are 1-2 lines of preamble (scenario)
- Then the question itself
- 4-5 answers - multi choice or multi-select
- At the associate level - generally answer is simple right and wrong
- Occasionally “most suitable” from some right answers
- There are generally 1 or 2 answers which can be excluded
- locate those first
- Most questions have an overall criteria or restriction
- Cost effective
- Best Practice Security - Do what AWS want you to do - EC2 instance role to give access
- Highest Performance
- Direct-connect > Site-to-site VPN
- Timeframe
- Try and eliminate any crazy answers
- Find what matters in the question
- Highlight and remove any question fluff
- Identify what matters in the answers
- Eliminate any bad answers now you’ve read the question
- Ideally - what remains is correct
- worst case, quickly select between what remains
- DON’T PANIC - mark for review and come back later